MSAdapter,一款高效迁移PyTorch代码到MindSpore生态的适配工具
2020年前后,国产深度学习框架飞速发展,同年有四个国产框架开源,MindSpore便是其中之一。然而因国产框架发展较晚,生态还未建立起来,推广国产框架生态变得异常艰难。从2016-2023年Papers with Code里各框架使用占比可以看到,PyTorch占有着主导的地位。

为了帮助用户高效迁移PyTorch代码到MindSpore生态,鹏城实验室和华为联合开发的一款MindSpore生态适配工具——MSAdapter。它能帮助用户高效使用中国算力网——智算网络的昇腾算力,且在不改变原有PyTorch用户使用习惯下,将代码快速迁移到MindSpore生态上。
MSAdapter的API完全参照PyTorch设计,用户仅需少量修改就能轻松地将PyTorch代码高效运行在昇腾上。目前MSAdapter已经适配torch、torch.nn、torch.nn.function、torch.linalg等800+接口;全面支持torchvision;并且在MSAdapterModelZoo中验证了70+主流PyTorch模型的迁移。
MSAdapter已在OpenI启智社区开源,社区为大家提供了普惠NPU算力资源,欢迎大家使用。
代码仓地址:https://openi.pcl.ac.cn/OpenI/MSAdapter。
资源地址:https://openi.pcl.ac.cn/OpenI/MSAdapter/modelarts/notebook/create。
MSAdapter整体设计
为匹配用户习惯,MSAdapter设计目的是在用户不感知的情况下,能适配PyTorch代码运行在昇腾(Ascend)设备上。MSAdapter以PyTorch的接口为标准,为用户提供一套和PyTorch一样(接口和功能完全一致)的中高阶模型构建接口和数据处理接口。图2展示了MSAdapter的层次结构。其特点如下:
-
轻量化封装
-
接口和功能与PyTorch完全映射
-
PyTorch代码少量修改可在Ascend运行
-
支持MindSpore原生接口
-
高效性能

MSAdapter快速入门
1、安装MSAdapter
通过pip安装
pip install msadapter通过源码安装
git clone https://git.openi.org.cn/OpenI/MSAdapter.git
cd MSAdapter
python setup.py install
2、使用MSAdapter
下面以AlexNet模型为例,训练CIFAR10数据集的PyTorch代码转到MSAdapter代码,完整的代码可以从MSAdapterModelZoo获取(https://openi.pcl.ac.cn/OpenI/MSAdapterModelZoo/src/branch/master/official/cv/alexnet)
2.1 修改导入包
# PyTorch 导入包
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.transforms.functional import InterpolationMode
import argparse
## MSAdapter 导入包
import msadapter.pytorch as torch
import msadapter.pytorch.nn as nn
from msadapter.pytorch.utils.data import DataLoader
from msadapter.torchvision import datasets, transforms
from msadapter.torchvision.transforms.functional import InterpolationMode
import mindspore as ms
import argparse2.2 数据处理(一致)
# PyTorch 数据处理
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616])
])
# MSAdapter 数据处理
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616])
])2.3 模型定义(一致)
# PyTorch 模型定义
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 10) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, (11, 11), (4, 4), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(64, 192, (5, 5), (1, 1), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(192, 384, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(384, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
return self._forward_impl(x)
def _forward_impl(self, x):
out = self.features(x)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
# MSAdapter 模型定义
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 10) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, (11, 11), (4, 4), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(64, 192, (5, 5), (1, 1), (2, 2)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
nn.Conv2d(192, 384, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(384, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, (3, 3), (1, 1), (1, 1)),
nn.ReLU(),
nn.MaxPool2d((3, 3), (2, 2)),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
return self._forward_impl(x)
def _forward_impl(self, x):
out = self.features(x)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.classifier(out)
return out2.4 模型训练(训练部分自定义)
# PyTorch 模型训练
def train(config_args):
train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform)
train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
epochs = config_args.epoch
net = AlexNet().to(config_args.device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
net.train()
print("begin training ......")
for i in range(epochs):
for X, y in train_data:
X, y = X.to(config_args.device), y.to(config_args.device)
out = net(X)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("---------------------->epoch:{}, loss:{:.6f}".format(i, loss))
torch.save(net.state_dict(), config_args.save_path)
# MSAdapter 模型训练
def train(config_args):
train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform)
train_data = DataLoader(train_images, batch_size=128, shuffle=True, num_workers=2, drop_last=True)
epochs = config_args.epoch
net = AlexNet().to(config_args.device)
criterion = nn.CrossEntropyLoss()
optimizer = ms.nn.SGD(net.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=0.0005)
loss_net = ms.nn.WithLossCell(net, criterion)
train_net = ms.nn.TrainOneStepCell(loss_net, optimizer)
net.train()
print("begin training ......")
for i in range(epochs):
for X, y in train_data:
res = train_net(X, y)
print("---------------------->epoch:{}, loss:{:.6f}".format(i, res.asnumpy()))
torch.save(net.state_dict(), config_args.save_path)3、Ascend环境运行
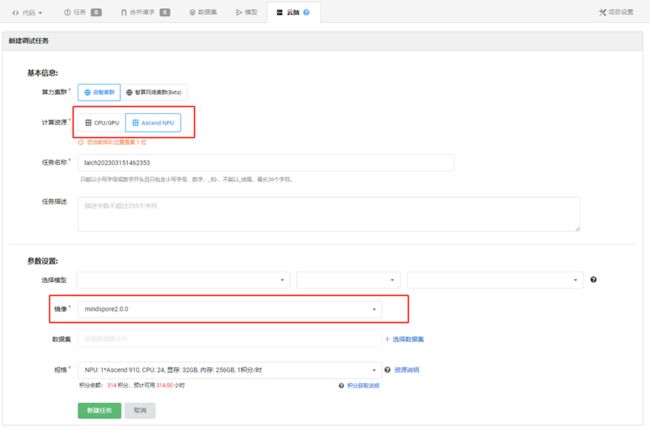
目前启智平台对外提供了普惠Ascend算力和MindSpore2.0镜像,用户可以在自己的项目上使用这些资源。
加入MSAdapter SIG
MSAdapter SIG汇聚了一大批MSAdapter开发者和用户,您可以从群里直接获得使用指导。欢迎加入我们一起开发和使用,提出宝贵意见!
