OPENMP学习笔记(1)——简介,模型,运行
OPENMP学习笔记(1)——简介,模型,运行
简介:
OpenMP的英文全称是Open Multiprocessing,一种应用程序接口(API,即Application Program Interface),是一种单进程多线程并行的实现和方法,也可以认为是共享存储结构上的一种编程模型,可用于共享内存并行系统的多线程程序设计的一套指导性注释(Compiler Directive)。
在链接可以到官网看5.0以及4.5版本的官方文档以及示例。
在项目程序已经完成好的情况下不需要大幅度的修改源代码,只需要加上专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。
OpenMP支持的语言包括C/C++、Fortran;而支持OpenMP的编译器VS、gcc、clang等都行。可移植性也很好:Unix/Linux和Windows
OpenMP缺点:
1:作为高层抽象,OpenMp并不适合需要复杂的线程间同步和互斥的场合;
2:另一个缺点是不能在非共享内存系统(如计算机集群)上使用。在这样的系统上,MPI使用较多
模型:
内存共享模型:OpenMP是专为多处理器/核,共享内存机器所设计的。底层架构可以是UMA和NUMA。即(Uniform Memory Access和Non-Uniform Memory Access)

注意:OpenMP并行性本身仅限于单个节点。
在高性能计算(HPC)应用中,OpenMP与MPI相结合实现分布式内存并行。这通常被称为混合并行编程。
(1)OpenMP用于每个节点上的计算密集型工作。
(2)MPI用于实现节点之间的通信和数据共享。
这允许在集群的整个规模上实现并行性。
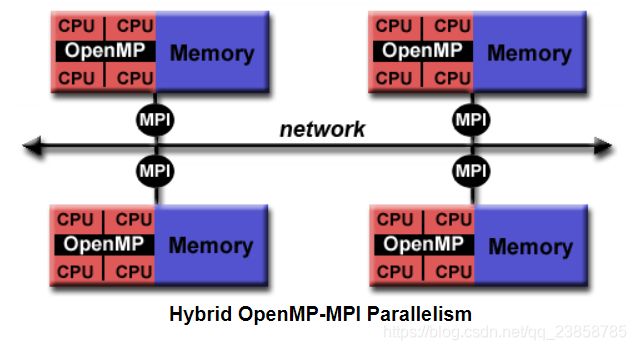
基于线程的并行化:
1)OpenMP程序通过使用线程来完成并行化;
2)线程是可由操作系统调度的最小处理单元,其特点是可以安排自主运行的子程序;
3)线程存在于单个进程的资源中,如果没有这个进程,那么线程也就不存在了;
4)通常,线程数与机器处理器/内核的数量相匹配,但是线程的实际使用也取决于具体的应用程序。
显式并行化:
1)OpenMP是一个显式的(而不是自动的)编程模型,为编程者提供了对并行化的完全控制;
2)并行化可以简单到仅仅为一段串行程序添加几条编译器指令
3)或者复杂到插入子程序,以建立多层次的并行机制、锁甚至嵌套锁。
Fork-Join模型

另一种图示:

openMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
过程:
(1)所有的OpenMP程序都从一个单个进程——master thread开始。主线程串行执行,直到遇到第一个并行区域。
(2)Fork:主线程将创建一组并行线程。
(3)并行区域内的代码被用大括号包围起来,然后在多个并行线程上被并行执行。
(4)Join:当并行线程执行完成并行区域内的代码之后,它们进行同步并且自动结束,只剩下主线程。
(5)并行区域的数量以及并行线程的数量都可以是任意的
基于编译器指令
嵌套并行
动态线程
输入输出 (I/O)
内存模型:频繁更新(flush)
OpenMP API
OpenMP三类组件: OpenMP API包含三个不同的组件:
编译器指令(44个);
运行时库函数(35个);
环境变量(13个)。
编译器指令
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。
API函数(运行时库函数)
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为。
函数库链接

环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量:
OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
不同编译器需要使用的编译器标识
所有的LC编译器都需要你使用适当的编译器标识来“打开”OpenMP的编译选项。下面的表格给出了每种编译器需要使用的编译器标识。
常用:
| 编译器平台 | 编译器指令 | openmp标识 |
|---|---|---|
| GNU | gcc | -fopenmp |
| Clang | clang | -fopenmp |
具体如下:

vs使用:
点击项目->属性,打开openmp支持,否则都是串行,显示Thread0!
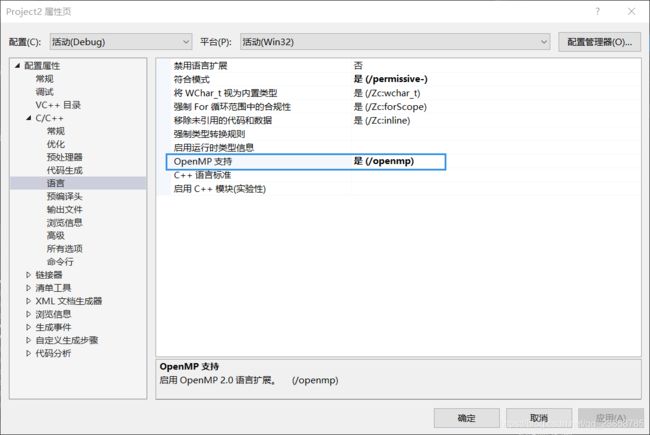
简单例子
串行
#include
#include
using namespace std;
int main()
{
cout<<"串行化程序"< 
omp并行
要加上#include
#include
#include
using namespace std;
int main()
{
cout<<"并行化程序"< ![]()
通过子句num_threads显式控制创建的线程数:
#include
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel num_threads(6)
{
cout << "Test" << endl;
}
system("pause");
}

程序中显式定义了6个线程,所以parallel后的语句块分别被执行了6次。第二行的空行是由于每个线程都是独立运行的,在其中一个线程输出字符“Test”之后还没有来得及换行时,另一个线程直接输出了字符“Test”。
OpenMP效率提升以及不同线程数效率对比
#include
#include"omp.h"
using namespace std;
void test()
{
for (int i = 0; i < 80000; i++)
{
}
}
void main()
{
float startTime = omp_get_wtime();
//指定2个线程
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("指定 2 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定4个线程
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 4 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定8个线程
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 8 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定12个线程
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 12 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP多线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
system("pause");
}

使用OpenMP优化后的程序执行时间是原来的1/4左右,并且并不是线程数使用越多效率越高,一般线程数达到4~8个的时候,不能简单通过提高线程数来进一步提高效率。
命令行编译
(测试为manjiaro,archlinux的一种)
#include
#include
#include
int main()
{
int nthreads, tid;
/* Fork a team of threads giving them their own copies of variables */
#pragma omp parallel private(nthreads, tid)
{
/* Obtain thread number */
tid = omp_get_thread_num();
printf("Hello World from thread = %d\n", tid);
/* Only master thread does this */
if (tid == 0)
{
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
} /* All threads join master thread and disband */
return 0;
}
加上-fopenmp编译
g++ test.cpp -o test -fopenmp
gcc test.cpp -o test -fopenmp -lstdc++
//上述两种方式都可以
./test
