clickhouse case when 写法及clickhouse常用函数汇总全网最详细
前言
(1)clickhouse查看某个数据库的某个表有多少字段
SELECT database AS `数据库名`,table AS `表名`, name AS `列名`,type AS `类型`,default_expression AS `默认值`, comment AS `字段说明` FROM system.columns WHERE database='dbName' and `table` ='tableName' #clickhouse查看某个数据库的某个表有多少字段
(2)查询某个数据库下所有表名
SELECT DISTINCT table AS `表名` FROM system.columns WHERE database=‘dbname’
SELECT DISTINCT table AS `表名` FROM system.columns WHERE database=currentDatabase() #当前数据库
(3)判断某个数据库某个表是否已经存在
select count(*) FROM system.columns WHERE database=currentDatabase() and "table" ='tableName' #大于0存在
select count(*) FROM system.columns WHERE database='defualt' and "table" ='tableName'#大于0存在
(4)查看数据库容量
select
sum(rows) as row,--总行数
formatReadableSize(sum(data_uncompressed_bytes)) as ysq,--原始大小
formatReadableSize(sum(data_compressed_bytes)) as ysh,--压缩大小
round(sum(data_compressed_bytes) / sum(data_uncompressed_bytes) * 100, 0) ys_rate--压缩率
from system.parts
(5)查看表的各个指标
select database,
table,
sum(bytes) as size,
sum(rows) as rows,
min(min_date) as min_date,
max(max_date) as max_date,
sum(bytes_on_disk) as bytes_on_disk,
sum(data_uncompressed_bytes) as data_uncompressed_bytes,
sum(data_compressed_bytes) as data_compressed_bytes,
(data_compressed_bytes / data_uncompressed_bytes) * 100 as compress_rate,
max_date - min_date as days,
size / (max_date - min_date) as avgDaySize
from system.parts
where active
and database = 'default'
and table = 'user'
group by database, table
select
database,
table,
formatReadableSize(size) as size,
formatReadableSize(bytes_on_disk) as bytes_on_disk,
formatReadableSize(data_uncompressed_bytes) as data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) as data_compressed_bytes,
compress_rate,
rows,
days,
formatReadableSize(avgDaySize) as avgDaySize
from
(
select
database,
table,
sum(bytes) as size,
sum(rows) as rows,
min(min_date) as min_date,
max(max_date) as max_date,
sum(bytes_on_disk) as bytes_on_disk,
sum(data_uncompressed_bytes) as data_uncompressed_bytes,
sum(data_compressed_bytes) as data_compressed_bytes,
(data_compressed_bytes / data_uncompressed_bytes) * 100 as compress_rate,
max_date - min_date as days,
size / (max_date - min_date) as avgDaySize
from system.parts
where active
and database = 'default'
and table = 'user'
group by
database,
table
)
(6)查看表分区
select partition
from system.parts
where active
and database = 'default'
and table = 'user'
(7)跟踪分区
SELECT database,
table,
count() AS parts,
uniq(partition) AS partitions,
sum(marks) AS marks,
sum(rows) AS rows,
formatReadableSize(sum(data_compressed_bytes)) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100.,2) AS percentage
FROM system.parts
WHERE active
and database = 'default'
and table = 'user'
GROUP BY database, table
(8)检查数据大小
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS tc,
formatReadableSize(sum(data_uncompressed_bytes)) AS tu,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100,2) AS ratio
FROM system.columns
WHERE database = 'default'
and table = 'user'
GROUP BY table
ORDER BY sum(data_compressed_bytes) ASC
(9)查看表中列的数据大小
SELECT column,
any(type),
sum(column_data_compressed_bytes) AS compressed,
sum(column_data_uncompressed_bytes) AS uncompressed,
sum(rows)
FROM system.parts_columns
WHERE database = 'default'
and table = 'user'
AND active
GROUP BY column
ORDER BY column ASC
(10)查看当前查询的语句
select
query_id,read_rows,total_rows_approx,memory_usage,
initial_user,initial_address,elapsed,query
from system.processes order by read_rows desc;
SHOW PROCESSLIST
select count(*) from system.mutations where database = 'DBNAME' and is_done =0;
KILL MUTATION WHERE 1=1 AND database = 'DBNAME' AND table = ' TABLENAME';
kill query where query_id='query_id查询ID'; #删掉某个查询
一、clickhouse case when 写法
select (case when 1=1 and 2=2 or 1!=2 then 1 else 0 end )as t


二、if:想象成编程语言中的三元表达式即可
SELECT number, if(number < 5, 'less than 5', 'greater than or equal to 5')
FROM (SELECT number FROM numbers(10));

三、三元表达式判断
– 另外 ClickHouse 本身也支持三元表达式,底层依旧会转成 if
SELECT number, number < 5 ? 'less than 5' : 'greater than or equal to 5'
FROM (SELECT number FROM numbers(10));

四、CASE WHEN 实例
SELECT number, CASE WHEN number < 5 THEN 'less than 5' ELSE 'greater than or equal to 5' END
FROM (SELECT number FROM numbers(10));

五、multiIf函数
我们看到底层转化成了 multiIf,那么这个 multiIf 是做什么的呢?首先 if 函数的参数如下:
if(cond, then, else)
而 multiIf 函数的参数如下:
multiIf(cond1, then1, cond2, then2, cond3, then3, ..., else)
所以从名字上也能看出来 multiIf 是干什么的,if 只能有一个条件,相当于编程语言中的 if … else;而 multiIf 可以接收多个条件,相当于编程语言中的 if … else if … else if … else。
multiIf(number < 5, 'less than 5', number = 5, 'equal to 5', 'greater than 5')
等价于
SELECT number,
CASE WHEN number < 5 THEN 'less than 5' WHEN number = 5 THEN 'equal to 5' ELSE 'greater than 5' END
FROM (SELECT number FROM numbers(10));
六、附加额外判断
a < b 等价于 less(a, b)
a = b 等价于 equals(a, b)
a > b 等价于 greater(a, b)
a <= b 等价于 lessOrEquals(a, b)
a >= b 等价于 greaterOrEquals(a, b)
a != b 等价于 notEquals(a, b)
七、数学函数
e:一个函数,调用之后返回底数 e
SELECT e();

pi:一个函数,调用之后返回圆周率 π
SELECT pi();

exp:返回 e 的 x 次方
SELECT exp(1), exp(2);
除了 exp 之外,还有 exp2 返回 2 的 x 次方,exp10 返回 10 的 x 次方。
SELECT exp2(2), exp10(2);

log、ln:两者是等价的,都是以自然对数为底
SELECT log(e()), ln(e() * e());
同理还有 log2 以 2 为底,log10 以 10 为底。
SELECT log2(8), log10(1000);

sqrt:返回一个数的平方根
SELECT sqrt(9);
cbrt:返回一个数的立方根
SELECT cbrt(27);
pow:计算 x 的 y 次方
SELECT pow(3, 4); #结果81
sin、cos、tan:计算正弦值、余弦值、正切值
asin、acos、atan:计算反正弦值、反余弦值、反正切值
sinh、cosh、tanh:计算双曲正弦值、双曲余弦值、双曲正切值
asinh、acosh、atanh:计算反双曲正弦值、反双曲余弦值、反双曲正切值
atan2:atan 的增强版,具体细节可以百度或者谷歌
hypot:给定两个直角边,计算斜边长度,等于 

sign:小于 0 返回 -1、等于 0 返回 0、大于 0 返回 1

floor、ceil(或者 ceiling):返回小于等于 x 的最大整数、大于等于 x 的最小整数,注意:说返回整数其实不太准确,因为返回的仍是 Float64
SELECT floor(3.14), ceil(3.14);
SELECT floor(3.14, 1), ceil(3.14, 2), ceiling(3.14, 3);

truncate、trunc:截断小数点
SELECT trunc(3.14), trunc(-2.17); #truncate、trunc:截断小数点
SELECT trunc(3.14, 1), trunc(-2.17, 1); #仍然可以选择保留位数

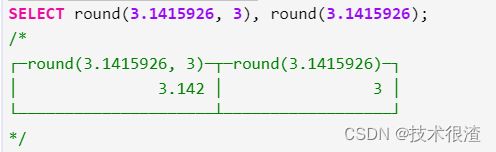
round:保留指定位数的小数
SELECT round(3.1415926, 3), round(3.1415926); #不指定位数,将一位都不保留
注意:ClickHouse 中的 round 还有一种特殊用法,那就是对整数四舍五入。
– 当指定为负数时,表示对整数或者小数点前面的进行四舍五入
– -1 表示针对最后一位,所以 round(222, -1) 得到的结果是 220,round(228, -1) 得到的结果是 230
SELECT round(222, -1), round(228, -1);

– -2 表示针对最后两位,所以 round(-350, -2) 得到的结果是 -400,round(349, -2) 得到的结果是 300
– 因为 50 达到了 100 的一半,49 没有达到 100 的一半
SELECT round(-350, -2), round(349, -2);

– -3 表示针对最后三位,所以 round(499, -3) 得到的结果是 0,round(500, -3) 得到的结果是 1000
– 因为 499 没有达到 1000 的一半,500 达到了 1000 的一半
SELECT round(499, -3), round(500, -3);

roundToExp2:将数值转为某个最接近的 2 的整数次幂,比如 roundToExp2(33) 得到的就是 32,因为 32 是 2 的 5 次幂;roundToExp2(31) 得到的就是 16,因为 16 是 2 的 4 次幂
SELECT roundToExp2(33), roundToExp2(31), roundToExp2(1), roundToExp2(-11);

roundAge:如果一个数值小于 18,返回其本身;否则将其转成 18、25、35、45、55 当中与之最接近的一个值,很明显这个函数是针对 Yandex 公司的业务而专门设计的
SELECT roundAge(15), roundAge(20), roundAge(29), roundAge(38), roundAge(1000);

roundDown:将一个数值四舍五入到某个数组中与之最接近的值,如果数值小于数组中的最小值,那么等于最小值
WITH [18, 25, 35, 45, 55] AS arr
SELECT roundDown(15, arr), roundDown(20, arr), roundDown(29, arr), roundDown(38, arr), roundDown(1000, arr)

rand、rand32:生成一个 UInt32 伪随机数 rand64:生成一个 UInt64 伪随机数
SELECT rand32(), rand64();

randConstant:生成一个 UInt32 伪随机数,但在一次查询中多次调用得到的结果一样
SELECT rand32(), randConstant() FROM numbers(3);

八、常见编码函数
char:将 ASCII 码转成对应的字符,可以同时接收多个 ASCII 码
SELECT char(97), char(97, 98, 99);

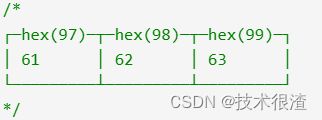
hex:将整型用 16 进制表示
SELECT hex(97), hex(98), hex(99);
hex 除了接收整型之外,还可以接收字符串,将每个字符对应的 ASCII 码用 16 进制标识
SELECT hex('abc'); # 十六进制:a -> 61, b -> 62, c->63

unhex:hex 的逆运算,但只能接收字符串
SELECT unhex('616263');

九、其他函数
hostName:返回当前 ClickHouse Server 所在节点的主机名
SELECT hostName();#getMacro:从服务器的宏配置中获取指定的值
<macros>
<name>XXX</name>
</macros>
然后即可通过 getMacro(name) 获取,当然也可以查看所有的宏。
SELECT * FROM system.macros;
fqdn:返回全限定域名,和我当前的主机名是一样的
SELECT fqdn();
basename:返回路径中最后一个 / 或者 \ 后面的部分
SELECT '/root/girls/1.csv' file_path, basename(file_path) file_name;

visibleWidth:当以文本格式向控制台输出内容时,计算出所需要的宽度,用于美化输出
SELECT visibleWidth(3.1415), visibleWidth('satori'), visibleWidth(Null);

SELECT visibleWidth([1,2,3,4,Null]), length('[1,2,3,4,Null]');

可以看到就是把内容当成纯文本,计算所占的长度
SELECT toTypeName([1, 2, 3]), toTypeName(123), toTypeName((11, '22'));

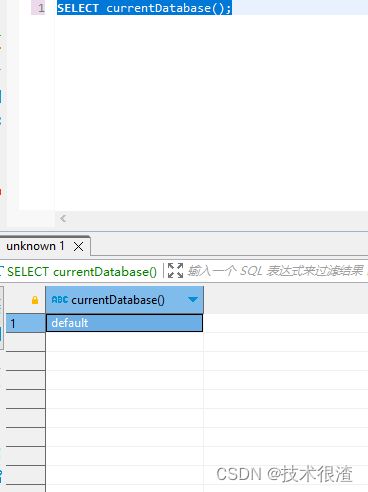
currentDatabase:获取当前所在的数据库
SELECT currentDatabase();
currentUsere:获取当前的用户
SELECT currentUser();

函数参考官方网址
https://clickhouse.com/docs/en/sql-reference/functions
十、高阶函数应用实战
先来一个完整的例子,该示例根据行为日志计算用户访问的top路径
select data, count(1) cn from (
with maxIf( c_t , cat='page_view'and act='页面浏览') as max_time, -- 目标事件时间
arraySort(
e -> e.1,
arrayFilter(x->x.1<=toUInt64OrZero(max_time),groupArray((toUInt64OrZero(c_t), (cat,act) )))
) as sorted_array,
-- 按时间排序后的数据
-- arrayPushFront( sorted_array, sorted_array[1] ) as e_arr,
arrayFilter(
(i, e,z) -> z.1 < toUInt64OrZero(max_time)
and (e > 1800000 or (z.2.1='page_view' and z.2.2='页面浏览')),
arrayEnumerate(sorted_array), arrayDifference( sorted_array.1 ),sorted_array
) as arr_indx, -- 过滤目标事件、时间差后的数据
arrayReduce('max',arr_indx) +1 as smIndx,
arrayFilter(
(e,i) -> i>=smIndx and e.1<=toUInt64OrZero(max_time) ,
sorted_array, arrayEnumerate(sorted_array)
) as data_
select u_i,
arrayFilter((x,y,i)-> i=1 or i>1 and y<>0 ,data_.2,arrayDifference(arrayEnumerateDense(data_.2)),arrayEnumerate(data_)) as data__,
arraySlice(data__,-7,7 ) as data,
-- arrayStringConcat(data,'->') as path,
hasAll(data, [ ('page_view','页面_浏览') ]) as has_way_point --路径中必须经过的点
from app.scene_tracker where c_p='PC' and length(u_i)>20
group by u_i having length(data)>1
) tab
where has_way_point=1 group by data order by cn desc limit 100
neighbor 获取某一列前后相邻的数据,第二个参数控制前后相邻的距离
示例1:
SELECT a, neighbor( a,-1 ) from (SELECT arrayJoin( [1,2,3,6,34,3,11] ) as a,'u' as b)
arrayJoin行变列,对数组进行展开操作
# 还是上面的例子
SELECT a, neighbor( a,-1 ) from (SELECT arrayJoin( [1,2,3,6,34,3,11] ) as a,'u' as b)
arraySort 对数组进行排序,降序的话用这个 arrayReverseSort
# 还是上面的例子 略作修改,可对比示例1和示例3的结果区别
SELECT a, neighbor( a,-1 ) from (SELECT arrayJoin( arraySort([1,2,3,6,34,3,11]) ) as a,'u' as b)
arrayFilter过滤出数组中满足条件的数据
# 我们只获取数组中的偶数部分
SELECT a, neighbor( a,-1 ) from (SELECT arrayJoin( arraySort(arrayFilter(x->x%2=0, [1,2,3,6,34,3,11])) ) as a,'u' as b)
arrayEnumerate 返回数组下标
SELECT arrayEnumerate( [1,2,3,6,34,3,11] )
arrayDifference计算数组中前后两个值的差值部分
SELECT arrayDifference( [1,2,3,6,34,3,11] )
arrayReduce对数组进行聚合操作,min 、max、avg 等
SELECT arrayReduce('avg', [1,2,3,6,34,3,11] )
arrayEnumerateDense标记出数组中相同的元素
SELECT arrayEnumerateDense( [1,2,3,6,34,3,11] )
arraySlice对数组进行切割 ,后面两个参数分别是切割的offset和切割长度
SELECT arraySlice( [1,2,3,6,34,3,11] , -3, 2)
# 返回:34 3
hasAny判断数组中是否包含某些值,包含其一返回1 ,否则0 ;如果判断全部包含 用hasAll
SELECT hasAny( [1,2,3,6,34,3,11] , [3,1])
arrayStringConcat 将数组元素按照给定分隔符进行拼接,返回拼接后的字符串
SELECT arrayStringConcat( [1,2,3,6,34,3,11] , '-')
arrayPushFront向数组首位置最加value ;同理向数组末尾最加为arrayPushBack
SELECT arrayPushFront( [1,2,3,6,34,3,11] , 8)
arrayPopFront移除数组下标为1的值;同理,移除数组最后一个值用arrayPopBack
SELECT arrayPopFront( [1,2,3,6,34,3,11] )
arrayWithConstant生成一个指定长度的数组
#生成长度为3 的数组
SELECT arrayWithConstant( 3, 'a')
#范围值为['a','a','a']
arrayUniq计算数组中有多少个不重复的值;如进行数组去重操作 用arrayDistinct
SELECT arrayUniq( [1,2,3,6,34,3,11])
runningDifference计算某一列前后数值的差值
select a,runningDifference(a) from (SELECT arrayJoin( [1,2,3,6,34,3,11] ) as a,'u' as b)
arrayCompact对数组内数据实现相邻去重
SELECT arrayCompact([1, 2, 2, 3, 2, 3, 3])
#返回值为 [1,2,3,2,3]