I/O模型之非阻塞IO
简介
五种IO模型
阻塞IO
非阻塞IO
信号驱动IO
IO多路转接
异步IO
代码书写
非阻塞IO
再次理解IO
什么是IO?什么是高效的IO?
为了理解后面的一个问题,我们首先要再重新理解一下什么是IO
在之前的网络介绍中,我们其实已经知道了IO的本质其实就是拷贝!

通过前面的 网络 过程中,我们所做的一切都是在把数据在拷贝来拷贝去,但是等这个部分就是由操作系统来控制的,因为把数据发送出去的前提是把数据从外设的磁盘中先把数据拷贝到发送缓冲区之中,通常IO的大部分时间的占比都是 "等" 这个行为造成的,拷贝数据其实快不了多少,拷贝速度只能依靠设备自身的配置,所以为了实现高效IO,我们只能 "等" ,这方面入手
所谓的高效,就是把 "等" 的时间占比降低,只要减少 "等" 就是在实现高效,拷贝数据只能从硬件方面入手,换设备之类的啊,硬盘用SSD的啊,这类不是我们需要考虑的,我们这里只考虑 "等"
五种IO模型
我们用钓鱼的例子理解
故事背景

分析

解释

其中阻塞式IO、非阻塞式IO、信号驱动式IO、多路转接/多路复用、异步IP统称为IO的五种模型,现在的全部的IO脱离不开这五种模型
需要注意的是,我们通常大部分使用的其实还是阻塞式IO,因为简单,但是高效就是指的多路转接/多路复用
差别

阻塞IO
阻塞IO是最常见的IO模型
阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式.
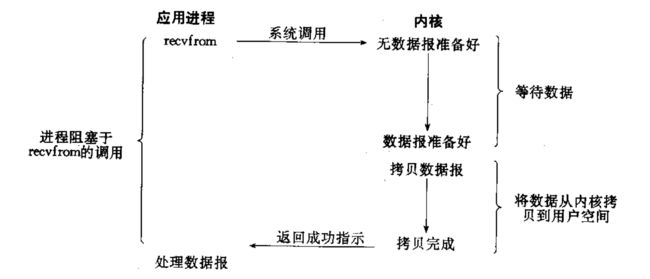
非阻塞IO
非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK错误码
非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符, 这个过程称为轮询. 这对CPU来说是较大的浪费, 一般只有特定场景下才使用.
信号驱动IO
信号驱动IO: 内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作

IO多路转接
IO多路转接: 虽然从流程图上看起来和阻塞IO类似. 实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态.

select只负责等这个行为,并且可以等多个文件描述符,是操作系统专门准备的一个接口,recvfrom只负责拷贝这个行为,也是操作系统专门准备的接口,因为这两个接口是解耦的,所以当select准备好了话,那么recvfrom就一定有数据可以拷贝,一定可以拷贝成功
并且进程\线程的消耗是比较大的,但是多路转接就不会创建多个进程\线程,于是它的成本也是比较低的
异步IO
异步IO: 由内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据)

操作系统自己等待数据,进程只是发起者,操作系统把数据都放在一个缓冲区之中,当满的时候,就直接执行进程传进来的方法就行了,进程本身不参与IO等待任何一个行为
小结
任何IO过程中, 都包含两个步骤. 第一是等待, 第二是拷贝. 而且在实际的应用场景中, 等待消耗的时间往往都远远高于拷贝的时间. 让IO更高效, 最核心的办法就是让等待的时间尽量少.
非阻塞IO
在代码接口中,我们可以通过传递参数来使用哪一种IO读取方式

不过我们通常是有一个函数可以专门来解决这方面的问题的
函数:fcntl

使用前先获取文件操作符

非阻塞选项
![]()
书写非阻塞转化函数
注意头文件的引入

阻塞式IO
如下图,0号文件描述符就是stdin,这里直接就是代表了键盘的输入了


设置为非阻塞
直接把之前写的函数用上
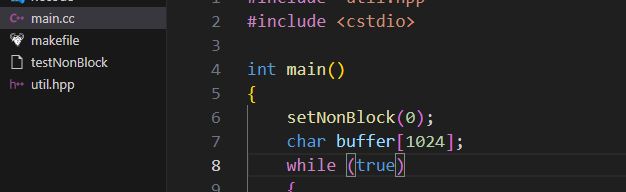
这里因为0号是键盘,而这里的1号就是屏幕,因为非阻塞所以键盘的输入是不会影响屏幕的打印的,这里的提示符一直在不停的循环打印(这里是sleep一秒的结果),0号当没有数据来的时候就会立刻返回,这样就可以做其他的事情了

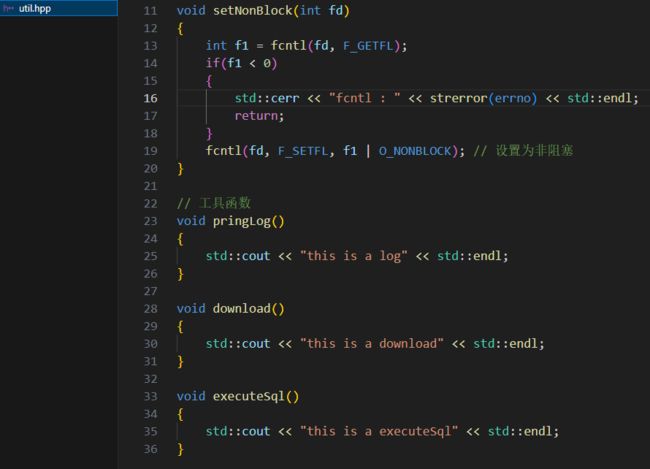
我们可以进一步封装,当没有数据来的时候,可以让它做其他的事情

在循环内不断调用这个函数

存放的函数,用来演示作用
返回值怎么区别错误
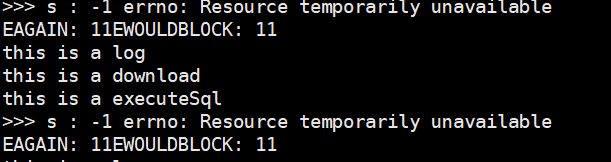
因为非阻塞,当它没有数据的时候会立即返回,当你打印出来这个值的时候,会发现是-1和错误信息返回用的同一个值,那么我们如何区别真的错误还是因为没有数据导致的返回呢?


我们再一次查看read接口的返回值就可以知道,当被返回时还会有一个动作,即,错误码被立即设置
![]()
这时候我们可以直接通过打印出错误码的形式看到是因为什么原因导致的返回,其次我们知道错误码本质上是一个个的宏,利用这些宏,我们就可以实现区分这些错误信息了

结果显示,这里给的错误信息是资源未就绪,这样我们就可以知道是什么原因了

其实在read返回值里面专门提供了这么一个宏来标识,这类的信息

可以看出来其实就是 11
![]()
![]()
为此我们这样修改代码,将空闲时候执行其他函数的行为放到,错误码被置为-1并且本身不是错误的时候执行

这种错误其实是系统调用被中断了,即当正在读取的时候,一个信号过来,直接把读取中断了,这种错误也不算是失败错误,所以再做一个判断
![]()
至此非阻塞就不再深入了
源码
makefile
testNonBlock:main.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f testNonBlockmain.cc
#include "util.hpp"
#include
#include
#include
using func_t = std::function;
// 这是一个宏函数,用来把函数加载到数组当中去的
#define INIT(v) \
do \
{ \
v.push_back(pringLog); \
v.push_back(download); \
v.push_back(executeSql); \
} while (0)
// 这是一个宏函数,用来运行函数数组里面存放的函数的
#define EXEC_OTHER(cbs) \
do \
{ \
for (auto const &cb : cbs) \
cb(); \
} while (0)
int main()
{
std::vector cbs;
INIT(cbs); // 调用宏函数,运行存放在函数数组中的函数的
setNonBlock(0);
char buffer[1024];
while (true)
{
printf(">>> "); // 提示符
fflush(stdout);
ssize_t s = read(0, buffer, sizeof(buffer) - 1);
if (s > 0)
{
buffer[s - 1] = 0;
std::cout << "echo# " << std::endl;
}
else if (s == 0)
{
std::cout << "read end" << std::endl;
break;
}
else
{
// 1.当不输入的时候,底层没有数据,这算是错误吗? 不算错误,只不过以错误的形式返回了(-1)
// 2.那么如何区别,真的错误,还是因为底层没有数据导致的错误返回?
// std::cout << "EAGAIN: " << EAGAIN << " EWOULDBLOCK: " << EWOULDBLOCK << std::endl;
if (errno == EAGAIN)
{
std::cout << "我没错, 只是没有数据" << std::endl;
EXEC_OTHER(cbs); // 宏调用,用来把函数加载到函数数组中去
}
else if(errno == EINTR)
{
continue; // 系统信号导致的返回,直接让它继续读取就行了
}
else
{
//这类表示真正的错误,在前面已经把其他非错误的错误码处理解决之后,将错误信息打印出来
std::cout << "s : " << s << " errno: " << strerror(errno) << std::endl;
break;
}
}
sleep(1);
}
} util.hpp
#pragma once
#include
#include
#include
#include
#include
// 这是一个讲文件描述符转为非阻塞式的函数
void setNonBlock(int fd)
{
int f1 = fcntl(fd, F_GETFL);
if(f1 < 0)
{
std::cerr << "fcntl : " << strerror(errno) << std::endl;
return;
}
fcntl(fd, F_SETFL, f1 | O_NONBLOCK); // 设置为非阻塞
}
// 工具函数
void pringLog()
{
std::cout << "this is a log" << std::endl;
}
void download()
{
std::cout << "this is a download" << std::endl;
}
void executeSql()
{
std::cout << "this is a executeSql" << std::endl;
} 下期预告:I/O多路转接之select