Self-Supervised Learning(2021补)
文章目录
- 引子
- X' mask input
- Next Sentence Prediction
- Downstream Tasks
- GLUE
- BERT的四个用法
-
- 情感分析
- POS标注
- 自然语言推断Natural Language Inferencee (NLI)
- 问答(抽取式)
- BERT的衍生模型
- Multi-lingual BERT
- GPT的野望(略)
发现有这一课没记录,补一下。
引子
BERT:340M的参数
GPT-3:175B
Switch Transformer:1.6T(谷歌)
由于自监督学习没有用到标签,因此是属于无监督学习的一种,类似的还有Cycle GAN也是无监督学习,但是又和原始的无监督学习有区别,因此,将他们单独拿出来。

X’ mask input

输入原本为台湾大学,然后随机选择要mask的部分,mask有两种方式:
第一种是使用特殊的token
第二种是使用随机的字符

输入经过BERT(也就是Transformer Encoder),在mask的位置也会有相应的向量输出,然后将输出的向量经过Linear变化,再通过Softmax得到一个概率分布,分布大小与词库大小相同。
我们通过最小化预测值与真实值的交叉熵来训练BERT+Linear两个部分的参数

Next Sentence Prediction
将两个句子加上开始标记[CLS]和间隔标记[SEP],然后作为输入进入BERT,仅取开始标记位置的输出向量进入Linear变化,得到一个二分类问题。如果两个句子是相邻这输出Yes,否则输出No。

Robustly optimized BERT approach(RoBERTa)一文提出这个训练方式并不好,究其原因为负样本过多,随意从文章拿两个句子凑一块作为样本对,模型只要瞎猜不是相邻句子大概率就可以蒙对。
但是在SOP: Sentence order prediction这个用在ALBERT的任务中,BERT表现还不错。
Downstream Tasks
BERT两个典型的任务就是上面介绍的文章填空以及句子顺序判断,后者效果还不咋地,因此BERT看上去用途不广,但是实际上它作为预训练模型在下游任务上有很好的用途。我们只需要少量数据就可以完成相应任务。
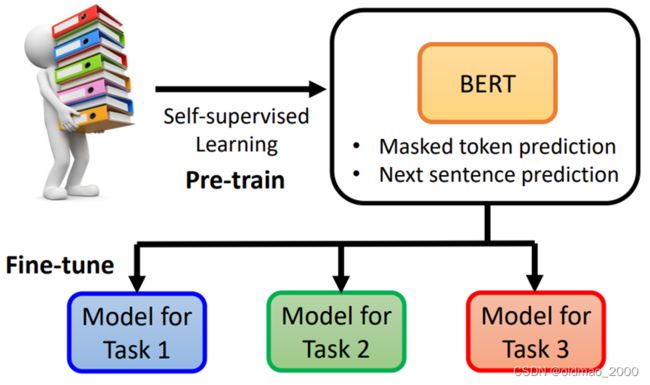
注:预训练阶段属于Unsupervised,微调阶段又需要标签数据,因此整体属于Semisupervised
GLUE
General Language Understanding Evaluation(GLUE)是包含九个测试任务的任务集,它还有中文版。
• Corpus of Linguistic Acceptability (CoLA)
• Stanford Sentiment Treebank (SST-2)
• Microsoft Research Paraphrase Corpus (MRPC)
• Quora Question Pairs (QQP)
• Semantic Textual Similarity Benchmark (STS-B)
• Multi-Genre Natural Language Inference (MNLI)
• Question-answering NLI (QNLI)
• Recognizing Textual Entailment (RTE)
• Winograd NLI (WNLI)
通常将九个模型的得分表现进行平均作为评价模型好坏的根据。
下图中,黑色线表示人类基准,蓝色虚线是模型平均得分:

BERT的四个用法
根据输入输出的类型不同大概有四种,每种选一种代表性任务来举例。这里虽然是用文字来组成序列,当然也可以替换为语音等类似的东西。
情感分析
输入:序列
输出:分类
先在句子的前面加上[CLS]标记,句子经过BERT后,只关注[CLS]标记对应的输出,将该向量丢进Linear,然后用Softmax进行分类。两个模块初始化方式如下图所示:
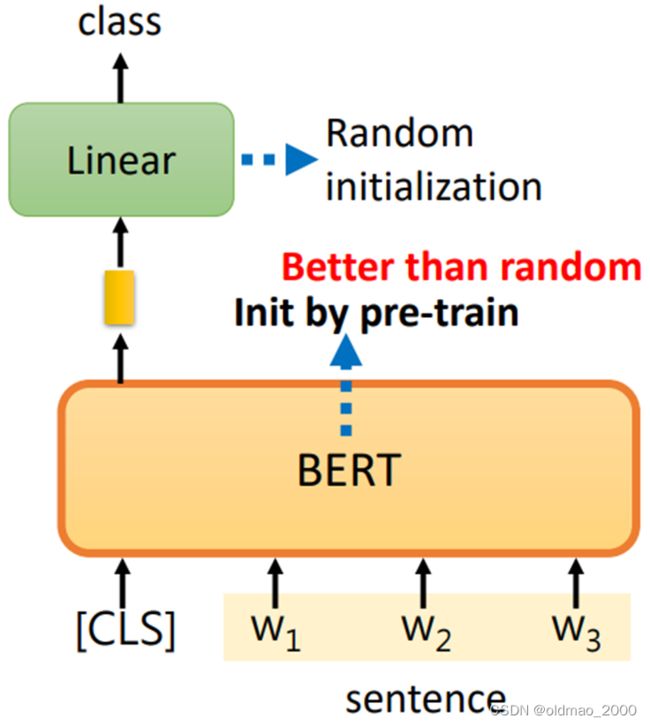
训练时需要为模型提供带有标签的句子。
使用随机初始化与预训练初始化BERT效果如下图,一共四个任务:

POS标注
输入:序列
输出:序列
先在句子的前面加上[CLS]标记,句子经过BERT后,每个单词都会有一个输出向量,每个向量分别经过Linear和Softmax,最后得到词性的分类。
| I | saw | a | saw |
|---|---|---|---|
| N | V | DET | N |
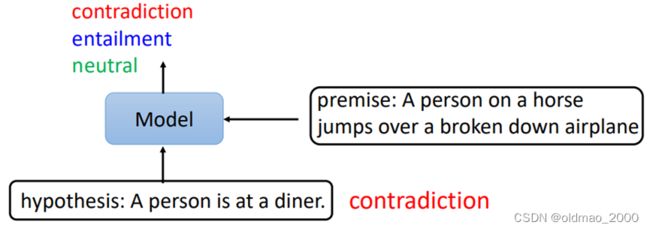
自然语言推断Natural Language Inferencee (NLI)
输入:两个序列
输出:类别
premise:前提
hypothesis:假设
模型会推断是否能从前提推断出假设。例如下图中的前提和假设就是冲突关系。
这个任务可以用在以下场景:将某个文章和评论丢进模型,模型会输出二者赞成还是反对关系。
具体是操作过程如下图,只取[CLS]标记对应的向量进行分类。

问答(抽取式)
抽取式问答是从原文中找答案。例如:
In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under g r a v i t y {\color{red}gravity} gravity. The main forms of precipitation include drizzle, rain, sleet, snow, g r a u p e l {\color{green}graupel} graupel and hail… Precipitation forms as smaller droplets coalesce via collision with other raindrops or ice crystals w i t h i n a c l o u d {\color{blue}within\ a \ cloud} within a cloud. Short, intense periods of rain in scattered locations are called “showers”.
What causes precipitation to fall?
g r a v i t y {\color{red}gravity} gravity
What is another main form of precipitation be-sides drizzle, rain, snow, sleet and hail?
g r a u p e l {\color{green}graupel} graupel
Where do water droplets collide with ice crystalsto form precipitation?
w i t h i n a c l o u d {\color{blue}within\ a \ cloud} within a cloud
输入为文章和问题的序列:
D = { d 1 , d 2 , ⋯ , d N } D=\{d_1,d_2,\cdots,d_N\} D={d1,d2,⋯,dN}
Q = { q 1 , q 2 , ⋯ , q M } Q=\{q_1,q_2,\cdots,q_M\} Q={q1,q2,⋯,qM}

输出为两个正整数 s , e s,e s,e表示答案在文章中的位置。则回答为:
A = { d s , ⋯ , d e } A=\{d_s,\cdots,d_e\} A={ds,⋯,de}
上面文章执行结果为:

具体执行过程如下图:

橙色和蓝色向量与BERT输出向量长度相同(随机初始化),先用橙色向量与文章的输出进行内积,然后过Softmax(与注意力过程很像),可以求出起始词位置,例如这里是 s = 2 s=2 s=2

再用蓝色向量与文章的输出进行内积,然后过Softmax,可以求出结束词位置,这里 e = 3 e=3 e=3
这里需要注意,不能吃太长的序列,不然内积计算部分计算量非常大。
BERT的衍生模型
BERT的训练只是提供了Encoder端的预训练,那么如何训练一个Decoder,从而形成seq2seq 模型?

如上图所示就是将输入做一些破坏 变形,期待模型仍然能够复现输出未破坏的输入。
由于对输入的处理不一样,有很多方法,使用mask的方式就称为MASS
后来还衍生出:删除、乱序、旋转、填充等方法。

后来有人把所有方法一锅端,都用在BERT上面,就称为:BART
谷歌最后来了一个大总结,把所有方法进行了比较:
Transfer Text-to-Text Transformer (T5)(67页的paper),T5在Colossal Clean Crawled Corpus(C4)语料库(大小为7TB,单卡预处理就要一年)上进行训练。
为什么BERT能做填空之外的任务?
从下图中可以看到,BERT吃句子,突出每个token对应的向量,也就是embedding,图中红色框对应的embedding是对应【大】字的向量表示。

其实学过Word2Vec都知道,意思相近的token,其向量表示位置也相近:

对于一词多义的token而言,BERT会考虑上下文给出不同语境下的向量表示,例如我们收集很多带有【果】字的句子,丢进BERT,并查看他们之间的相似度:
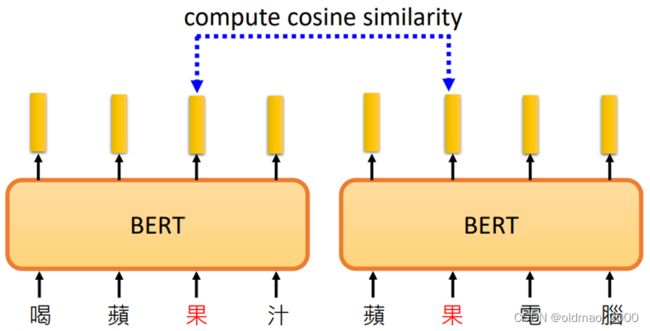
最后用热图表示:
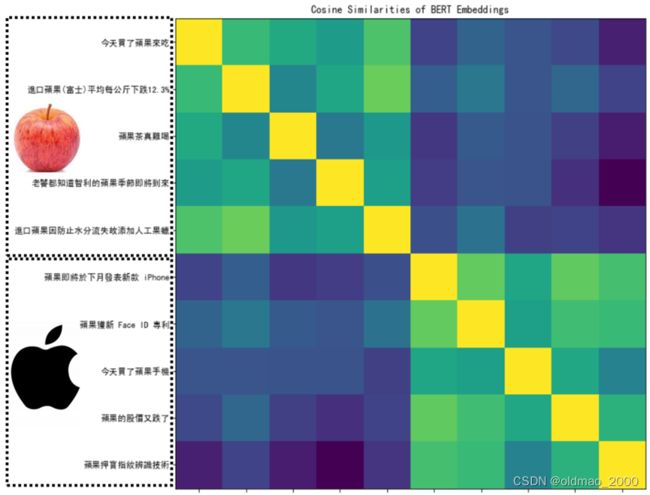
其中前面五句话中【果】与水果有关,后面五句话与手机有关。
原因在于如何根据上下文来生成对应的向量表征,BERT工作原理就是将要生成表征向量的单词盖住了,该单词的向量其实都是靠上下文的词生成的。
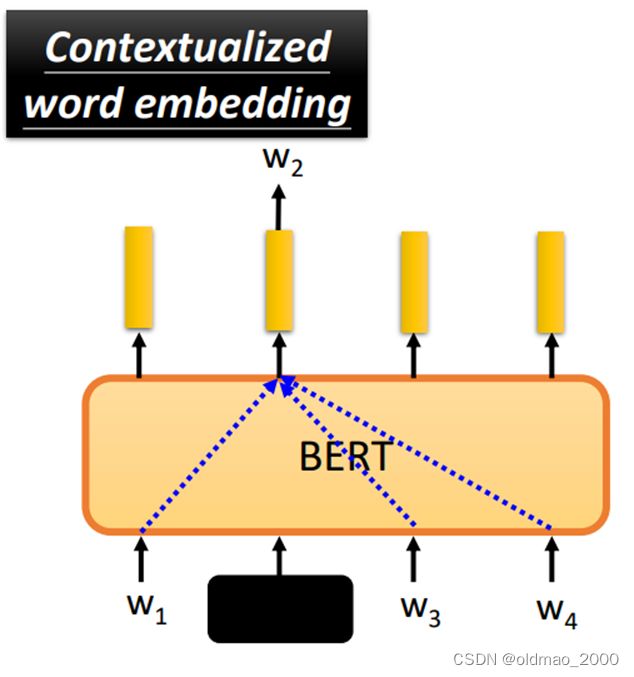
这和CBOW的原理一样,CBOW只是当时算力的限制,只用了两个Linear的模块,而BERT就有了DL的加持。

DNA中有四种碱基序列,分别为TACG,下面是一个用BERT根据DNA序列来预测DNA类别。

具体做法是先产生一个词汇表,并将碱基对应四个词汇,这4个词汇可以是随机的,对结果影响不大。
| 碱基 | 词 |
|---|---|
| A | we |
| T | you |
| C | he |
| G | she |
这样就把DNA序列转化为词汇序列,然后加[CLS],丢入BERT,取[CLS]对应的向量进行Linear和Softmax,得到分类。

以这个思路分别在蛋白质,DNA,音乐分类任务进行实验得到以下结果:

这里结果的可解释性还需要进一步研究。
Multi-lingual BERT
使用不用语言来训练BERT就称为Multi-lingual BERT。
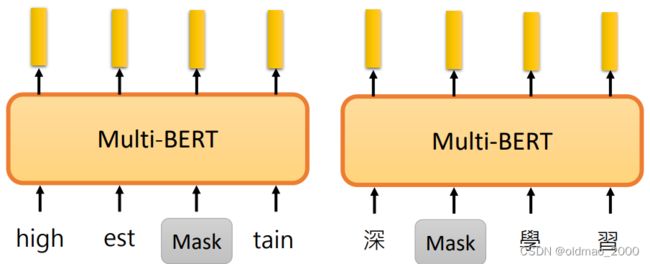
训练好的BERT在跨语言的相同任务上会有很好的表现。
例如下面的实验使用了英文的SQuAD语料库和汉语的DRCD,人类的F1标准为93.3

说明模型找到不同语言之间的Cross-lingual Alignment

为了找到不同语言的信息之间的差异,决定自己train一个BERT,这里有小插曲,小数据量(200k sentences for each lang)根本训练不起来,用了1000k sentences才得到比较好的结果:
y轴是:Mean Reciprocal Rank (MRR): Higher MRR, better alignment
先得到不同语言token的向量表示:

然后求平均并求二者的差异:

然后可以通过以下的方式进行不同语言的重现:
