【Python|第41期】初识 Pandas 数据处理库
日期:2023年9月6日
作者:Commas
签名:(ง •_•)ง 积跬步以致千里,积小流以成江海……
注释:如果您觉得有所帮助,帮忙点个赞,也可以关注我,我们一起成长;如果有不对的地方,还望各位大佬不吝赐教,谢谢^ - ^
1.01365 = 37.7834;0.99365 = 0.0255
1.02365 = 1377.4083;0.98365 = 0.0006
文章目录
- 一、前言
- 二、安装和导入 Pandas
- 三、Pandas的数据结构
-
- (3-1) 创建 Series 数据结构
- (3-2)创建 DataFrame 数据结构
- 四、数据导入和导出
-
- (4-1)数据导入
- (4-2)数据导出
- 五、数据清洗和处理
-
- (5-1)处理缺失值
- (5-2)处理重复值
- (5-3)数据筛选和切片
- (5-4)数据变换
- (5-5)数据排序
- 六、数据分析和统计
-
- (6-1)基本统计信息
- (6-2)分组和聚合
- (6-3)数据透视表
- (6-4)数据分布分析
- (6-5)相关性分析
- (6-6)汇总和汇总统计
- (6-7)时间序列分析
- 七、数据可视化
-
- (7-1)Matplotlib
- (7-2)Seaborn
- (7-3)其他可视化库
- (7-4)时间序列可视化
- (7-5)多图形和子图:

一、前言
Pandas 是 Python 生态系统中的一款强大的数据处理和分析库,它为数据科学家、分析师和开发者提供了丰富的工具来处理、清理和分析数据。在本文中,我们将一步步介绍 Pandas 的基本概念和操作,带你逐渐掌握这个重要的工具。
二、安装和导入 Pandas
首先,确保你已经安装了 Pandas。在终端中运行以下命令:
pip install pandas
在 Python 脚本中导入 Pandas:
import pandas as pd
三、Pandas的数据结构
Pandas 提供了两个主要的数据结构:Series 和 DataFrame。
| 数据结构 | 说明 |
|---|---|
Series |
类似于带标签的一维数组。可用于表示时间序列数据或单列数据。Series 与 DataFrame 共享许多功能,但它们更灵活,可用于处理更简单的数据结构。 |
DataFrame |
类似于二维表格,由多个 Series 组成,类似于数据库表或电子表格。由行和列组成,每列可以包含不同类型的数据,例如整数、浮点数、字符串等。你可以将DataFrame看作是一个二维的数据结构,可以轻松地进行数据处理和分析 |
(3-1) 创建 Series 数据结构
一个关于学生考试成绩的数据集,可以使用 Series 来表示学生的数学成绩:

示例代码:
import pandas as pd
# 创建一个Pandas Series,表示学生的数学成绩
math_scores = pd.Series([85, 92, 100, 88, 95])
# 添加标签,表示每个学生的姓名
math_scores.index = ['Alice', 'Bob', 'Commas', 'David', 'Eva']
# 打印 Series
print(math_scores)
# 打印 Commas 的数学成绩
print("")
print(f"Commas的数学成绩是{math_scores['Commas']}")
print(f"Commas的数学成绩是{math_scores.loc['Commas']}")
print(f"Commas的数学成绩是{math_scores.iloc[2]}")
输出结果:
Alice 85
Bob 92
Commas 100
David 88
Eva 95
dtype: int64
Commas的数学成绩是100
Commas的数学成绩是100
Commas的数学成绩是100
(3-2)创建 DataFrame 数据结构
一个包含学生信息的数据集,包括姓名、年龄和数学成绩。可以使用 DataFrame 来表示这个数据集:
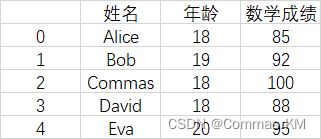
示例代码:
import pandas as pd
# 创建一个包含学生信息的Pandas DataFrame
data = {
'姓名': ['Alice', 'Bob', 'Commas', 'David', 'Eva'],
'年龄': [18, 19, 18, 18, 20],
'数学成绩': [85, 92, 100, 88, 95]
}
student_df = pd.DataFrame(data)
# 打印 DataFrame
print(student_df)
# 打印 Commas 的数学成绩
print("")
# NO1:
print(”NO1:“)
commas_math_score = student_df.iloc[2]['数学成绩']
print(f"Commas的数学成绩是{commas_math_score}")
print(”NO2:“)
commas_math_score = student_df.loc[student_df['姓名'] == 'Commas', '数学成绩'].values[0]
print(f"Commas的数学成绩是{commas_math_score}")
输出结果:
姓名 年龄 数学成绩
0 Alice 18 85
1 Bob 19 92
2 Commas 18 100
3 David 18 88
4 Eva 20 95
NO1:
Commas的数学成绩是100
NO2
Commas的数学成绩是100
四、数据导入和导出
(4-1)数据导入
Pandas 支持从各种数据源加载数据,包括 CSV、Excel、SQL 数据库、JSON、HTML、Parquet等。我们可以使用 pd.read_xxx() 函数来轻松导入数据,其中 xxx 代表不同的数据格式,如下所示:
| 方法 | 说明 |
|---|---|
pd.read_csv() |
用于读取逗号分隔的文本文件,通常用于读取 CSV(Comma-Separated Values)文件。 |
pd.read_excel() |
用于读取 Microsoft Excel 文件,支持读取 XLS 和 XLSX 格式的文件。 |
pd.read_sql() |
用于从 SQL 数据库中读取数据,可以连接到各种 SQL 数据库,如 MySQL、SQLite、PostgreSQL 等。 |
pd.read_json() |
用于读取 JSON(JavaScript Object Notation)格式的数据。 |
pd.read_html() |
用于从 HTML 网页中抓取表格数据,并将其转换为 DataFrame。需要注意的是,此函数返回一个DataFrame 列表,每个 DataFrame 对应一个抓取的表格。 |
pd.read_clipboard() |
可以读取剪贴板中的数据并将其转换为 DataFrame ,通常用于快速从其他应用程序中复制粘贴数据。 |
pd.read_parquet() |
用于读取 Parquet 文件格式,这是一种高性能的列式存储格式,通常用于大数据处理。 |
pd.read_feather() |
用于读取 Feather 文件格式,这是一种轻量级的列式数据存储格式,通常用于高性能数据交换。 |
pd.read_hdf() |
用于读取 HDF5(Hierarchical Data Format version 5)文件,这是一种用于存储和组织大型数据集的格式。 |
pd.read_sas() |
用于读取 SAS(Statistical Analysis System)数据集文件。 |
pd.read_stata() |
用于读取 Stata 数据文件,通常用于经济学和统计分析。 |
pd.read_gbq() |
用于从 Google BigQuery 中读取数据,适用于云数据分析任务。 |
pd.read_clip() |
用于从剪贴板中读取数据,类似于 pd.read_clipboard()。 |
示例如下:
# pd.read_csv():用于读取逗号分隔的文本文件,例如:
pd.read_csv('file.csv')
# pd.read_excel():用于读取Microsoft Excel文件,例如:
pd.read_excel('file.xlsx')
# pd.read_sql():用于从SQL数据库中读取数据,需要指定数据库连接等参数,例如:
pd.read_sql('SELECT * FROM table_name', connection)
# pd.read_json():用于读取JSON格式的数据,例如:
pd.read_json('file.json')
# pd.read_html():用于从HTML网页中抓取表格数据,例如:
tables = pd.read_html('http://example.com')
df = tables[0] # 获取第一个表格
# pd.read_parquet():用于读取Parquet文件格式,例如:
pd.read_parquet('file.parquet')
# pd.read_feather():用于读取Feather文件格式,例如:
pd.read_feather('file.feather')
# pd.read_hdf():用于读取HDF5文件格式,例如:
pd.read_hdf('file.h5')
# pd.read_sas():用于读取SAS数据集文件,例如:
pd.read_sas('file.sas7bdat')
# pd.read_stata():用于读取Stata数据文件,例如:
pd.read_stata('file.dta')
# pd.read_gbq():用于从Google BigQuery中读取数据,需要指定SQL查询和认证等参数,例如:
pd.read_gbq('SELECT * FROM dataset.table', project_id='your-project-id')
(4-2)数据导出
Pandas 也支持将数据导出为不同格式,使用 to_xxx() 方法,如 to_csv()、to_excel() 等。
| 方法 | 说明 |
|---|---|
pd.to_csv() |
将 DataFrame 对象保存为 CSV 文件。 |
pd.to_excel() |
将 DataFrame 对象保存为 Excel 文件。 |
pd.to_sql() |
将 DataFrame 对象保存到 SQL 数据库表中,需要指定数据库连接和表名等参数。 |
pd.to_json() |
将 DataFrame 对象保存为 JSON 格式的文件。 |
pd.to_html() |
将 DataFrame 对象转换为 HTML 表格。 |
pd.to_parquet() |
将 DataFrame 对象保存为 Parquet 文件格式。 |
pd.to_feather() |
将 DataFrame 对象保存为 Feather 文件格式。 |
pd.to_hdf() |
将 DataFrame 对象保存为 HDF5 文件格式。 |
pd.to_clipboard() |
将 DataFrame 对象复制到剪贴板,以便粘贴到其他应用程序中。 |
示例如下:
# pd.to_csv():将DataFrame对象保存为CSV文件,例如:
df.to_csv('file.csv', index=False)
# pd.to_excel():将DataFrame对象保存为Excel文件,例如:
df.to_excel('file.xlsx', index=False)
# pd.to_sql():将DataFrame对象保存到SQL数据库表中,需要指定数据库连接和表名等参数,例如:
df.to_sql('table_name', con=connection, index=False)
# pd.to_json():将DataFrame对象保存为JSON格式的文件,例如:
df.to_json('file.json', orient='records')
# pd.to_html():将DataFrame对象转换为HTML表格,例如:
html = df.to_html()
# pd.to_parquet():将DataFrame对象保存为Parquet文件格式,例如:
df.to_parquet('file.parquet', index=False)
# pd.to_feather():将DataFrame对象保存为Feather文件格式,例如:
df.to_feather('file.feather')
# pd.to_hdf():将DataFrame对象保存为HDF5文件格式,例如:
df.to_hdf('file.h5', key='data', mode='w')
# pd.to_clipboard():将DataFrame对象复制到剪贴板,以便粘贴到其他应用程序中,例如:
df.to_clipboard(index=False)
五、数据清洗和处理
Pandas提供了丰富的数据清洗和处理工具,包括:
| 方法 | 说明 |
|---|---|
| 处理缺失值 | dropna() 删除缺失值,fillna() 填充缺失值。 |
| 处理重复值 | duplicated() 和 drop_duplicates() 用于处理重复行。 |
| 数据筛选和切片 | 使用布尔索引、条件筛选数据。 |
| 数据变换 | apply() 函数用于对数据进行函数变换。 |
| 数据排序 | sort_values() 和 sort_index() 用于排序数据。 |
(5-1)处理缺失值
- 识别缺失值:使用
isna()或isnull()方法来标识DataFrame中的缺失值。 - 删除缺失值:使用
dropna()方法删除包含缺失值的行或列。 - 填充缺失值:使用
fillna()方法将缺失值填充为特定的值,例如平均值、中位数或其他自定义值。
# 识别缺失值
df.isna()
# 删除包含缺失值的行
df.dropna()
# 填充缺失值为0
df.fillna(0)
(5-2)处理重复值
- 识别重复值:使用
duplicated()方法来标识DataFrame中的重复行。 - 删除重复值:使用
drop_duplicates()方法删除重复的行。
# 识别重复值
df.duplicated()
# 删除重复的行
df.drop_duplicates()
(5-3)数据筛选和切片
- 使用布尔索引来选择满足特定条件的行。
- 使用
loc[]和iloc[]来选择特定行和列。
# 选择满足条件的行
df[df['column_name'] > 10]
# 使用loc选择行和列
df.loc[df['column_name'] > 10, ['column1', 'column2']]
(5-4)数据变换
- 使用
apply()方法应用自定义函数来转换数据。 - 使用
map()方法将值映射到新的值。 - 使用
replace()方法替换特定值。
# 使用apply应用函数
df['new_column'] = df['old_column'].apply(lambda x: x * 2)
# 使用map映射值
df['category'] = df['label'].map({'A': 1, 'B': 2, 'C': 3})
# 使用replace替换值
df['column_name'].replace({'old_value': 'new_value'}, inplace=True)
(5-5)数据排序
- 使用sort_values()方法按列对数据进行排序。
- 使用sort_index()方法按索引对数据进行排序。
# 按列排序
df.sort_values('column_name', ascending=False)
# 按索引排序
df.sort_index(ascending=False)
六、数据分析和统计
Pandas具有丰富的统计和分析功能,包括:
| 方法 | 说明 |
|---|---|
| 基本统计信息 | describe()、mean()、median()、sum()等。 |
| 分组和聚合 | groupby()和聚合函数(如sum()、mean()、count() 等)用于按条件分组数据并进行聚合操作。 |
| 透视表 | 使用 pivot_table() 函数创建透视表以汇总和分析数据。 |
| 时间序列分析 | 支持时间序列数据的处理和分析,包括日期范围生成、重采样、滚动窗口统计等。 |
(6-1)基本统计信息
- 使用describe()方法生成有关数据的基本统计信息,包括均值、标准差、最小值、最大值和四分位数等。
df.describe()
(6-2)分组和聚合
使用groupby()方法按照一个或多个列的值将数据分组。
- 使用聚合函数(如sum()、mean()、median()、count()等)对分组数据进行聚合操作。
# 按列进行分组并计算均值
df.groupby('category')['value'].mean()
(6-3)数据透视表
- 使用pivot_table()方法创建数据透视表,用于汇总和分析数据。
# 创建数据透视表,汇总销售数据
pivot_table = df.pivot_table(index='date', columns='product', values='sales', aggfunc='sum')
(6-4)数据分布分析
使用hist()方法绘制直方图,查看数据的分布情况。
- 使用boxplot()方法绘制箱线图,用于检测异常值。
# 绘制直方图
df['column_name'].hist()
# 绘制箱线图
df.boxplot(column='value')
(6-5)相关性分析
- 使用corr()方法计算列之间的相关性系数。
# 计算列之间的相关性系数
df.corr()
(6-6)汇总和汇总统计
使用sum()、mean()、median()等汇总函数对数据进行统计汇总。
- 使用agg()方法可以同时应用多个聚合函数。
# 求和
df['value'].sum()
# 应用多个聚合函数
df['value'].agg(['sum', 'mean', 'median'])
(6-7)时间序列分析
- 如果数据包含时间序列信息,Pandas提供了丰富的时间序列分析功能,包括日期范围生成、重采样、移动窗口统计等。
七、数据可视化
Pandas虽然不是一个专门用于数据可视化的库,但它与其他 Python 可视化库(如 Matplotlib、Seaborn 等)集成得非常好,因此可以轻松地用于数据可视化任务。以下是一些使用 Pandas 进行数据可视化的常见方法:
(7-1)Matplotlib
Pandas 的 DataFrame 和 Series 对象都有内置的 .plot() 方法,可以直接使用 Matplotlib 来创建各种类型的图表,如折线图、散点图、柱状图等。
import pandas as pd
import matplotlib.pyplot as plt
# 创建DataFrame或Series
data = pd.DataFrame({'x': [1, 2, 3, 4, 5], 'y': [10, 15, 13, 18, 12]})
# 创建折线图
data.plot(x='x', y='y', kind='line')
plt.show()
(7-2)Seaborn
Seaborn 是一个建立在 Matplotlib 之上的统计数据可视化库,它能够轻松地创建各种统计图形,如散点图、箱线图、热力图等。
import seaborn as sns
# 创建DataFrame
data = pd.DataFrame({'x': [1, 2, 3, 4, 5], 'y': [10, 15, 13, 18, 12]})
# 创建散点图
sns.scatterplot(x='x', y='y', data=data)
plt.show()
(7-3)其他可视化库
除了 Matplotlib 和 Seaborn,Pandas 还可以与其他可视化库(如Plotly、Bokeh、Altair等)集成,以创建更高级和交互式的可视化。
(7-4)时间序列可视化
如果你处理的是时间序列数据,可以使用Pandas的时间序列绘图功能,例如绘制时间序列折线图。
# 将DataFrame索引转换为时间戳
data['date'] = pd.to_datetime(data['date'])
data.set_index('date', inplace=True)
# 创建时间序列折线图
data['value'].plot()
plt.show()
(7-5)多图形和子图:
Pandas允许你在同一图中创建多个子图,从而可以比较不同数据集或不同图形。
# 创建多个子图
fig, axes = plt.subplots(nrows=2, ncols=2)
# 在每个子图中绘制不同的数据
data1.plot(ax=axes[0, 0])
data2.plot(ax=axes[0, 1])
data3.plot(ax=axes[1, 0])
data4.plot(ax=axes[1, 1])
plt.show()
我的微信公众号【会飞的小猴子】,等你来关注哦 ^ - ^
参考文章:
- Pandas官方文档
版权声明:本文为博主原创文章,如需转载,请给出:
原文链接:https://blog.csdn.net/qq_35844043/article/details/132644636