周志华《机器学习》课后习题解析(第四章):决策树
作者 | 我是韩小琦
链接 | https://zhuanlan.zhihu.com/p/44666694
4.1 试证明对于不含冲突数据(即特征向量完全相同但标记不同)的训练集,必存在与训练集一致(即训练误差为 0) 的决策树。
答:
从原书p74的图4.2的决策树学习的基本算法可以看出,生成一个叶节点有三种情况:
1、节点下样本 全属于同一类样本 ,则将当前节点作为 类叶节点。
2、属性集 ,或者样本在当前属性集上取值相同。即特征用完了(当只剩最后一个特征时,进一步分裂,只能将各取值设立叶节点,标记为样本最多的类别。),或者的样本在 上取值都相同(感觉这里貌似和第 一条重复了)。这时取 中最多的类作为此节点的类别标记。
3、在某一节点上的属性值 ,样本为空,即没有样本在属性 上取值为 。同样取 中最多的类作为此节点的类别标记。
在这道题中,目标是找出和训练集一致的决策树,所以不必考虑第3点,从1、2情况来看出决策树中树枝停止“生长”生成叶节点只会在样本属于同一类或者所有特征值都用完的时候,那么可能导致叶节点标记与实际训练集不同时只会发生在特征值都用完的情况(同一节点中的样本,其路径上的特征值都是完全相同的),而由于训练集中没有冲突数据,那每个节点上训练误差都为0。
4.2 试析使用"最小训练误差"作为决策树划分选择准则的缺陷。
答:
这道题暂时没想出答案。在网上找了其他的答案,都是认为会造成过拟合,没给出具体证明。而我的理解决策树本身就是容易过拟合的,就算使用信息增益或者基尼指数等,依旧容易过拟合,至于使用“最小训练误差”会不会“更容易”过拟合暂时没理解明白。
待填坑。
4.3 试编程实现基于信息熵进行划分选择的决策树算法,并为表 4.3 中数据生成一棵决策树。
答:
因为数据集的原因,数据量比较小,在选择划分属性的时候会出现特征的信息增益或者信息增益率相同的情况。所有生成的决策树和书中可能不一致。并且在生成叶节点时,会出现两类数量一直的情况,这时候叶节点就随机设置一个分类了。
代码实现了以信息增益、增益率、基尼指数划分准则。下面一道题(4.4)也是用相同的代码。另外画图的代码是主要参考《机器学习实战》决策树那一章画图源码。
有些地方代码有点乱,比如进行剪枝的部分就有大量重复代码;并且预剪枝部分可以在生成决策树的时候实现,减少计算量。以后有机会再优化一下。
代码在:
https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets/tree/master/ch4--%E5%86%B3%E7%AD%96%E6%A0%91/4.3-4.4
pruning.py
import pandas as pd
import numpy as np
def post_pruning(X_train, y_train, X_val, y_val, tree_=None):
if tree_.is_leaf:
return tree_
if X_val.empty: # 验证集为空集时,不再剪枝
return tree_
most_common_in_train = pd.value_counts(y_train).index[0]
current_accuracy = np.mean(y_val == most_common_in_train) # 当前节点下验证集样本准确率
if tree_.is_continuous:
up_part_train = X_train.loc[:, tree_.feature_name] >= tree_.split_value
down_part_train = X_train.loc[:, tree_.feature_name] < tree_.split_value
up_part_val = X_val.loc[:, tree_.feature_name] >= tree_.split_value
down_part_val = X_val.loc[:, tree_.feature_name] < tree_.split_value
up_subtree = post_pruning(X_train[up_part_train], y_train[up_part_train], X_val[up_part_val],
y_val[up_part_val],
tree_.subtree['>= {:.3f}'.format(tree_.split_value)])
tree_.subtree['>= {:.3f}'.format(tree_.split_value)] = up_subtree
down_subtree = post_pruning(X_train[down_part_train], y_train[down_part_train],
X_val[down_part_val], y_val[down_part_val],
tree_.subtree['< {:.3f}'.format(tree_.split_value)])
tree_.subtree['< {:.3f}'.format(tree_.split_value)] = down_subtree
tree_.high = max(up_subtree.high, down_subtree.high) + 1
tree_.leaf_num = (up_subtree.leaf_num + down_subtree.leaf_num)
if up_subtree.is_leaf and down_subtree.is_leaf:
def split_fun(x):
if x >= tree_.split_value:
return '>= {:.3f}'.format(tree_.split_value)
else:
return '< {:.3f}'.format(tree_.split_value)
val_split = X_val.loc[:, tree_.feature_name].map(split_fun)
right_class_in_val = y_val.groupby(val_split).apply(
lambda x: np.sum(x == tree_.subtree[x.name].leaf_class))
split_accuracy = right_class_in_val.sum() / y_val.shape[0]
if current_accuracy > split_accuracy: # 若当前节点为叶节点时的准确率大于不剪枝的准确率,则进行剪枝操作——将当前节点设为叶节点
set_leaf(pd.value_counts(y_train).index[0], tree_)
else:
max_high = -1
tree_.leaf_num = 0
is_all_leaf = True # 判断当前节点下,所有子树是否都为叶节点
for key in tree_.subtree.keys():
this_part_train = X_train.loc[:, tree_.feature_name] == key
this_part_val = X_val.loc[:, tree_.feature_name] == key
tree_.subtree[key] = post_pruning(X_train[this_part_train], y_train[this_part_train],
X_val[this_part_val], y_val[this_part_val], tree_.subtree[key])
if tree_.subtree[key].high > max_high:
max_high = tree_.subtree[key].high
tree_.leaf_num += tree_.subtree[key].leaf_num
if not tree_.subtree[key].is_leaf:
is_all_leaf = False
tree_.high = max_high + 1
if is_all_leaf: # 若所有子节点都为叶节点,则考虑是否进行剪枝
right_class_in_val = y_val.groupby(X_val.loc[:, tree_.feature_name]).apply(
lambda x: np.sum(x == tree_.subtree[x.name].leaf_class))
split_accuracy = right_class_in_val.sum() / y_val.shape[0]
if current_accuracy > split_accuracy: # 若当前节点为叶节点时的准确率大于不剪枝的准确率,则进行剪枝操作——将当前节点设为叶节点
set_leaf(pd.value_counts(y_train).index[0], tree_)
return tree_
def pre_pruning(X_train, y_train, X_val, y_val, tree_=None):
if tree_.is_leaf: # 若当前节点已经为叶节点,那么就直接return了
return tree_
if X_val.empty: # 验证集为空集时,不再剪枝
return tree_
# 在计算准确率时,由于西瓜数据集的原因,好瓜和坏瓜的数量会一样,这个时候选择训练集中样本最多的类别时会不稳定(因为都是50%),
# 导致准确率不稳定,当然在数量大的时候这种情况很少会发生。
most_common_in_train = pd.value_counts(y_train).index[0]
current_accuracy = np.mean(y_val == most_common_in_train)
if tree_.is_continuous: # 连续值时,需要将样本分割为两部分,来计算分割后的正确率
split_accuracy = val_accuracy_after_split(X_train[tree_.feature_name], y_train,
X_val[tree_.feature_name], y_val,
split_value=tree_.split_value)
if current_accuracy >= split_accuracy: # 当前节点为叶节点时准确率大于或分割后的准确率时,选择不划分
set_leaf(pd.value_counts(y_train).index[0], tree_)
else:
up_part_train = X_train.loc[:, tree_.feature_name] >= tree_.split_value
down_part_train = X_train.loc[:, tree_.feature_name] < tree_.split_value
up_part_val = X_val.loc[:, tree_.feature_name] >= tree_.split_value
down_part_val = X_val.loc[:, tree_.feature_name] < tree_.split_value
up_subtree = pre_pruning(X_train[up_part_train], y_train[up_part_train], X_val[up_part_val],
y_val[up_part_val],
tree_.subtree['>= {:.3f}'.format(tree_.split_value)])
tree_.subtree['>= {:.3f}'.format(tree_.split_value)] = up_subtree
down_subtree = pre_pruning(X_train[down_part_train], y_train[down_part_train],
X_val[down_part_val],
y_val[down_part_val],
tree_.subtree['< {:.3f}'.format(tree_.split_value)])
tree_.subtree['< {:.3f}'.format(tree_.split_value)] = down_subtree
tree_.high = max(up_subtree.high, down_subtree.high) + 1
tree_.leaf_num = (up_subtree.leaf_num + down_subtree.leaf_num)
else: # 若是离散值,则变量所有值,计算分割后正确率
split_accuracy = val_accuracy_after_split(X_train[tree_.feature_name], y_train,
X_val[tree_.feature_name], y_val)
if current_accuracy >= split_accuracy:
set_leaf(pd.value_counts(y_train).index[0], tree_)
else:
max_high = -1
tree_.leaf_num = 0
for key in tree_.subtree.keys():
this_part_train = X_train.loc[:, tree_.feature_name] == key
this_part_val = X_val.loc[:, tree_.feature_name] == key
tree_.subtree[key] = pre_pruning(X_train[this_part_train], y_train[this_part_train],
X_val[this_part_val],
y_val[this_part_val], tree_.subtree[key])
if tree_.subtree[key].high > max_high:
max_high = tree_.subtree[key].high
tree_.leaf_num += tree_.subtree[key].leaf_num
tree_.high = max_high + 1
return tree_
def set_leaf(leaf_class, tree_):
# 设置节点为叶节点
tree_.is_leaf = True # 若划分前正确率大于划分后正确率。则选择不划分,将当前节点设置为叶节点
tree_.leaf_class = leaf_class
tree_.feature_name = None
tree_.feature_index = None
tree_.subtree = {}
tree_.impurity = None
tree_.split_value = None
tree_.high = 0 # 重新设立高 和叶节点数量
tree_.leaf_num = 1
def val_accuracy_after_split(feature_train, y_train, feature_val, y_val, split_value=None):
# 若是连续值时,需要需要按切分点对feature 进行分组,若是离散值,则不用处理
if split_value is not None:
def split_fun(x):
if x >= split_value:
return '>= {:.3f}'.format(split_value)
else:
return '< {:.3f}'.format(split_value)
train_split = feature_train.map(split_fun)
val_split = feature_val.map(split_fun)
else:
train_split = feature_train
val_split = feature_val
majority_class_in_train = y_train.groupby(train_split).apply(
lambda x: pd.value_counts(x).index[0]) # 计算各特征下样本最多的类别
right_class_in_val = y_val.groupby(val_split).apply(
lambda x: np.sum(x == majority_class_in_train[x.name])) # 计算各类别对应的数量
return right_class_in_val.sum() / y_val.shape[0] # 返回准确率
treeCreate.py 和 treePlotter.py 见上面链接。
生成决策树如下:
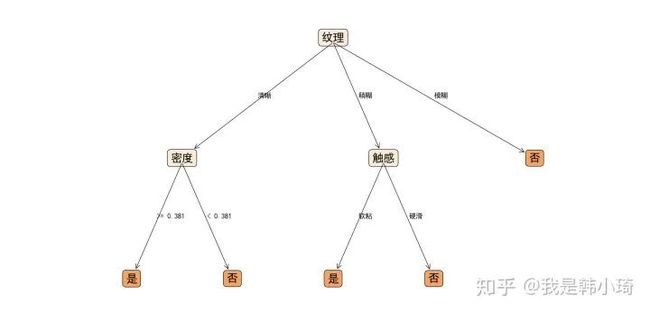
4.4 试编程实现基于基尼指数进行划分选择的决策树算法,为表 4.2 中数据生成预剪枝、后剪枝决策树并与未剪枝决策树进行比较.
答:
https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets/tree/master/ch4--%E5%86%B3%E7%AD%96%E6%A0%91/4.3-4.4
未剪枝、后剪枝、预剪枝生成决策树分别如下,总体来说后剪枝会相比于预剪枝保留更多的分支。
有两个需要注意的地方。一个是在4.3中说过的,因为划分属性的信息增益或者基尼指数相同的原因,这个时候选择哪一个属性作为划分属性都是对的,生成决策树和书中不一致是正常的(书中第一个节点为“脐部”)。另外数据量这么小的情况下,常常会出现剪枝前后准确率不变的情况,原书中也提到这种情况通常要进行剪枝的,但是这道题中若进行剪枝,会出现只有一个叶节点的情况。为了画图好看点...所以都不无论在预剪枝还是后剪枝中,这种情况都会采取不剪枝策略。参考原书P82。
经过测试,在未剪枝的情况下,验证集上准确率为0.2857;后剪枝准确率为0.5714;预剪枝也为0.5714。
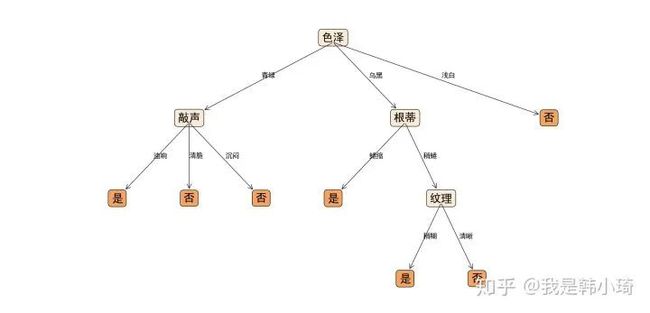 未剪枝
未剪枝  后剪枝
后剪枝 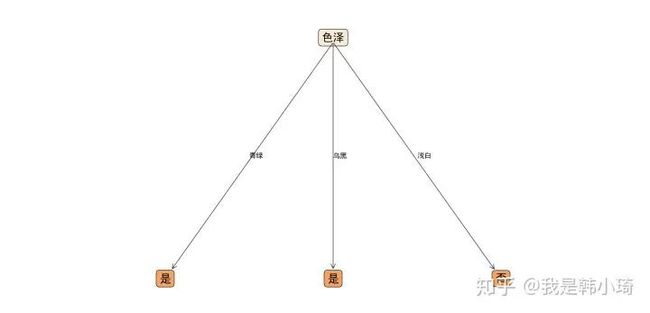 预剪枝
预剪枝
4. 5 试编程实现基于对率回归进行划分选择的决策树算法,并为表 4.3 中数据生成一棵决策树.
答:
这个没实现。一种思路就是拟合对率回归后,从所有特征中选择一个 值最高的一个特征值,即权重最高的一个特征值作为划分选择,但是没想好对于One-hot之后的特征权重怎么计算,比如“色泽”有三种取值“乌黑”、“青绿”、“浅白”,在One-hot之后会有三个特征,那么最后“色泽”这个特征的权重应该是取平均值?以后有机会....也不填坑。
4.6 试选择 4 个 UCI 数据集,对上述 3 种算法所产生的未剪枝、预剪枝、后剪枝决策树进行实验比较,并进行适当的统计显著性检验.
答:
只拿sklearn中自带的iris数据集试了一下剪枝后的准确率,发现不同随机数种子(使得数据集划分不同)导致最后验证集的准确率变化挺大。
统计显著性检验没实现。
https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets/tree/master/ch4--%E5%86%B3%E7%AD%96%E6%A0%91/4.6
'''
treeCreater 和 treePlotter 代码见 ch4/4.3-4.4
数据量不大,不同的随机数种子,测试集的准确率变化较大
'''
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
import treeCreater
import treePlottter
iris = datasets.load_iris()
X = pd.DataFrame(iris['data'], columns=iris['feature_names'])
y = pd.Series(iris['target_names'][iris['target']])
# 取三个样本为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=15)
# 剩下120个样本中,取30个作为剪枝时的验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=15)
# 不剪枝
tree_no_pruning = treeCreater.DecisionTree('gini')
tree_no_pruning.fit(X_train, y_train, X_val, y_val)
print('不剪枝:', np.mean(tree_no_pruning.predict(X_test) == y_test))
# treePlottter.create_plot(tree_no_pruning.tree_)
# 预剪枝
tree_pre_pruning = treeCreater.DecisionTree('gini', 'pre_pruning')
tree_pre_pruning.fit(X_train, y_train, X_val, y_val)
print('预剪枝:', np.mean(tree_pre_pruning.predict(X_test) == y_test))
# treePlottter.create_plot(tree_pre_pruning.tree_)
# 后剪枝
tree_post_pruning = treeCreater.DecisionTree('gini', 'post_pruning')
tree_post_pruning.fit(X_train, y_train, X_val, y_val)
print('后剪枝:', np.mean(tree_post_pruning.predict(X_test) == y_test))
# treePlottter.create_plot(tree_post_pruning.tree_)
4.7 图 4.2 是一个递归算法,若面临巨量数据,则决策树的层数会很深,使用递归方法易导致"栈"溢出。试使用"队列"数据结构,以参数MaxDepth 控制树的最大深度,写出与图 4.2 等价、但不使用递归的决策树生成算法.
答:
主要思路每一次循环遍历一层下节点(除去叶节点),为每一个节点生成子节点,将非叶节点入队;用参数L保存每一层有多少个节点。下一次循环执行同样的步骤。直至所有的节点都叶节点,此时队列为空。具体如下:
输入:训练集D = {(x1, y1), (x2, y2)...(xm, ym)};
属性集A = {a1, a2... ad};
最大深度MaxDepth = maxDepth
过程:函数TreeDenerate(D, A, maxDepth)
生成三个队列,NodeQueue、DataQueue、AQueue分别保存节点、数据、和剩余属性集;
2生成节点Node_root;
3: if A为空 OR D上样本都为同一类别:
4: 将Node_root标记为叶节点,其标记类别为D中样本最多的类;
5: return Node_root;
6: end if
7: 将Node入队NodeQueue; 将D入队 DataQueue; 将A入队AQueue;
8: 初始化深度depth=0;
9: 初始化L = 1; # L用于记录每一层有多少非叶节点。
10: while NodeQueue 非空:
11: L* = 0
12: for _ in range(L): # 遍历当前L个非叶节点
13: NodeQueue 出队Node; DataQueue出队D; AQueue 出队A;
14: 从A中选择一个最优划分属性a*;
15: for a* 的每一个值 a*v do:
16: 新建一个node*,并将node*连接为Node的一个分支;
17: 令 Dv表示为D中在a*上取值为a*v的样本子集;
18: if Dv为空:
19: 将node*标记为叶节点,其标记类别为D中样本最多的类;
20: continue;
21: end if
22: if A\{a*}为空 OR Dv上样本都为同一类别 OR depth == maxDepth:
23: 将node*标记为叶节点,其标记类别为Dv中样本最多的类;
24: continue;
25: end if
26: 将node*入队NodeQueue; 将Dv入队 DataQueue; 将A\{a*} 入队AQueue;
27: L* += 1; # 用于计算在第depth+1 层有多少个非叶节点
28: L = L*;
29: depth += 1;
30: return Node_root;
输入以Node_root为根节点的一颗决策树
4.8 试将决策树生成的深度优先搜索过程修改为广度优先搜索,以参数MaxNode控制树的最大结点数,将题 4.7 中基于队列的决策树算法进行改写。对比题 4.7 中的算法,试析哪种方式更易于控制决策树所需存储不超出内存。
答:
4.7写的算法就是广度优先搜索的。这道题将MaxNode改为MaxDepth,只需要改几个地方。有一点需要注意的地方,就是在给一个节点生成子节点时(19-32行),可能造成节点数大于最大值的情况,比如某属性下有3种取值,那么至少要生成3个叶节点,这个时候节点总数可能会超过最大值,这时最终节点数可能会是MaxNode+2。
至于两种算法对比。个人理解当数据特征值,各属性的取值较多时,形成的决策树会趋于较宽类型的树,这时使用广度优先搜索更容易控制内存。若属性取值较少时,深度优先搜索更容易控制内存。
对4.7中修改如下:
输入:训练集D = {(x1, y1), (x2, y2)...(xm, ym)};
属性集A = {a1, a2... ad};
最大深度MaxNode = maxNode
过程:函数TreeDenerate(D, A, maxNode)
1: 生成三个队列,NodeQueue、DataQueue、AQueue分别保存节点、数据、和剩余属性集;
2: 生成节点Node_root;
3: if A为空 OR D上样本都为同一类别:
4: 将Node_root标记为叶节点,其标记类别为D中样本最多的类;
5: return Node_root;
6: end if
7: 将Node入队NodeQueue; 将D入队 DataQueue; 将A入队AQueue;
8: 初始化深度numNode=1;
9: 初始化L = 1; # L用于记录每一层有多少非叶节点。
10: while NodeQueue 非空:
11: L* = 0
12: for _ in range(L): # 遍历当前L个非叶节点
13: NodeQueue 出队Node; DataQueue出队D; AQueue 出队A;
14: if numNode >= maxNode:
15: 将Node标记为叶节点,其标记类别为D中样本最多的类;
16: continue;
17: end if;
18: 从A中选择一个最优划分属性a*;
19: for a* 的每一个值 a*v do:
20: numNode+=1
21: 生成一个node*,并将node*连接为Node的一个分支;
22: 令 Dv表示为D中在a*上取值为a*v的样本子集;
23: if Dv为空:
24: 将node*标记为叶节点,其标记类别为D中样本最多的类;
25: continue;
26: end if
27: if A\{a*}为空 OR Dv上样本都为同一类别:
28: 将node*标记为叶节点,其标记类别为Dv中样本最多的类;
29: continue;
30: end if
31: 将node*入队NodeQueue; 将Dv入队 DataQueue; 将A\{a*} 入队AQueue;
32: L* += 1; # 用于计算在第depth+1 层有多少个非叶节点
33: end if;
34: L = L*;
35: return Node_root;
4.9 试将 4.4.2 节对缺失值的处理机制推广到基尼指数的计算中去.
答:
这道题相对简单。使用书中式4.9、4.10、4.11有,对于原书中4.5式可以推广为:
属性a的基尼指数可推广为:
4.10 从网上下载或自己编程实现任意一种多变量决策树算法,并观察其在西瓜数据集 3.0 上产生的结果
答:
待补充。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑AI基础下载(pdf更新到25集)机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085,加入微信群请扫码喜欢文章,点个在看