Attention 机制
1. 前言
在自然语言处理领域,近几年最火的是什么?是BERT!谷歌团队2018提出的用于生成词向量的BERT算法在NLP的11项任务中取得了非常出色的效果,堪称2018年深度学习领域最振奋人心的消息。而BERT算法又是基于Transformer,Transformer又是基于attention机制。这次咱们从Encoder-Decoder->Attention->Transformer逐步讲解。
2. Encoder-Decoder
Encoder-Decoder框架顾名思义也就是编码-解码框架,目前大部分attention模型都是依附于Encoder-Decoder框架进行实现,在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。具体到NLP中的任务比如:
文本摘要,输入一篇文章(序列数据),生成文章的摘要(序列数据)
文本翻译,输入一句或一篇英文(序列数据),生成翻译后的中文(序列数据)
问答系统,输入一个question(序列数据),生成一个answer(序列数据)
基于Encoder-Decoder框架具体使用什么模型实现,由大家自己决定~用的较多的应该就是seq2seq模型和Transformer了。
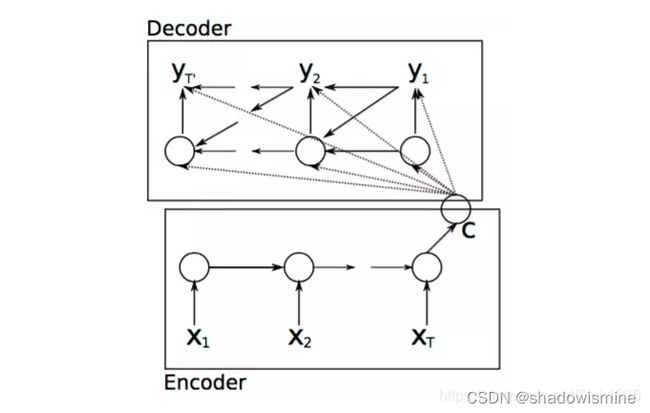
上图就是Encoder-Decoder框架在NLP领域中抽象后的最简单的结构图。
Encoder:编码器,对于输入的序列
Encoder究竟是如何编码的呢?
编码方式有很多种,在文本处理领域主要有RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU,可以依照自己的喜好来选择编码方式。
我们以RNN为例来具体说明一下:
以上图为例,输入
得到了语义编码C之后,接下来就是要在Decoder中对语义编码C进行解码了。
Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU。Decoder和Encoder的编码解码方式可以任意组合,并不是说我Encoder使用了RNN,Decoder就一定也需要使用RNN才能解码,Decoder可以使用LSTM,BiRNN这些。
Decoder究竟是如何解码的呢?
基于seq2seq模型有两种解码方式:
[论文1]Cho et al., 2014 . Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
论文1中指出,因为语义编码C包含了整个输入序列的信息,所以在解码的每一步都引入C。文中Ecoder-Decoder均是使用RNN,在计算每一时刻的输出yt时,都应该输入语义编码C,即ht=f(ht-1,yt-1,C),p(yt)=f(ht,yt−1,C)。ht为当前t时刻的隐藏层的值,yt-1为上一时刻的预测输出,作为t时刻的输入,每一时刻的语义编码C是相同地。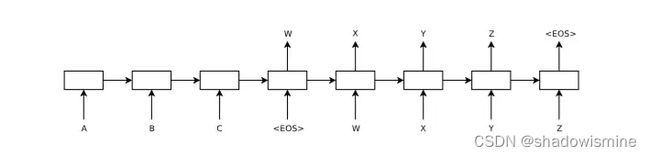
[论文2]Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks.
论文2的方式相对简单,只在Decoder的初始输入引入语义编码C,将语义编码C作为隐藏层状态值h0的初始值,p(yt)=f(ht,yt−1)。
至于Decoder到底使用哪一种呢,答案是两种都不建议使用!
普通的Encoder-Decoder结构还是存在很多问题地:

1.如果按照论文1解码,每一时刻的输出如上式所示,从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的语义编码C都是一样的,没有任何区别。而语义编码C是由输入序列X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实输入序列X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)
2.将整个序列的信息压缩在了一个语义编码C中,用一个语义编码C来记录整个序列的信息,序列较短还行,如果序列是长序列,比如是一篇上万字的文章,我们要生成摘要,那么只是用一个语义编码C来表示整个序列的信息肯定会损失很多信息,而且序列一长,就可能出现梯度消失问题,这样将所有信息压缩在一个C里面显然就不合理。
既然一个C不行,那咱们就用多个C,诶~这个时候基于Encoder-Decoder的attention model就出现了。
3. Attention Model
3.1 注意力机制简介
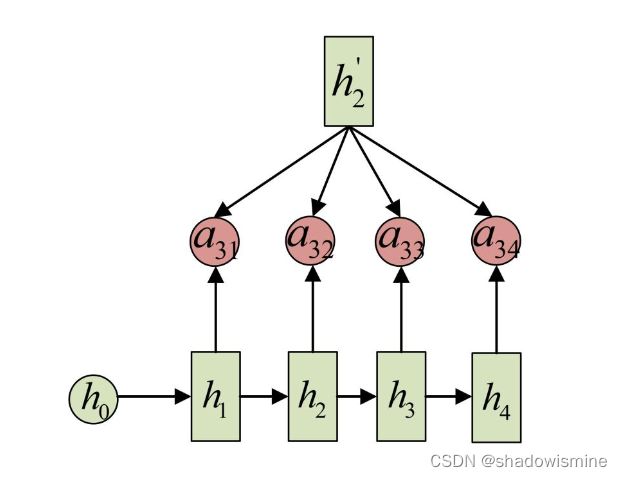
注意力机制(attention mechanism)是对基础Encoder-Decoder的改良。Attention机制通过在每个时间输入不同的c来解决问题,下图是带有Attention机制的Decoder:
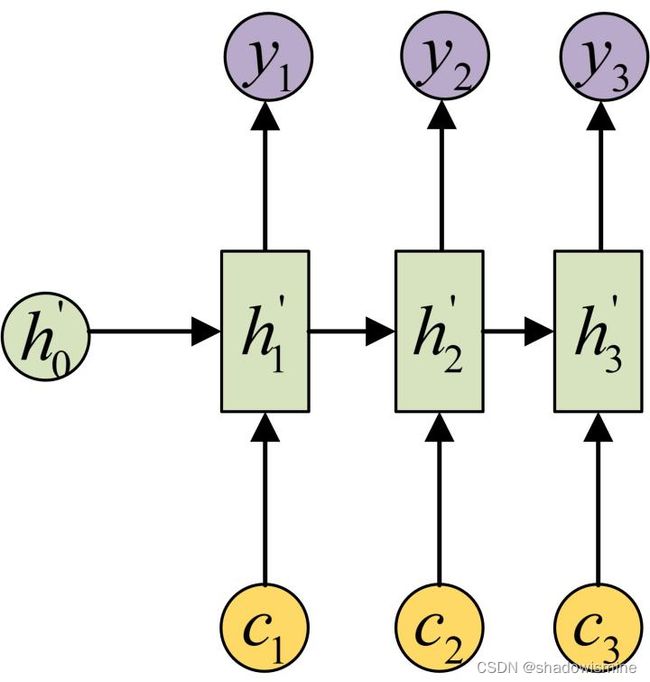
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用aij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 ci就来自于所有 hj 对 aij 的加权和。
以机器翻译为例(将中文翻译成英文):
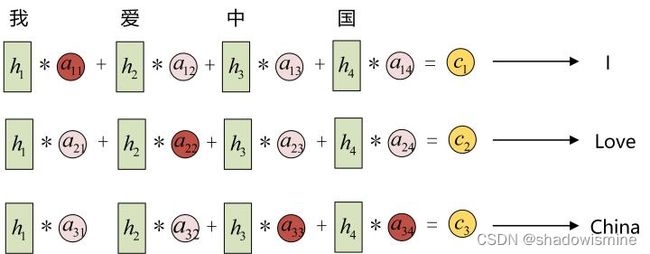
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和 “我” 这个字最相关,因此对应的 a11 就比较大,而相应的 a12、a13、a14 就比较小。c2应该和“爱”最相关,因此对应的 a22 就比较大。最后的c3和h3、h4最相关,因此 a33、a34 的值就比较大。
至此,关于Attention模型,只剩最后一个问题了,那就是:这些权重 aij 是怎么来的?
事实上,aij 同样是从模型中学出的,它实际和Decoder的第i-1阶段的隐状态、Encoder第j个阶段的隐状态有关。
同样还是拿上面的机器翻译举例, a1j 的计算(此时箭头就表示对h’和 hj 同时做变换),a2j 的计算和a3j 的计算分别为


注意一下,这里咱们使用的是Soft Attention是所有的数据都会注意,都会计算出相应的注意力权值,不会设置筛选条件。还有一种Hard Attention会在生成注意力权重后筛选掉一部分不符合条件的注意力,让它的注意力权值为0,即可以理解为不再注意这些不符合条件的部分。
3.2 Attention 机制的本质思想
上面咱们说了Attention的原理,但是是基于Encoder-Decoder框架来介绍地,Attention机制并不是一定要基于Encoder-Decoder框架,那么他的本质思想是什么呢?以及在上面遗留下来的Hi与h1,h2,h3…hm的相关性到底应该怎么算呢?现在就来为大家讲解。

参照上图可以这么来理解Attention,将Source中的构成元素想象成是由一系列的![]()
Lx表示source的长度,Similarity(Q,Ki)计算如下:

MLP多层感知机感觉在这里用得比较少,反正我没怎么用过,就不介绍了。搞懂下面这两种计算相似性的方法:
点积:就是将Query和Keyi进行点积,Transformer中就是用的这种方法。
Cosine相似性-余弦相似度:
分子就是两个向量Query与Key的点积
分母就是两个向量的L2范数,(L2范数:指向量各元素的平方和然后求平方根)
计算出Query和Keyi的相似性后,第二阶段引入类似SoftMax的计算方式对第一阶段的相似性得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:

第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
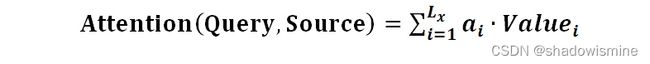
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数的注意力机制计算方法都符合上述的三阶段计算过程。
最后对上述计算Attention值地三个阶段做一个总结:
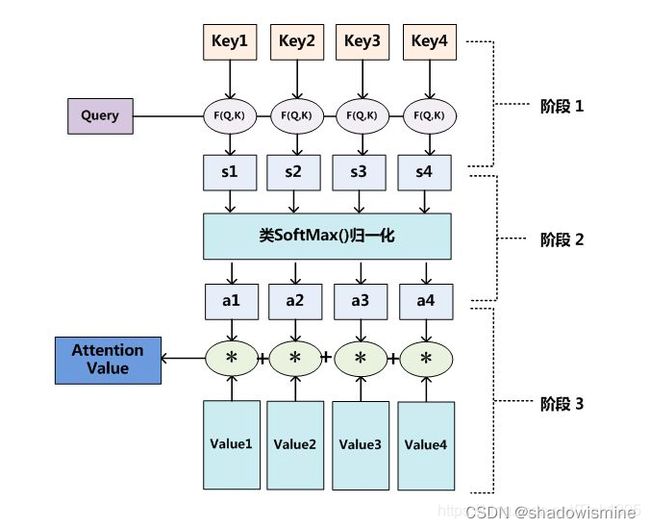
阶段1:Query与每一个Key计算相似性得到相似性评分s
阶段2:将s评分进行softmax转换成[0,1]之间的概率分布
阶段3:将[a1,a2,a3…an]作为权值矩阵对Value进行加权求和得到最后的Attention值
3.3 Attention优缺点
优点:
1.速度快。Attention机制不再依赖于RNN,解决了RNN不能并行计算的问题。这里需要说明一下,基于Attention机制的seq2seq模型,因为是有监督的训练,所以咱们在训练的时候,在decoder阶段并不是说预测出了一个词,然后再把这个词作为下一个输入,因为有监督训练,咱们已经有了target的数据,所以是可以并行输入的,可以并行计算decoder的每一个输出,但是再做预测的时候,是没有target数据地,这个时候就需要基于上一个时间节点的预测值来当做下一个时间节点decoder的输入。所以节省的是训练的时间。
2.效果好。效果好主要就是因为注意力机制,能够获取到局部的重要信息,能够抓住重点。
缺点:
1.只能在Decoder阶段实现并行运算,Encoder部分依旧采用的是RNN,LSTM这些按照顺序编码的模型,Encoder部分还是无法实现并行运算,不够完美。
2.就是因为Encoder部分目前仍旧依赖于RNN,所以对于中长距离之间,两个词相互之间的关系没有办法很好的获取。
为了改进上面两个缺点,更加完美的Self-Attention出现了。
4.Self-Attention
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,相当于是Query=Key=Value,计算过程与attention一样,所以这里不再赘述其计算过程细节。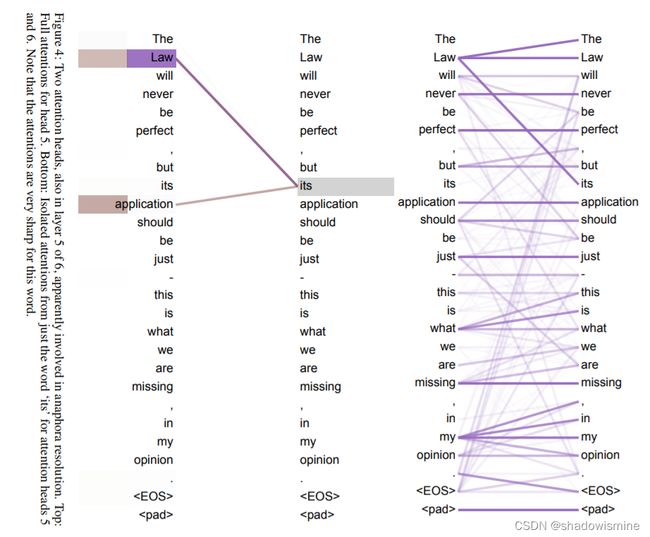
例如上图是self-attention的一个例子:
我们想知道这句话中的its,在这句话里its指代的是什么,与哪一些单词相关,那么就可以将its作为Query,然后将这一句话作为Key和Value来计算attention值,找到与这句话中its最相关的单词。通过self-attention我们发现its在这句话中与之最相关的是Law和application,通过我们分析语句意思也十分吻合。
如此引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self Attention逐渐被广泛使用的主要原因。
原文链接:https://blog.csdn.net/Tink1995/article/details/105012972