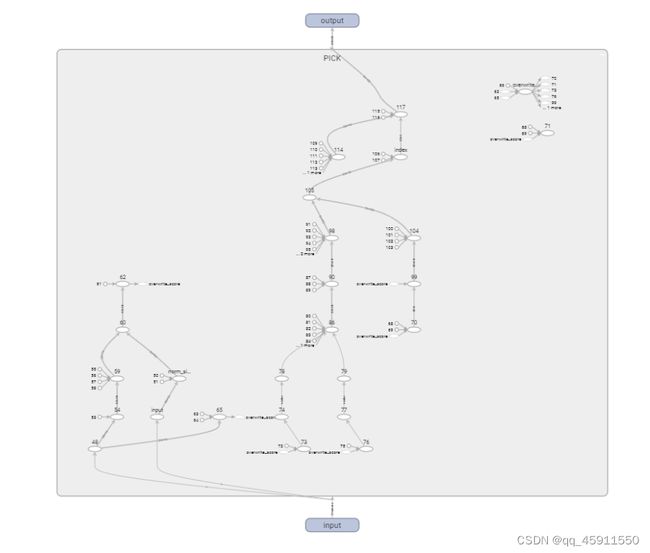
Trace a function defined in a model
reason
The event file is too large to trace a total model, which couldn’t be opened by brower, trace every functions in the model is a alternative method.
here to donwload pytorch_utils.py
import torch
import torch.nn as nn
from pytorch_utils.modules import MLP
EPS = 1e-8
class WorkingMemory(nn.Module):
def __init__(self, device='cpu', mem_type='vanilla', num_cells=10,
mem_size=300, mlp_size=300, dropout_rate=0.5,
key_size=20, usage_decay_rate=0.98, **kwargs):
super(WorkingMemory, self).__init__()
self.device = device
self.mem_type = mem_type
self.num_cells = num_cells
self.mem_size = mem_size
self.mlp_size = mlp_size
self.usage_decay_rate = usage_decay_rate
# Dropout module
self.drop_module = nn.Dropout(p=dropout_rate, inplace=False)
if self.mem_type == 'learned':
self.init_mem = nn.Parameter(torch.zeros(self.num_cells, self.mem_size))
elif self.mem_type == 'key_val':
self.key_size = key_size
# Initialize key and value vectors
self.init_key = nn.Parameter(torch.zeros(self.num_cells, key_size))
# MLP to determine entity or not
self.entity_mlp = MLP(self.mem_size, mlp_size, 1, num_layers=2, bias=True)
# MLP to merge past memory and current candidate to write new memory
self.U_key = nn.Linear(2 * mem_size, mem_size, bias=True)
# MLP to determine coref similarity between current token and memory
self.sim_mlp = MLP(3 * self.mem_size + 1, mlp_size, 1, num_layers=2, bias=True)
self.gumbel_temperature = nn.Parameter(torch.tensor([1.0]), requires_grad=False)
def initialize_memory(self, batch_size):
"""Initialize the memory with the learned key and the null value part."""
init_mem = torch.zeros(batch_size, self.num_cells, self.mem_size).to(self.device)
if self.mem_type == 'learned':
init_mem = self.init_mem.unsqueeze(dim=0)
init_mem = init_mem.repeat(batch_size, 1, 1)
elif self.mem_type == 'key_val':
init_val = torch.zeros(batch_size, self.num_cells,
self.mem_size - self.key_size).to(self.device)
init_key = self.init_key.unsqueeze(dim=0)
init_key = init_key.repeat(batch_size, 1, 1)
init_mem = torch.cat([init_key, init_val], dim=2)
init_usage = torch.zeros(batch_size, self.num_cells).to(self.device)
return (init_mem, init_usage)
def sample_gumbel(self, shape, eps=EPS):
U = torch.rand(shape).to(self.device)
return -torch.log(-torch.log(U + eps) + eps)
def pick_overwrite_cell(self, usage, sim_score):
"""Pick cell to overwrite.
- Prefer unused cells.
- Break ties using similarity.
"""
norm_sim_score = nn.functional.softmax(sim_score, dim=-1)
# Assign overwrite scores to each cell.
# (1) Prefer cells which have not been used.
# (2) Among the unused cells, prefer ones with the higher similarily score
# (Useful for memory with learned initialization).
# (3) Otherwise prefer cells with least usage.
overwrite_score = ((usage == 0.0).float() * norm_sim_score * 1e5) + (1 - usage)
if self.training:
logits = torch.log(overwrite_score * (1 - EPS) + EPS)
gumbel_noise = self.sample_gumbel(usage.size())
y = nn.functional.softmax(
(logits + gumbel_noise) / self.gumbel_temperature, dim=-1)
else:
max_val = torch.max(overwrite_score, dim=-1, keepdim=True)[0]
# Randomize the max
index = torch.argmax(
(torch.empty(overwrite_score.shape).uniform_(0.01, 1).to(self.device)
* (overwrite_score == max_val).float()),
dim=-1, keepdim=True)
y = torch.zeros_like(overwrite_score).scatter_(-1, index, 1.0)
return y
def predict_entity_prob(self, cur_hidden_state):
"""Predicts whether the current word is (part of) an entity or not."""
ent_score = self.entity_mlp(cur_hidden_state)
# Perform a softmax over scores of 0 and ent_score
comb_score = torch.cat([torch.zeros_like(ent_score).to(self.device),
ent_score], dim=1)
# Numerically stable softmax
max_score, _ = torch.max(comb_score, dim=1, keepdim=True)
ent_prob = nn.functional.softmax(comb_score - max_score, dim=1)
# We only care about the 2nd column i.e. corresponding to ent_score
ent_prob = torch.unsqueeze(ent_prob[:, 1], dim=1)
return ent_score, ent_prob
def get_coref_mask(self, usage):
"""No coreference with empty cells."""
cell_mask = (usage > 0).float().to(self.device)
return cell_mask
def predict_coref_overwrite(self, mem_vectors, query_vector, usage,
ent_prob):
"""Calculate similarity between query_vector and mem_vectors.
query_vector: B x M x H
mem_vectors: B x M x H
"""
pairwise_vec = torch.cat([mem_vectors, query_vector,
query_vector * mem_vectors,
torch.unsqueeze(usage, dim=2)], dim=-1)
pairwise_score = self.sim_mlp(pairwise_vec)
sim_score = pairwise_score # B x M x1
sim_score = torch.squeeze(sim_score, dim=-1)
batch_size = query_vector.shape[0]
base_score = torch.zeros((batch_size, 1)).to(self.device)
comb_score = torch.cat([sim_score, base_score], dim=1)
# Bx(M+1)
coref_mask = self.get_coref_mask(usage) # B x M
# Coref only possible when the cell is active
mult_mask = torch.cat([coref_mask,
torch.ones((batch_size, 1)).to(self.device)], dim=-1)
# Zero out the inactive cell scores and then add a big negative value
comb_score = comb_score * mult_mask + (1 - mult_mask) * (-1e4)
# Numerically stable softmax
max_cell_score, _ = torch.max(comb_score, dim=1, keepdim=True)
init_probs = nn.functional.softmax(comb_score - max_cell_score, dim=1)
# Make sure the inactive cells are really zero even after logit of -1e4
masked_probs = init_probs * mult_mask
norm_probs = (
masked_probs/(torch.sum(masked_probs, dim=-1, keepdim=True) + EPS))
coref_over_probs = ent_prob * norm_probs
indv_coref_prob = coref_over_probs[:, :self.num_cells]
overwrite_prob = coref_over_probs[:, self.num_cells]
overwrite_prob = torch.unsqueeze(overwrite_prob, dim=1)
return indv_coref_prob, overwrite_prob
def forward(self, data_w):
"""Read excerpts.
hidden_state_list: list of B x H tensors
input_mask_list: list of B sized tensors
"""
hidden_state_list = data_w[0]
input_mask_list = data_w[1]
batch_size = hidden_state_list[0].shape[0]
if self.mem_type == 'key_val':
# Get initialized key vectors
init_key = self.init_key.unsqueeze(dim=0)
init_key = init_key.repeat(batch_size, 1, 1)
# Initialize memory
mem_vectors, usage = self.initialize_memory(batch_size)
# Store all updates
ent_list, usage_list, coref_list, overwrite_list = [], [], [], []
for t, (cur_hidden_state, cur_input_mask) in \
enumerate(zip(hidden_state_list, input_mask_list)):
query_vector = self.drop_module(cur_hidden_state)
ent_score, ent_prob = self.predict_entity_prob(query_vector)
ent_prob = ent_prob * torch.unsqueeze(cur_input_mask, dim=1)
ent_list.append(ent_prob * (1 - EPS) + EPS)
rep_query_vector = query_vector.unsqueeze(dim=1)
# B x M x H
rep_query_vector = rep_query_vector.repeat(1, self.num_cells, 1)
indv_coref_prob, new_ent_prob = self.predict_coref_overwrite(
mem_vectors=mem_vectors, query_vector=rep_query_vector,
usage=usage, ent_prob=ent_prob)
coref_list.append(indv_coref_prob * (1 - EPS) + EPS)
# Overwriting Prob - B x M
pairwise_vec = torch.cat([mem_vectors, rep_query_vector,
rep_query_vector * mem_vectors,
torch.unsqueeze(usage, dim=2)], dim=-1)
init_sim_score = torch.squeeze(self.sim_mlp(pairwise_vec), dim=-1)
overwrite_prob = (
new_ent_prob * self.pick_overwrite_cell(usage, init_sim_score)
)
try:
assert (torch.max(overwrite_prob) <= 1)
assert (torch.max(indv_coref_prob) <= 1)
assert (torch.max(ent_prob) <= 1)
except AssertionError:
print("Assertion Error happened! Trying best to recover")
return None
# raise
overwrite_list.append(overwrite_prob * (1 - EPS) + EPS)
comb_inp = torch.cat([rep_query_vector, mem_vectors], dim=-1)
mem_candidate = torch.tanh(self.U_key(comb_inp))
# B x M x H
updated_mem_vectors = (
torch.unsqueeze(overwrite_prob, dim=2) * rep_query_vector
+ torch.unsqueeze(1 - overwrite_prob - indv_coref_prob, dim=2)
* mem_vectors
+ torch.unsqueeze(indv_coref_prob, dim=2) * mem_candidate
)
if self.mem_type == 'key_val':
# Don't update the key dimensions. Only update the later dimensions.
updated_mem_vectors = torch.cat(
[init_key, updated_mem_vectors[:, :, self.key_size:]], dim=2)
# Update usage
updated_usage = torch.min(
torch.FloatTensor([1.0]).to(self.device),
overwrite_prob + indv_coref_prob + self.usage_decay_rate * usage)
usage_list.append(updated_usage)
# Update memory
mem_vectors, usage = updated_mem_vectors, updated_usage
# return {'ent': ent_list, 'usage': usage_list,
# 'coref': coref_list, 'overwrite': overwrite_list}
return (ent_list, usage_list, coref_list, overwrite_list)
class PICK(nn.Module):
def __init__(self, memory):
super(PICK, self).__init__()
self.memory = memory
def forward(self, pick_data):
usage, sim_score = pick_data
return self.memory.pick_overwrite_cell(usage, sim_score)
if __name__ == "__main__":
from torch.utils.tensorboard import SummaryWriter
hidden_state_list = tuple(list(torch.randn(99, 32, 300)))
input_mask_list = tuple(list(torch.zeros(99, 32, )))
memory = WorkingMemory()
data_w = (hidden_state_list, input_mask_list)
model = PICK(memory)
# result = model(data_w)
# print(result[0])
pick_data = (torch.zeros(32, 10), torch.randn(32, 10))
result = model(pick_data)
# print(result)
writer = SummaryWriter('structure/pick_overwrite_cell') # 建立一个保存数据用的东西
writer.add_graph(model, (pick_data, ))
writer.add_text("text", "hello, this is a text info", global_step=2)
writer.close()