数据结构与算法(005):线性表-链式存储结构与单链表
线性表的链式存储结构
前面我们讲的线性表的顺序存储结构,它最大的缺点就是插入和删除时需要移动大量元素,这显然就需要耗费时间。
那我们能不能针对这个缺陷或者说遗憾提出解决的方法呢?要解决这个问题,我们就得考虑一下导致这个问题的原因!
为什么当插入和删除时,就要移动大量的元素?
原因就在于相邻两元素的存储位置也具有邻居关系,它们在内存中的位置是紧挨着的,中间没有间隙,当然就无法快速插入和删除。
经过叽叽呱呱的讨论之后,我们派出几个童鞋跟大家分享一下思路。
A童鞋:让当中每个元素之间都留有一个空位置,这样要插入一个元素时,就不至于要移动了。可一个空位置如何解决多个相同位置插入数据的问题呢?所以这个想法显然不行。
B童鞋:那就让当中每个元素之间都留足够多的位置,根据实际情况制定空隙大小,比如每个元素间留10个空位。那么问题就显而易见了,造成资源的极大浪费,并且在同一个位置插入11次也不是不可能。
C童鞋:反正要在相邻元素间留多少空间都是有可能不够的,那不如干脆不要考虑相邻位置这个问题了。哪里有空位就放在哪里,记得在《零基础入门学习C语言》中讲到的指针刚好可以派上用场。每个元素多用一个位置来存放指向下一个元素的位置的指针。这样子从第一个元素可以找到第二个元素,第二个元素可以找到第三个元素,依此类推,所有的元素我们就都可以通过遍历而找到了。
好,太棒了,这个想法灰常好!掌声鼓励!
线性表链式存储结构定义
哎呀,又要讲定义的时候了,往往啊,这个时候就是搬出概念砸脚的时候了。我们不能这样丫,我们的课堂应该是欢乐与傻笑并存,智慧与邪恶同在。
好,那我们从爱情动作片开始吧~
这个无论是爱情片还是动作片,我们都感觉它没有悬疑片那么吸引人。。。。。。
而悬疑片正是像链式存储那样一环套这一环,时而让你紧张,时而让你鸡冻!
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以存在内存中未被占用的任意位置。
比起顺序存储结构每个数据元素只需要存储一个位置就可以了。现在链式存储结构中,除了要存储数据元素信息外,还要存储它的后继元素的存储地址(指针)。
也就是说除了存储其本身的信息外,还需存储一个指示其直接后继的存储位置的信息。
我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称为指针或链。这两部分信息组成数据元素称为存储映像,称为结点(Node)。
n个结点链接成一个链表,即为线性表(a1, a2, a3, …, an)的链式存储结构。
因为此链表的每个结点中只包含一个指针域,所以叫做单链表。
单链表
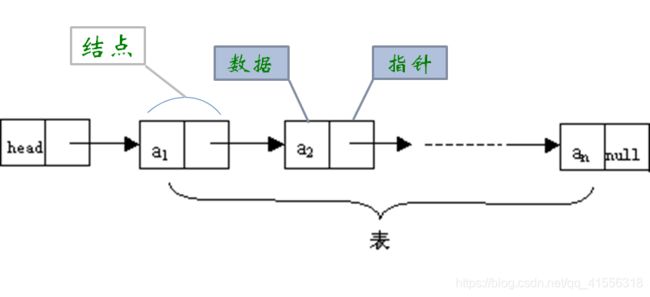
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中的第一个结点的存储位置叫做头指针,最后一个结点指针为空(NULL)。
头指针与头结点的异同
那有童鞋就疑惑了,既然头结点的数据域不存储任何信息,那么头指针和头结点又有何异同呢?
头指针
头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针。
头指针具有标识作用,所以常用头指针冠以链表的名字(指针变量的名字)。
无论链表是否为空,头指针均不为空。
头指针是链表的必要元素。
头结点
头结点是为了操作的统一和方便而设立的,放在第一个元素的结点之前,其数据域一般无意义(但也可以用来存放链表的长度)。
有了头结点,对在第一元素结点前插入结点和删除第一结点起操作与其它结点的操作就统一了。
头结点不一定是链表的必须要素。
单链表存储结构
单链表图例:

空链表图例:

我们在C语言中可以用结构指针来描述单链表。
typedef struct Node
{
ElemType data; // 数据域
struct Node* Next; // 指针域
} Node;
typedef struct Node* LinkList;我们看到结点由存放数据元素的数据域和存放后继结点地址的指针域组成。
假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next的值是一个指针。
那么p->next指向谁呢?当然指向第i+1个元素!也就是指向ai+1的指针。
问题:
如果p->data = ai,那么p->next->data = ?(i为下标)
答案:
p->next->data = ai+1。(i+1为下标)
单链表的读取
在线性表的顺序存储结构中,我们要计算任意一个元素的存储位置是很容易的。
但在单链表中,由于第i个元素到底在哪?我们压根儿没办法一开始就知道,必须得从第一个结点开始挨个儿找。
因此,对于单链表实现获取第i个元素的数据的操作GetElem,在算法上相对要麻烦一些,大家不妨先思考一下。
获得链表第i个数据的算法思路:
声明一个结点p指向链表第一个结点,初始化j从1开始;
当j 若到链表末尾p为空,则说明第i个元素不存在; 否则查找成功,返回结点p的数据。 有了以上的思路提示,请大家再度进行头脑风暴:算法的C语言实现代码,GetElem.c 说白了,就是从头开始找,直到第i个元素为止。 由于这个算法的时间复杂度取决于i的位置,当i=1时,则不需要遍历,而i=n时则遍历n-1次才可以。因此最坏情况的时间复杂度为O(n)。 由于单链表的结构中没有定义表长,所以不能实现知道要循环多少次,因此也就不方便使用for来控制循环。 其核心思想叫做“工作指针后移”,这其实也是很多算法的常用技术。 我们先来看下单链表的插入。假设存储元素e的结点为s,要实现结点p、p->next和s之间逻辑关系的变化,大家参考下图思考一下: 我们思考后发觉根本用不着惊动其他结点,只需要让s->next和p->next的指针做一点改变。 s->next = p->next; p->next = s; 我们通过图片来解读一下这两句代码。 那么我们考虑一下大部分初学者最容易搞坏脑子的问题:这两句代码的顺序可不可以交换过来? 先p->next = s; 再s->next = p->next; 大家发现没有?如果先执行p->next的话会先被覆盖为s的地址,那么s->next = p->next其实就等于s->next = s了。 所以这两句是无论如何不能弄反的,这点初学者一定要注意咯~ 单链表第i个数据插入结点的算法思路: 声明一结点p指向链表头结点,初始化j从1开始; 当j<1时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1; 若到链表末尾p为空,则说明第i个元素不存在; 否则查找成功,在系统中生成一个空结点s; 将数据元素e赋值给s->data; 单链表的插入刚才两个标准语句; 返回成功。 现在我们再来看单链表的删除操作。 假设元素a2的结点为q,要实现结点q删除单链表的操作,其实就是将它的前继结点的指针绕过指向后继结点即可。 那我们所要做的,实际上就是一步: 可以这样:p->next = p->next->next; 也可以是:q=p->next; p->next=q->next; 那么我给大家提供算法的思路,由大家来写一下代码吧~ 单链表第i个数据删除结点的算法思路: 声明结点p指向链表第一个结点,初始化j=1; 当j<1时,就遍历链表,让P的指针向后移动,不断指向下一个结点,j累加1; 若到链表末尾p为空,则说明第i个元素不存在; 否则查找成功,将欲删除结点p->next赋值给q; 单链表的删除标准语句p->next = q->next; 将q结点中的数据赋值给e,作为返回; 释放q结点。 我们最后的环节是效率PK,我们发现无论是单链表插入还是删除算法,它们其实都是由两个部分组成:第一部分就是遍历查找第i个元素,第二部分就是实现插入和删除元素。 从整个算法来说,我们很容易可以推出它们的时间复杂度都是O(n)。 再详细点分析:如果在我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。 但如果,我们希望从第i个位置开始,插入连续10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个位置,所以每次都是O(n)。 而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。 显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显啦~/* 初始条件:顺序线性表L已存在,1<=i<=ListLength(L) */
/* 操作结果:用e返回L中第i个数据元素的值 */
Status GetElem( LinkList L, int i, ElemType *e )
{
int j;
LinkList p;
p = L->next;
j = 1;
while( p && jnext;
++j;
}
if( !p || j>i )
{
return ERROR;
}
*e = p->data;
return OK;
}
单链表的插入
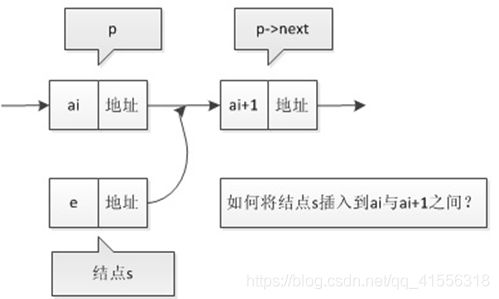
/* 初始条件:顺序线性表L已存在,1<=i<=ListLength(L) */
/* 操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1 */
Status ListInsert(LinkList *L, int i, ElemType e)
{
int j;
LinkList p, s;
p = *L;
j = 1;
while( p && jnext;
j++;
}
if( !p || j>i )
{
return ERROR;
}
s = (LinkList)malloc(sizeof(Node));
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
单链表的删除
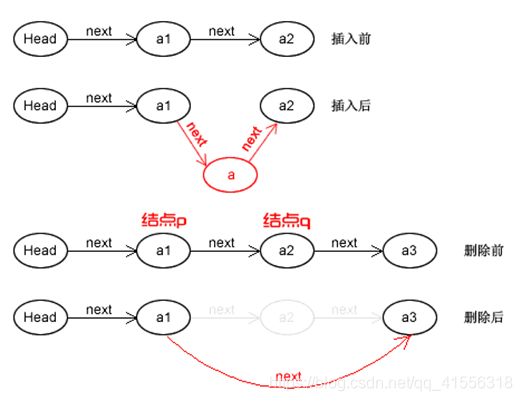
/* 初始条件:顺序线性表L已存在,1<=i<=ListLength(L) */
/* 操作结果:删除L的第i个数据元素,并用e返回其值,L的长度-1 */
Status ListDelete(LinkList *L, int i, ElemType *e)
{
int j;
LinkList p, q;
p = *L;
j = 1;
while( p->next && jnext;
++j;
}
if( !(p->next) || j>i )
{
return ERROR;
}
q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return OK;
}
效率PK
为了帮助大家更好的理解链表的读取、插入和删除操作,可下载 数据结构动画演示 观看动画操作,以帮助我们更好的理解和学习。