生成式AI -大模型Claude 和 LangChain 教程:构建由搜索驱动的个人助理应用
本文转自:躺平猫猫
本文讲述如何利用 LangChain 并在其之上使用 Anthropic 的 Claude 大模型, 结合Python 和 ReactJS 构建由搜索驱动的个人助理 AI 应用
这里先讲一下,我为啥要用Claude, 而不是ChatGPT。据我自己的感受
1 Claude是嵌在Slack中使用,很方便,只需要在登录Slack的时候要用下梯子,其余的时候是无障碍使用的
2 Claude 比较实事求是,比如问 秦始皇是罗马帝国第几任皇帝,Claude会告知这个问题是错误的,但是ChatGPT会直接给出一个头头是道的虚拟故事
Claude 介绍
Anthropic是一个专注于开发先进AI系统的研究机构。Claude是其研制的大模型产品, 旨在提供诚实可靠无害的新一代AI助手。该模型在各种任务中需要确保高度的可靠性和可预测性。
Claude的主要功能包括:
- 全面的对话和文本处理能力
- 将用户安全和隐私放在首要位置
Claude的主要使用场景:
- - 摘要生成
- - 搜索引擎
- - 创意和协作式写作
- - 问答
- - 编程辅助
Claude是跨领域应用的理想AI工具, 能够赋能不同领域的用户。
Claude和ChatGPT的主要区别
1. 训练数据不同:
- Claude主要通过对话进行监督训练,注重提高交互的一致性和安全性。
- ChatGPT通过自监督在大规模文本数据上进行预训练,更关注知识的广度
2. 能力定位不同:
- Claude定位为辅助工具,旨在提供有用、真实、无害的帮助。
-
ChatGPT侧重娱乐交互,可能生成具有欺骗性或有害信息的文本。
3. 使用方式不同:
- Claude提供API接入,需要在后端对其进行封装和控制。
-
ChatGPT直接面向终端用户,交互更自由开放。
4. 系统设计不同:
- Claude在模型和系统层面都加入了对安全性和可控性的考量。
- ChatGPT主要关注交互的流畅性和人类化程度。
总体来说,Claude更注重可靠性、安全性,ChatGPT更注重自然交互和知识丰富度。两者有各自的侧重点和使用场景。
LangChain 介绍
LangChain是一个用于构建端到端大语言模型应用的通用工具。它提供了健壮的框架, 简化了创建、管理和部署大语言学习模型(LLM)的过程。
LLM是专门为理解、生成人类语言而设计的先进AI模型。
LangChain的主要功能包括:
- 高效管理LLM的提示
- 能够为复杂工作流创建任务链
- 为AI添加状态,允许它记住以往的交互信息
这些功能使得LangChain成为一个强大且易于使用的平台,可以利用大语言模型提升各种应用的能力。
学习本文需要提前掌握的知识
- Python基础
- Typescript和/或React基础
- 可访问Anthropic的Claude API
- 可访问SerpApi的网络搜索API
步骤大纲
-
初始化项目
-
使用Claude和LangChain构建AI助手App的前端
-
编写项目文件
-
测试AI助手App
初始化项目
1. 安装 Flask
pip install Flask2. 创建工作目录
mkdir claude-langchaincd claude-langchain
3. 设置虚拟环境(可选),在使用Python项目时,使用虚拟环境是个好习惯。可以使用`venv`来创建一个虚拟环境,这样可以将项目的依赖隔离在单独的环境中,避免污染全局Python环境
python -m venv venvsource venv/bin/activate (Linux/Mac)venv\Scripts\activate (Windows)
4. 创建 main.py 文件
touch app.py # Linux/Macecho.>app.py # Windows
5. 在main.py文件中编写 Flask代码:
from flask import Flaskapp = Flask(__name__)@app.route('/')def hello_world():return 'Hello, World!'if __name__ == '__main__':app.run()
6. 运行该代码
python main.py7. 打开浏览器,输入http://127.0.0.1:5000,将看到 "Hello, World!",此时说明Flask项目创建成功
管理环境变量
1. 安装python-dotenv and langchain
使用python-dotenv包来控制.env 文件,可以方便的管理环境变量。同时也需要安装langchain包
pip install python-dotenv langchain2. 创建.env文件
touch .env # Linux/Macecho.>.env # Windows
3. 在文件中添加环境变量
ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxxxxxxxxxSERPAPI_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
获取Claude API key 的地址 https://console.anthropic.com/chat
获取SerpAPI key 的地址 https://serpapi.com/dashboard
4. 加载环境变量
import os
from flask import Flask
from dotenv import load_dotenv
load_dotenv()
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()5.不要在版本控制中共享敏感信息,例如秘钥。如果使用 Git,请在 .gitignore 文件中添加以下内容:
.env这样可以避免意外地提交包含敏感信息的 .env 文件到版本仓库中。
现在,Flask 项目已经设置好了从 .env 文件中加载环境变量。你可以根据需要添加更多变量,并通过 os.environ.get('KEY') 访问它们。切记勿将 .env 文件提交到版本控制中。
使用Claude和LangChain构建AI助手App的前端
本教程会涉及Node.js、npm、React和Typescript相关知识。
同时,将Anthropic的Claude模型和LangChain这两种强大的AI技术进行结合,演示如何生成准确的、近似人类的的文本语言。
安装 Node.js 和 NPM
1. 下载安装 Node.js (https://nodejs.org).
2. 使用如下命令检查是否安装成功
node -vnpm -v
设置项目环境
安装 Create React App
Create React App (CRA - https://reactjs.org/docs/create-a-new-react-app.html#create-react-app) 是一个命令行工具,可以用来创建一个全新的React.js应用,可以通过npm进行全局安装,很方便地为我们生成一个 React 项目的基础结构和配置。
npm install -g create-react-app使用Typescript创建新的React 项目
使用带有Typescript模板的CRA来创建一个名为`ai-assistant-claude`的新项目。
npx create-react-app ai-assistant-claude --template typescript这个命令在当前的目录下创建一个名为 ai-assistant-claude 的新目录,其中包含一个支持Typescript的新的React应用程序
集成 TailwindCSS
本教程中的步骤基于 官方Tailwind CSS文档
(https://tailwindcss.com/docs/guides/create-react-app)。
使用如下命令进行安装
npm install -D tailwindcssnpx tailwindcss init
配置模版路径
Next, we configure our template paths by adding them to the `tailwind.config.js` file. The `++` signifies the lines you'll be adding:
请参考以下在tailwind.config.js文件中配置模板路径的步骤,++ 标记的是需要添加的代码行:
/** @type {import('tailwindcss').Config} */module.exports = {-- content: [],++ content: [++ "./src/**/*.{js,jsx,ts,tsx}",++ ],theme: {extend: {},},plugins: [],}
最后我们需要在 ./src/index.css 文件中为Tailwind的各个层添加 @tailwind 指令:
@tailwind base;@tailwind components;@tailwind utilities;
Tailwind CSS 集成完毕
安装必须的类库
在开始编程之前,先安装好必须的类库,包括`fontawesome`, `react-markdown`, `axios`, and `react-hook-form`。
安装FontAwesome
npm i --save @fortawesome/fontawesome-svg-corenpm install --save @fortawesome/free-solid-svg-iconsnpm install --save @fortawesome/react-fontawesome
安装 React Markdown
npm install --save react-markdown项目编程
为之前初始化的Flask应用程序添加新的端点`/ask`和`/search`,它们将分别用于我们的简单聊天和高级聊天功能(后者由谷歌搜索结果提供支持)。
首先导入必要的模块:
from flask import Flask, jsonify, request
from dotenv import load_dotenv
from langchain.chat_models import ChatAnthropic
from langchain.chains import ConversationChain
from langchain.agents import Tool
from langchain.agents import AgentType
from langchain.utilities import SerpAPIWrapper
from langchain.agents import initialize_agent
from langchain.memory import ConversationBufferMemory
from langchain.prompts.chat import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
load_dotenv()
app = Flask(__name__)上述代码导入需要的包,初始化Flask应用程序
开发后端
创建端点(`/`)
@app.route('/')def hello_world():return 'Hello, World!'
访问根URL, 如果显示"Hello, World!",表明程序运行成功。
创建 `/ask` 端点
这个端点会读取请求中的 JSON 数据,包含用户的消息和对话 ID。使用 LangChain 库和Claude大模型来理解消息并生成响应。
这就是一个基本的聊天机器人端点的实现。可以进一步扩展这个端点,添加更多的自然语言处理能力。
@app.route('/ask', methods=['POST'])def ask_assistant():# The code for /ask endpoint goes here
从请求中提取消息
检查并提取消息
data = request.get_json()
if not data:
return jsonify({"error": "No data provided"}), 400
messages = data.get("message")生成响应
以下代码使用LangChain的`ChatAnthropic()`模型和`ChatPromptTemplate`来生成聊天响应。对话历史记录使用`ConversationBufferMemory`来存储。
llm = ChatAnthropic()
input = ""
message_list = []
for message in messages:
if message['role'] == 'user':
message_list.append(
HumanMessagePromptTemplate.from_template(message['content'])
)
input = message['content']
elif message['role'] == 'assistant':
message_list.append(
AIMessagePromptTemplate.from_template(message['content'])
)
# Adding SystemMessagePromptTemplate at the beginning of the message_list
message_list.insert(0, SystemMessagePromptTemplate.from_template(
"The following is a friendly conversation between a human and an AI. The AI is talkative and "
"provides lots of specific details from its context. The AI will respond with plain string, replace new lines with \\n which can be easily parsed and stored into JSON, and will try to keep the responses condensed, in as few lines as possible."
))
message_list.insert(1, MessagesPlaceholder(variable_name="history"))
message_list.insert(-1, HumanMessagePromptTemplate.from_template("{input}"))
prompt = ChatPromptTemplate.from_messages(message_list)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
result = conversation.predict(input=input)发送响应
print(result)return jsonify({"status": "success", "message": result})
创建`/search` 端点/search 端点与 /ask 类似,但包含了搜索功能,可以提供更详细的回复。我们可以使用 SerpAPIWrapper 来添加这个功能
@app.route('/search', methods=['POST'])
def search_with_assistant():
data = request.get_json()
if not data:
return jsonify({"error": "No data provided"}), 400
messages = data.get("message")
llm = ChatAnthropic()
# Get the last message with 'user' role
user_messages = [msg for msg in messages if msg['role'] == 'user']
last_user_message = user_messages[-1] if user_messages else None
# If there is no user message, return an error response
if not last_user_message:
return jsonify({"error": "No user message found"}), 400
input = last_user_message['content']
search = SerpAPIWrapper()
tools = [
Tool(
name = "Current Search",
func=search.run,
description="useful for when you need to answer questions about current events or the current state of the world"
),
]
chat_history = MessagesPlaceholder(variable_name="chat_history")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
memory=memory,
agent_kwargs = {
"memory_prompts": [chat_history],
"input_variables": ["input", "agent_scratchpad", "chat_history"]
}
)
result = agent_chain.run(input=input)
print(result)
return jsonify({"status": "success", "message": result})运行 Flask App
最后添加标准的引导代码来运行Flask应用:
if __name__ == '__main__':app.run()
测试
全部的后端代码如下所示
from flask import Flask, jsonify, request
from dotenv import load_dotenv
from langchain.chat_models import ChatAnthropic
from langchain.chains import ConversationChain
from langchain.agents import Tool
from langchain.agents import AgentType
from langchain.utilities import SerpAPIWrapper
from langchain.agents import initialize_agent
from langchain.memory import ConversationBufferMemory
from langchain.prompts.chat import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
load_dotenv()
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
@app.route('/ask', methods=['POST'])
def ask_assistant():
data = request.get_json()
if not data:
return jsonify({"error": "No data provided"}), 400
messages = data.get("message")
llm = ChatAnthropic()
input = ""
message_list = []
for message in messages:
if message['role'] == 'user':
message_list.append(
HumanMessagePromptTemplate.from_template(message['content'])
)
input = message['content']
elif message['role'] == 'assistant':
message_list.append(
AIMessagePromptTemplate.from_template(message['content'])
)
# Adding SystemMessagePromptTemplate at the beginning of the message_list
message_list.insert(0, SystemMessagePromptTemplate.from_template(
"The following is a friendly conversation between a human and an AI. The AI is talkative and "
"provides lots of specific details from its context. The AI will respond with plain string, replace new lines with \\n which can be easily parsed and stored into JSON, and will try to keep the responses condensed, in as few lines as possible."
))
message_list.insert(1, MessagesPlaceholder(variable_name="history"))
message_list.insert(-1, HumanMessagePromptTemplate.from_template("{input}"))
prompt = ChatPromptTemplate.from_messages(message_list)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
result = conversation.predict(input=input)
print(result)
return jsonify({"status": "success", "message": result})
@app.route('/search', methods=['POST'])
def search_with_assistant():
data = request.get_json()
if not data:
return jsonify({"error": "No data provided"}), 400
messages = data.get("message")
llm = ChatAnthropic()
# Get the last message with 'user' role
user_messages = [msg for msg in messages if msg['role'] == 'user']
last_user_message = user_messages[-1] if user_messages else None
# If there is no user message, return an error response
if not last_user_message:
return jsonify({"error": "No user message found"}), 400
input = last_user_message['content']
search = SerpAPIWrapper()
tools = [
Tool(
name = "Current Search",
func=search.run,
description="useful for when you need to answer questions about current events or the current state of the world"
),
]
chat_history = MessagesPlaceholder(variable_name="chat_history")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
memory=memory,
agent_kwargs = {
"memory_prompts": [chat_history],
"input_variables": ["input", "agent_scratchpad", "chat_history"]
}
)
result = agent_chain.run(input=input)
print(result)
return jsonify({"status": "success", "message": result})
if __name__ == '__main__':
app.run()运行该应用
flask run命令行显示如下信息,即表示成功

现在,让我们来测试一下这两个端点 /ask 和 /search。为了区分这两个端点的功能,我们发送相似的 payload 给它们。
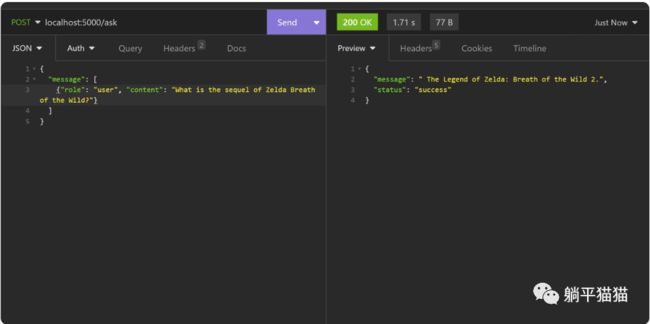
首先,我们调用 /ask 端点,发送以下 payload。问题是关于游戏“塞尔达传说-旷野之息 ”的续集,它并不会给出正确的答案。这是在意料之中的,因为这个Claude大模型只训练到2021年底,当时还没有续集的官方消息。
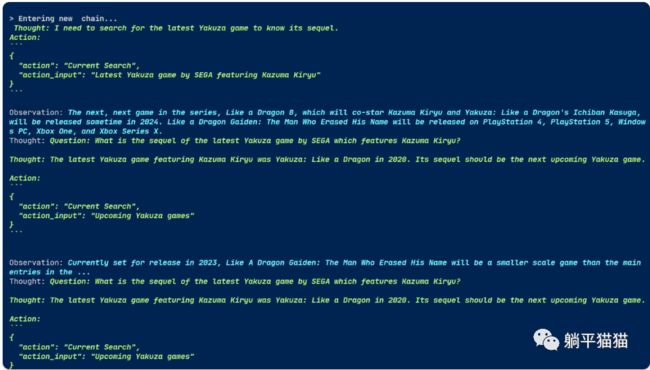
/search 端点的实现更复杂一些,它利用了 Agent。通过 Agent,我们可以给 AI 更多的决策能力,提供比仅仅使用自己的大模型更多的工具,就像上一个案例,单独的大模型存在缺陷。
下图是演示使用 `/search` 端点

答案是王国之泪,这回正确了。
其背后的工作知见下图的日志。
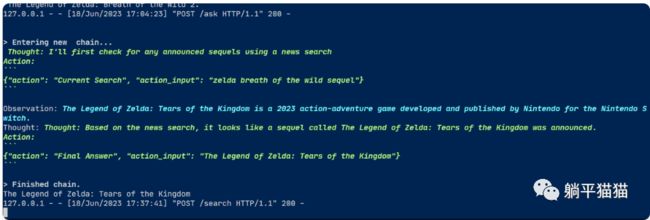
有意思的是,这次AI模型没有立即回答,而是在沉思该如何回答。它在从网页搜索结果中得出“根据新闻搜索看来已经宣布了一个名为《塞尔达传说:王国之泪》的续作”的结论后,决定给出回答
按照这个逻辑,我们难道不应该直接使用 /search 端点吗?因为它更准确,更智能?其实并不是这样。
仅仅依靠搜索引擎的结果来回答问题确实更直接和精准,但是聊天机器人还需要结合对话历史和上下文来进行推理,使对话更加连贯自然。我们不能仅仅依赖 /search 端点,还需要让机器人“记住”之前的对话,并基于这些上下文进行回答。这可以让聊天机器人更像是一个有连贯思维的个体,使沟通更加顺畅。机器人对话能力的提升不仅仅依靠提高搜索准确度,还需要结合对话上下文。
下面来实验一下/search端点能否记住之前问过的问题
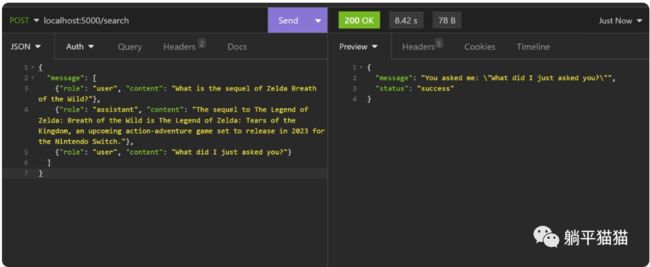
这种情况发生的原因是,LangChain库虽然有记忆链功能可以用来保留过去的对话,但构建在其上的web服务器和REST API服务本质上是无状态的。这意味着,web服务器将把每一个请求都当作一个新的请求来对待
即使我们已经将之前的对话内容放入payload了。但LangChain中使用的Agent链目前还不支持处理复合prompt,复合prompt由用户和AI的请求与响应组成。我们主要将其用来为大模型提供示例对话,进一步调整模型以产生我们期望的响应。另一方面,Agent的工作方式是接收一个单独的指令并围绕它展开思考。这就是为什么,无论我们的对话多长,agent都只会响应最新的请求。
再来看看/ask端点的反应
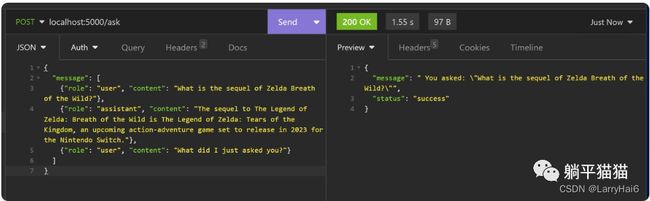
这次,它的回答是基于之前对话的上下文了。到这里我们已经意识到,我们需要用两个端点同时来构建我们的 AI 助手应用程序。但是我们如何将/ask 端点(过时但有记忆的 )与 /search 端点(健忘但最新的)结合在一起呢?方法就是构建前端。
前端可以使/ask端点提供连续对话的记忆能力和/search端点提供最新信息的能力巧妙地结合起来。
开发前端
创建文件 App.tsx
import React from 'react';
import logo from './logo.svg';
import './App.css';
import { ChatClient } from './ChatClient';
function App() {
return (
在上面的代码中,我们导入了`ChatClient`组件,这个组件会在后续步骤中创建。然后我们在`
创建文件 ChatClient.tsx
import React, { useState } from 'react';
import { ChatInput } from './ChatInput';
import { ChatHistory } from './ChatHistory';
export interface Message {
content: string;
role: string;
}
export const ChatClient: React.FC = () => {
const [messages, setMessages] = useState>([]);
const [isLoading, setIsLoading] = useState(false)
const handleSimpleChat = (message: string) => {
// Send the message and past chat history to the backend
// Update messages state with the new message
let newMessages = [...messages, { content: message, role: 'user' }]
setMessages(newMessages);
let postData = {
message: newMessages
}
setIsLoading(true)
fetch('/ask', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => {
if (data.status === "success") {
setMessages([...newMessages, { content: data.message, role: 'assistant' }])
}
setIsLoading(false)
console.log('Success:', data);
})
.catch((error) => {
console.error('Error:', error);
setIsLoading(false)
});
};
const handleAdvancedChat = (message: string) => {
// Trigger AI agent with Google Search functionality
// Update messages state with the new message and AI response
let newMessages = [...messages, { content: message, role: 'user' }]
setMessages(newMessages);
let postData = {
message: newMessages
}
setIsLoading(true)
fetch('/search', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => {
if (data.status === "success") {
setMessages([...newMessages, { content: data.message, role: 'assistant' }])
}
console.log('Success:', data);
setIsLoading(false)
})
.catch((error) => {
console.error('Error:', error);
setIsLoading(false)
});
};
return (
AI Assistant with Claude and LangChain
这个组件是我们AI助手的主用户界面。它包含了一个`ChatHistory`组件来显示对话历史,和一个`ChatInput`组件用于输入文本。这个组件会处理来自`ChatInput`的输入,然后向后端发送请求,显示加载状态。如果请求成功的话,该组件还将显示从后端收到的响应。
创建文件 ChatHistory.tsx
import React from 'react';
import { ReactMarkdown } from 'react-markdown/lib/react-markdown';
import { Message } from './ChatClient';
interface ChatHistoryProps {
messages: Array;
isLoading: boolean
}
export const ChatHistory: React.FC = ({ messages, isLoading }) => {
return (
{messages.map((message, index) => (
{message.content}
))}
{isLoading && (
{/* Put your desired loading content here */}
Thinking...
)}
);
}; 幸运的是,TailwindCSS提供了内置的工具类可以实现简单的动画,比如 animate-pulse。这个类可以优雅地表示一个请求正在等待响应。在这个组件中,我们还将“用户”和“助手”消息的位置分开了。
创建文件 ChatInput.tsx
import React, { useState } from 'react';
interface ChatInputProps {
onSimpleChat: (message: string) => void;
onAdvancedChat: (message: string) => void;
}
export const ChatInput: React.FC = ({ onSimpleChat, onAdvancedChat }) => {
const [input, setInput] = useState('');
const handleInputChange = (event: React.ChangeEvent) => {
setInput(event.target.value);
};
const handleSubmit = (handler: (message: string) => void) => {
handler(input);
setInput('');
};
return (
);
}; 最后,我们在文本输入框添加了两个按钮。第一个按钮用于将输入内容发送到`/ask`端点,该端点将使用AI大模型处理输入,并没有做任何额外的增强。这个端点是具有上下文意识的。第二个按钮名称为“询问并搜索”,它会将输入内容发送到`/search`端点。除了通过AI大模型处理输入之外,如果情况需要,这个按钮还会触发AI驱动的网络搜索。
创建文件 index.html
-- React App
++ Claude AI Assistant
在`index.html`页面中更新应用的标题,改为“Claude AI助手”
创建文件 package.json
{"name": "ai-assistant-claude","version": "0.1.0","private": true,++ "proxy": "http://localhost:5000","dependencies": {
最后,在`package.json`文件中添加了一个代理配置,并将其设置为`http://localhost:5000`。这有助于我们绕过使用不同端口所产生的CORS限制
测试 AI 助手 App
启动后端程序
npm start在浏览器中访问 `localhost:3000`.

测试的问题是, 如龙游戏的续作(2021年还没有宣布发布)。另外,还要问这个游戏是否会包含前作中深受玩家喜爱的桐生一马。点击“询问”按钮

等待中
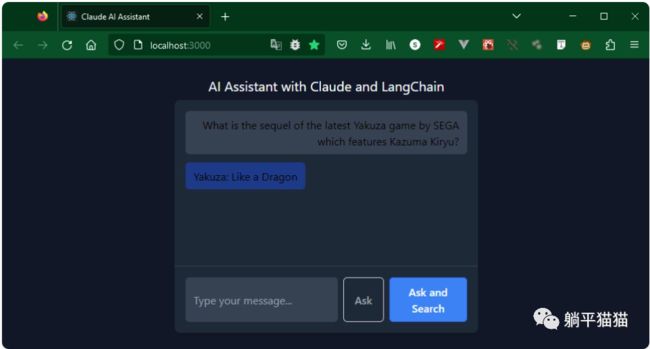
AI的回答显然错了。《如龙:Like a Dragon》确实是最新的如龙游戏,但主角是春日一番,不是桐生一马。我们再来重新提问,这次使用“询问并搜索”按钮。
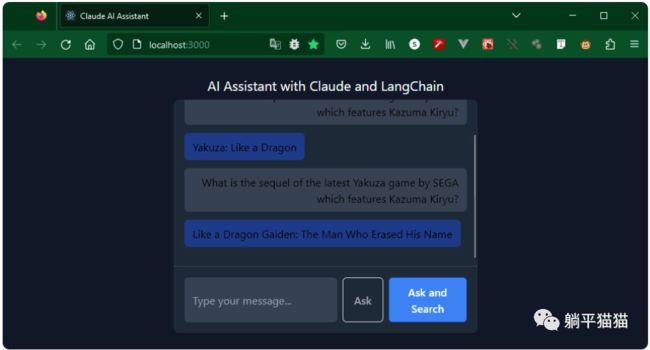
这次,AI花费了更长的时间来决定是否需要搜索网络。在确定需要进行网络搜索并找到满意的答案后,它将信息返回给了前端
这回的答案是对的,感兴趣的可以自行搜索下官方的宣传进行对照。我对日本游戏不太有研究,不强行翻译游戏名称了。
这个由大型语言模型驱动的代理可以根据可用的资源(搜索)预测下一步的操作,并给出满意的答案。LangChain的封装,使得对“链式”模型、提示以及代理其他工具的应用变得异常简单。
总结
本次教程中,我们展示了LangChain与Claude大语言模型结合使用时的强大威力。强调了LangChain的关键特性,如提示模板、模型、记忆和代理。有了这种通用抽象,可以轻松快捷的将各种AI大模型集成起来以驱动应用的AI化。
一开始,展示了使用默认提示来创建AI助手是多么简单,方法是链式调用对话历史,并通过`/ask`端点发送给大模型。然后继续展示了AI代理在做出特定决策方面的能力。在`/search`端点,我们向助手提出了问题,同时提供了搜索工具来进一步在互联网上探索满意的答案。
LangChain提供了一个通用的抽象层,使构建AI应用变得异常简单。我们仅仅接触了LangChain能力的冰山一角。更多信息请访问LangChain的GitHub仓库。