redis 配置主从复制,哨兵模式案例
哨兵(Sentinel)模式
1 . 什么是哨兵模式?
反客为主的自动版,能够自动监控master是否发生故障,如果故障了会根据投票数从slave中挑选一个
作为master,其他的slave会自动转向同步新的master,实现故障自动转义
2 . 原理
-
sentinel会按照指定的频率给master发送ping请求,看看master是否还活着,若master在指定时间内未
正常响应sentinel发送的ping请求,sentinel则认为master挂掉了,但是这种情况存在误判的可能,比
如:可能master并没有挂,只是sentinel和master之间的网络不通导致,导致ping失败。 -
为了避免误判,通常会启动多个sentinel,一般是奇数个,比如3个,那么可以指定当有多个sentinel都
觉得master挂掉了,此时才断定master真的挂掉了,通常这个值设置为sentinel的一半,比如sentinel
的数量是3个,那么这个量就可以设置为2个 -
当多个sentinel经过判定,断定master确实挂掉了,接下来sentinel会进行故障转移:会从slave中投票
选出一个服务器,将其升级为新的主服务器, 并让失效主服务器的其他从服务器slaveof指向新的主服务 器;
当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以 使用新主服务器代替失效服务器。
操作流程
1. 案例 - 配置1主2从3个哨兵
下面我们来实现1主2从3个sentinel的配置,当从的挂掉之后,要求最少有2个sentinel认为主的挂掉了,才进行故障转移。
为了方便,我们在一台机器上进行模拟,我的机器ip是:192.168.200.129,通过端口来区分6个不同的
节点(1个master、2个slave、3个sentinel),节点配置信息如下
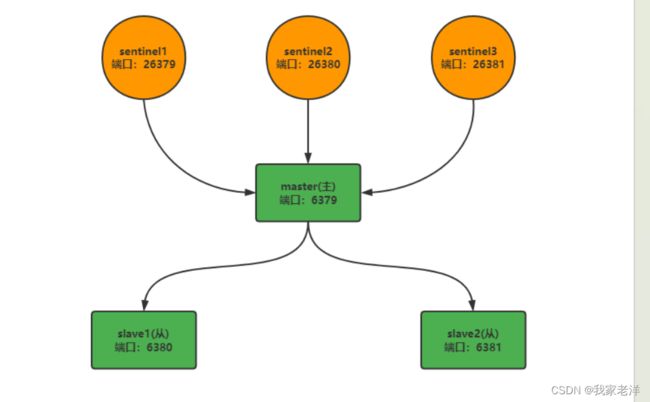
2 . 创建案例工作目录:sentinel
执行下面命令创建 /opt/sentinel 目录,本次所有操作,均在 sentinel 目录进行。
# 方便演示,停止所有的redis
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
mkdir /opt/sentinel
cd /opt/sentinel/
3 . 将redis.conf复制到sentinel目录
redis.conf 是redis默认配置文件
cp /opt/redis-6.2.1/redis.conf /opt/sentinel/
4 . 创建master的配置文件:redis-6379.conf
在/opt/sentinel目录创建 redis-6379.conf 文件,内容如下,注意 192.168.200.129 是这个测试机器
的ip,大家需要替换为自己的
include /opt/sentinel/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/sentinel/
port 6379
dbfilename dump_6379.rdb
pidfile /var/run/redis_6379.pid
logfile "./6379.log"
5 . 创建slave1的配置文件:redis-6380.conf
在/opt/sentinel目录创建 redis-6380.conf 文件,内容如下,和上面master的类似,只是将6379换成6380了
include /opt/sentinel/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/sentinel/
port 6380
dbfilename dump_6380.rdb
pidfile /var/run/redis_6380.pid
logfile "./6380.log"
6 .创建slave2的配置文件:redis-6381.conf
在/opt/sentinel目录创建 redis-6381.conf 文件,内容如下**
include /opt/sentinel/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/sentinel/
port 6381
dbfilename dump_6381.rdb
pidfile /var/run/redis_6381.pid
logfile "./6381.log"
7 . 启动master、slave1、slave2
redis-server /opt/sentinel/redis-6379.conf
redis-server /opt/sentinel/redis-6380.conf
redis-server /opt/sentinel/redis-6381.conf
8 . 配置slave1为master的从库
(1)执行下面命令,连接slave1
redis-cli -h 192.168.200.129 -p 6380
(2)执行下面命令,指定slave1的作为master的从机
slaveof 192.168.200.129 6379
(3)如下,使用 info replication 查看下slave1的主从信息

9 . 配置slave2为master的从库
(1)执行下面命令,连接slave2
redis-cli -h 192.168.200.129 -p 6381
(2)执行下面命令,指定slave2的作为master的从机
slaveof 192.168.200.129 6379
(3)如下,使用 info replication 查看下slave2的主从信息
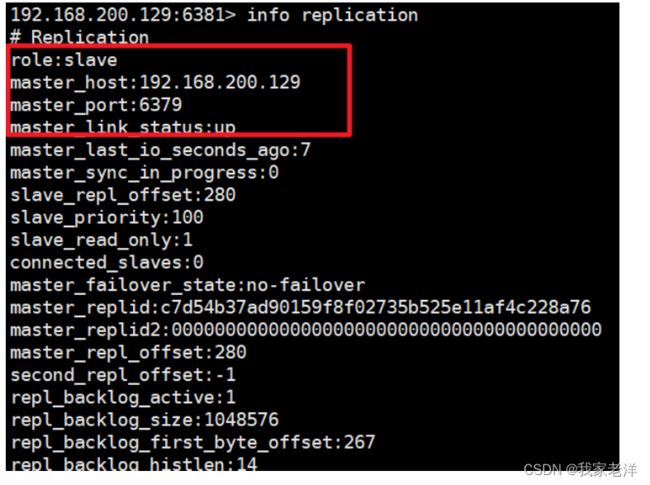
10 . 验证主从复制是否正常
10.1 运行下面命令,连接master
redis-cli -h 192.168.200.129 -p 6379
10.2 运行下面命令,查看master主从信息
info replication
slave2 信息
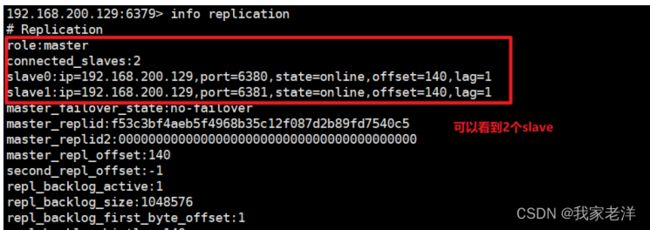
10.3 在master中执行下面命令,写入数据
flushdb
set name jack
10.4 如下,查看slave1中name的值
192.168.200.129:6381> get name
"jack"
数据一致,说明同步正常
11 .创建sentinel1的配置文件:sentinel-26379.conf
在/opt/sentinel目录创建 sentinel-26379.conf 文件,内容如下
# 配置文件目录
dir /opt/sentinel/
# 日志文件位置
logfile "./sentinel-26379.log"
# pid文件
pidfile /var/run/sentinel_26379.pid
# 是否后台运行
daemonize yes
# 端口
port 26379
# 监控主服务器master的名字:mymaster,IP:192.168.200.129,port:6379,最后的数字2表示当
Sentinel集群中有2个Sentinel认为master存在故障不可用,则进行自动故障转移
sentinel monitor mymaster 192.168.200.129 6379 2
# master响应超时时间(毫秒),Sentinel会向master发送ping来确认master,如果在20秒内,ping
不通master,则主观认为master不可用
sentinel down-after-milliseconds mymaster 60000
# 故障转移超时时间(毫秒),如果3分钟内没有完成故障转移操作,则视为转移失败
sentinel failover-timeout mymaster 180000
# 故障转移之后,进行新的主从复制,配置项指定了最多有多少个slave对新的master进行同步,那可以理
解为1是串行复制,大于1是并行复制
sentinel parallel-syncs mymaster 1
# 指定mymaster主的密码(没有就不指定)
# sentinel auth-pass mymaster 123456
12 . 创建sentinel2的配置文件:sentinel-26380.conf
在/opt/sentinel目录创建 sentinel-26380.conf 文件,内容如下
# 配置文件目录
dir /opt/sentinel/
# 日志文件位置
logfile "./sentinel-26380.log"
# pid文件
pidfile /var/run/sentinel_26380.pid
# 是否后台运行
daemonize yes
# 端口
port 26380
# 监控主服务器master的名字:mymaster,IP:192.168.200.129,port:6379,最后的数字2表示当
Sentinel集群中有2个Sentinel认为master存在故障不可用,则进行自动故障转移
sentinel monitor mymaster 192.168.200.129 6379 2
# master响应超时时间(毫秒),Sentinel会向master发送ping来确认master,如果在20秒内,ping
不通master,则主观认为master不可用
sentinel down-after-milliseconds mymaster 60000
# 故障转移超时时间(毫秒),如果3分钟内没有完成故障转移操作,则视为转移失败
sentinel failover-timeout mymaster 180000
# 故障转移之后,进行新的主从复制,配置项指定了最多有多少个slave对新的master进行同步,那可以理
解为1是串行复制,大于1是并行复制
sentinel parallel-syncs mymaster 1
# 指定mymaster主的密码(没有就不指定)
# sentinel auth-pass mymaster 123456
13 . 创建sentinel3的配置文件:sentinel-26381.conf
在/opt/sentinel目录创建 sentinel-26381.conf 文件,内容如下
# 配置文件目录
dir /opt/sentinel/
# 日志文件位置
logfile "./sentinel-26381.log"
# pid文件
pidfile /var/run/sentinel_26381.pid
# 是否后台运行
daemonize yes
# 端口
port 26381
# 监控主服务器master的名字:mymaster,IP:192.168.200.129,port:6379,最后的数字2表示当
Sentinel集群中有2个Sentinel认为master存在故障不可用,则进行自动故障转移
sentinel monitor mymaster 192.168.200.129 6379 2
# master响应超时时间(毫秒),Sentinel会向master发送ping来确认master,如果在20秒内,ping
不通master,则主观认为master不可用
sentinel down-after-milliseconds mymaster 60000
# 故障转移超时时间(毫秒),如果3分钟内没有完成故障转移操作,则视为转移失败
sentinel failover-timeout mymaster 180000
# 故障转移之后,进行新的主从复制,配置项指定了最多有多少个slave对新的master进行同步,那可以理
解为1是串行复制,大于1是并行复制
sentinel parallel-syncs mymaster 1
# 指定mymaster主的密码(没有就不指定)
# sentinel auth-pass mymaster 123456
14 . 分别查看3个sentinel的信息
14.1 分别对3个sentinel执行下面命令,查看每个sentinel的信息
redis-cli -p sentinel的端口
info sentinel
14.2 sentinel1 的信息如下,其他2个sentinel的信息这里就不列了,大家自己去看一下
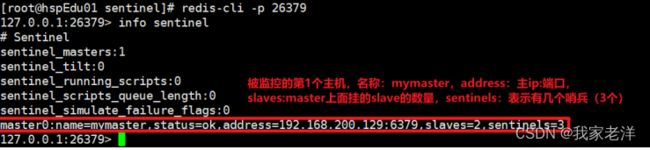
15 . 验证故障自动转移是否成功
step1:在master中执行下面命令,停止master
192.168.200.129:6379> shutdown
step2:等待2分钟,等待完成故障转移
step2:等待2分钟,等待完成故障转移
sentinel中我们配置 down-after-milliseconds 的值是60秒,表示判断主机下线时间是60秒,所以我们
等2分钟,让系统先自动完成故障转移。
step3:查看slave1的主从信息,如下
使用 info replication 命令查看主从信息
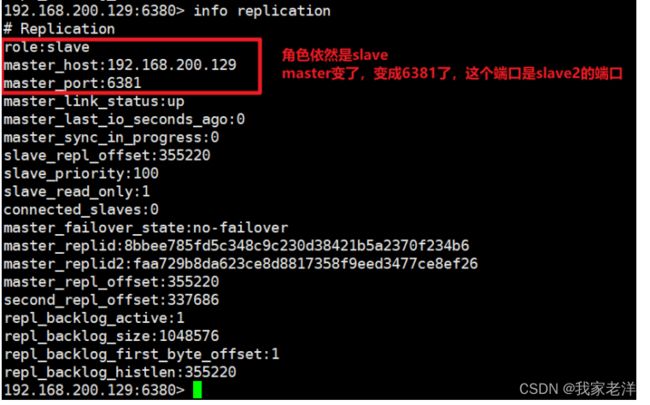
step4:查看slave2的主从信息,如下
slave2变成master了,且slave2变成slave1的从库了,完成了故障转移。

step5:下面验证下slave1和slave2是否同步
在slave2中执行下面命令
192.168.200.129:6381> set address china
OK
在slave1中执行下面命令,查询一下address的值,效果如下,说明slave2和slave1同步正
16 . 恢复旧的master自动俯首称臣
当旧的master恢复之后,会自动挂在新的master下面,咱们来验证下是不是这样的。
step1:执行下面命令,启动旧的master
redis-server /opt/sentinel/redis-6379.conf
step2:执行下面命令,连接旧的master
redis-cli -h 192.168.200.129 -p 6379```
step3:执行下面命令,查看其主从信息
info replication
效果如下,确实和期望的一致。

17 . 更多Sentinel介绍
关于sentinel更多信息,见:http://itsoku.com/article/247