聊聊主流的分布式数据库
单体数据库时代,随着系统交易量的不断上升,数据库读写性能出现了严重下降。我们可以借助分库分表中间件,比如mycat、shardingjdbc来实现分库分表,缓解单库的读写性能。但是分库分表中间件并不支持事务,如果要保证数据一致性,就需要借助于分布式事务中间件,比如阿里巴巴的seata。后来分布式数据库逐渐成为解决数据一致性的选择,目前分布式数据库产品已经比较成熟,支持ACID事务,本文就来聊一聊分布式数据库。
增加代理层
以mysql为例,我们来看一下单体数据库的逻辑架构,如下图:
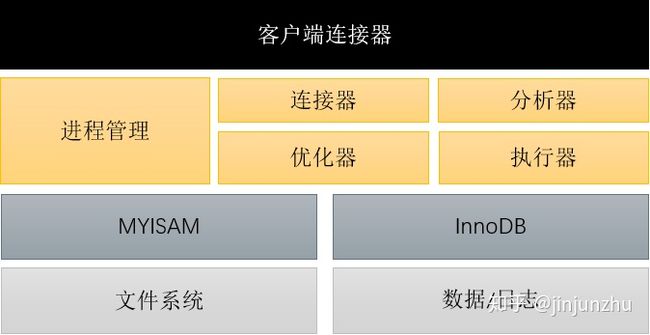
从这个图我们可以看到,mysql包括连接器层,server层,存储引擎层和数据/文件层。单体数据库场景下,数据库本身就是支持事务的,我们不用事务做额外的工作。
如果需要分库分表,这时架构就需要调整,如下图:
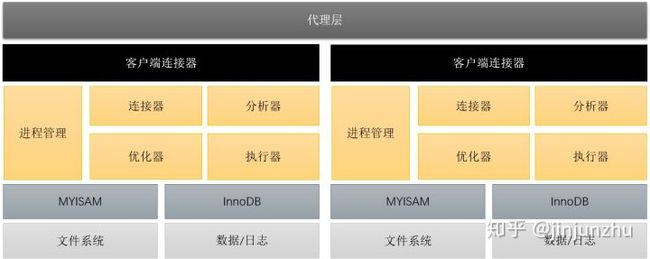
这个架构增加了代理层,它的功能包括客户端接入、简单的查询处理、进程管理和分片信息管理。这时因为数据分布在不同的切片上,使用的复杂性也大幅度增加。
如果应用要进行全量分页查询、关联查询、排序等应用,一个简单的代理层是很难满足的,代理层必须支持复杂的运算,这时就基本过度到分布式数据库了,而代理层也被叫做了协调节点。
协调节点增加了运算能力,但是要支持分布式事务的一致性,还是远远不够的。下面我们就看一下一致性问题。
一致性
在分布式的CAP理论中,数据一致性是终极目标。我们来聊一下线性一致性和因果一致性。
先看线性一致性,如下图:

user1读取足球比赛成绩,比分4:2,1秒之后,user2读取比赛成绩,但user2读到的成绩是4:1,这样后读取的用户读取到的数据反而是旧的数据。
发生这个问题的原因就是多副本同步延迟,而线性一致性要解决的问题如下:
- 用户的读写请求顺序与实际的时间相一致
- 如果user1读取某一个key之前user2已经修改了key,那user1读取到的值一定是user2修改后的值
线性一致性是分布式下最强的一致性理论,主流的数据库产品解决线程一致性的手段是引入全局时钟,用单点授时的方式,从这个单一节点获取时间,而且必须保证单一时钟节点的高可靠性。
线性一致性的问题是全局时钟的并发问题,如果共用一个物理时钟,性能必然受到影响。
如果我们在一致性和高性能之间做一个取舍,我们可以降低一些一致性来提高并发性能。这个理论就是因果一致性,它一致性要求低于线性一致性。因为一致性的基础是在数据库的单一切片上,事件肯定是有先后顺序的。在不同的切片上,需要通信的话,发送事件肯定早于接收事件。
基于因果一致性,引入了逻辑时钟的概念。目前也有一些数据库使用逻辑时钟来实现因果一致性,虽然比线性一致性弱一些,但是性能更好。
NewSQL架构
上面我们介绍了传统关系型数据库,增加了切片集群,增加了协调节点,增加了全局时钟,这样就演变成了分布式数据库。如下图:

这种数据库架构被业内称为PGXC架构,这个名字是PostgreSQL-XC的简称,它是一种提供写可靠性,多主节点数据同步,数据传输的开源集群方案。
注意:这种架构被叫做PGXC,并不是专指PostgreSQL-XC这种分布式数据库,而是文章上面讲的架构风格的一类数据库。
NewSQL是由NoSQL键值数据库发展而来,它是一类新的数据库架构方案,不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。它主要有以下特性:
- 放弃了PGXC架构中单体数据库的事务支持
- 在BigTable基础上构建了事务支持
- 引入分片机制,主要采用Range动态分片技术,跟HASH分片相比,数据可以不用固定的在某一个分片上
- 可靠性方面,放弃传统数据库的主从复制,采用Paxos、Raft等共识算法来保证HA
- 存储引擎方面,使用LSM-Tree替换B+树模型,写入性能更高
- 支持事务管理
PGXC数据库
PGXC数据库由传统关系型数据库基于分库分表的技术演化而来,优点是性能比较稳定,缺点是写入能力有限,这是由架构风格决定的。
我们来介绍几款主流的PGXC数据库,代表如下:
1.TBase
TBase是腾讯数据平台团队在基于PostgreSQL研发的,支持HTAP(Hybrid Transaction and Analytical Process),主要由协调节点、数据节点和全局事务管理器(GTM)组成。特点如下:
- 分布式事务支持RC和RR两个隔离级别
- 支持高性能分区表,数据检索效率高
- SQL语法兼容SQL2003标准、也支持PostgreSQL语法和Oracle主要语法
开源地址:
https://gitee.com/mirrors/tbase2.GuassDB 300
GuassDB 300由华为研发,也是基于开源PostgreSQL研发的,支持HTAP,支持SQL92、SQL99和SQL2003语法,并且支持提供存储过程、触发器、分页等。目前在招商银行、工商银行和民生银行有使用。
3.AntDB
由亚信科技开发,基于开源PostgreSQL内核研发的,主要特点是对Oracle兼容性高,分布式事务支持2PC协议和MVCC,集群支持动态扩展。
开源地址:
https://gitee.com/adbsql/antdb4.GoldenDB
由中兴通讯研发,跟前面3款不一样的是,这款数据库以mysql为内核构建的,按照官方的描述,这款数据库对金融行业的支持比较好,目前中信银行的核心业务系统有使用。
5.TDSQL
TDSQL由腾讯研发,它算不上是完全的PGXC架构,因为没有全局时钟。不过它也有自己解决一致性的方案,它的自增长序列为用户提供一个全局唯一数字ID服务,对全局锁和mvcc都有一定的作用。
NewSQL数据库
NewSQL数据库有很大的架构上的优势,但是首先难度也很大,我们来看一下目前主流的数据库产品。
1.谷歌Spanner
谷歌Spanner可以说是NewSQL数据库的鼻祖,后来的好多数据库都是借鉴了Spanner的思想。它有下面几个特性:
- 使用GPS加原子钟的方式来实现全局时钟,这就就是引入了true time,支持全球化部署
- 支持线性一致性
2.TiDB
TiDB也是非常有名的一块NewSQL数据库,由PingCAP研发,支持HTAP,支持线性一致性,一个亮点是兼容mysql协议和生态,github地址如下:
https://github.com/pingcap3.Ocean Base
蚂蚁集团研发,按照官方说法,2020年5月,OceanBase以7.07亿tpmC的在线事务处理性能,打破了去年自己创造的TPC-C 世界纪录。截止至目前,OceanBase 是第一个也是唯一一个上榜的中国数据库。
虽然官方说Ocean Base高度兼容各种主流关系型数据库,但是业界普遍认为对Oracle兼容不太好。
采用Paxos分布式选举算法来实现高可用。
4.SequoiaDB
巨杉金融级分布式数据库,它具有如下特性:
- 完整支持分布式事务、强一致、多副本高可用,满足分布式核心交易业务需求
- 支持 MySQL、PostgreSQL、SparkSQL 和 MariaDB 四种关系型数据库实例,100%兼容MySQL语法
- 支持HTAP混合事务/分析处理
目前在广发、民生等金融机构有一定使用。
5.CockroachDB和YugabyteDB
这2个数据库放在一起讲的原因是它们不支持线性一致性,只支持因果一致性,因为它们使用的是混合逻辑时钟(Hybrid Logical Clocks),它们的设计思想都是来自Spanner。
CockroachDB采用了Range分区,同时使用raft算法的改进算法multi raft,每个Range对应的是一个Raft Group,让多分片并行处理提升性能。
YugabyteDB除了NewSQL的特性外,还支持文档数据库接口,查询层支持同时SQL和CQL两种API,SQL API是基于postgreSQL改的,所以对postgreSQL的支持非常好。
Aurora数据库
Aurora数据库是amazon推出的云原生数据库,它的特点是计算节点垂直扩展,存储节点可以水平扩展。可见计算节点依然是单节点。Aurora基于mysql引擎构建,100%支持mysql。
Aurora数据缓存在主节点,然后同步到其他从节点,可见跟其他分布式数据库相比,从节点不支持写入,所以不支持多写,从节点只能分担读的压力。
不过这也是一种风格,目前这个风格的数据库有阿里的polarDB,腾讯的CynosDB和华为的Taurus。
总结
传统的分库分表架构不断演进,增加了协调节点,全局时钟,就演变成了PGXC架构,这是主流分布式数据库的一个分支。
在基于BigTable键值数据库的基础上增加事务支持,就演变成了NewSQL,是分布式数据库的另一个分支。
amazon推出Aurora分布式数据库并不算是上面2种架构的一种,并没有解决分布式场景下的写入压力,但也是一种分布式数据库的风格。
分布式数据库的产品已经很成熟,数量也很多,需要结合业务特性来做技术选型。