Python开发与应用实验2 | Python基础语法应用
*本文来自博主对专业课 Python开发与应用 实验部分的整理与解析。
*一些题目可能会增加了拓展部分(⭐)。拓展部分不是实验报告中原有的内容,而是博主本人的补充,以便各位学习参考。
*实验环境为:Python 3.10 , PyCharm 2022.3
*为防雷同,实验总结部分不与代码共同分享。
目录
一、实验目的
二、实验内容
1、学生宿舍信息输入
2、超市抹零
3、个人用户登录
4、模拟斐波那契数列输出
5、银行金额大写汉字转换
6、天天向上的力量
7、一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?
⭐判断一个数是否是完全平方数
8、一个雇员一周的总薪水
⭐格式化字符串以保留两位小数
9、水仙花数是3位整数(100-199),它的各位数字立方和等于该数本身。请编写程序。
10、过滤敏感词
⭐正则表达式
一、实验目的
(1)能够使用分支结构和循环结构编写简单程序;
(2)能够使用math库进行简单的数值计算;
(3)通过设计型实验方式,结合具体的应用场景和业务需求,引导学生进行关键的技术分析,帮助学生理清编程思路,最后熟练运用 Python 语言进行程序设计,培养的了学生针对一般问题自主进行分析问题和解决问题的能力。
二、实验内容
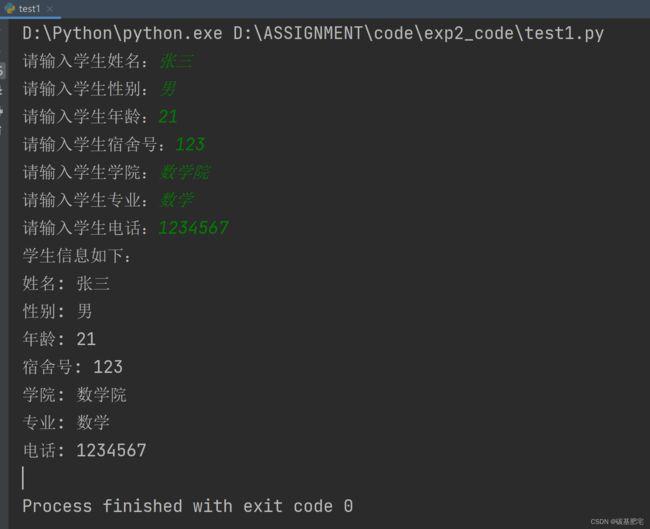
1、学生宿舍信息输入
模拟学生宿舍信息输入,需要输入学生个人信息 姓名、性别、年龄、宿舍号、学院、专业、电话信息,并输出显示。
本题练习输入输出函数input()与print()。注意input()函数接收到的是一个String。
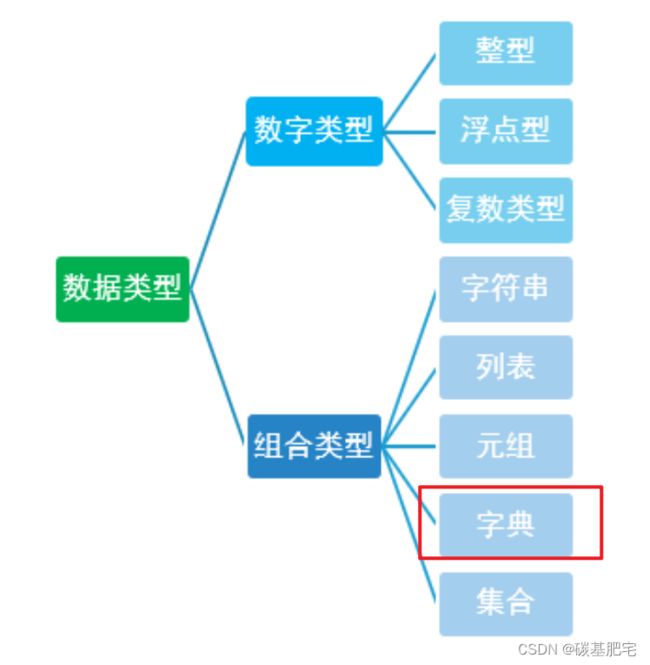
以及,在存储学生信息时,最好采用字典(dictionary)的方式:
d = {
key1 : value1,
key2 : value2,
key3 : value3
}
这里对字典这一数据类型做一些补充:
-
在p ython 中,字典是一系列键值对(即哈希表这一数据结构)。
-
可以将任何python对象作为字典的值(字典可以存储任意类型对象 )。
-
键是唯一的。如果在定义字典的时候定义的两个键值对具有相同的键,那么取后一个键的值。(同样的键,靠后的值会覆盖靠前的值)
-
键必须是不可变的,如字符串,数字或元组。(python常见的数据类型中, 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组); 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合))。
- 值不需要唯一,值也可以取任何数据类型(没有可变不可变这个要求)。
- 字典:Python 字典(Dictionary) | 菜鸟教程
下面定义了两个函数,来封装print()和input()的逻辑。程序里通过了调用函数来实现逻辑(下同),不过这个不是必要的,仅仅是博主本人的代码风格。
使用 def 关键词开头定义函数,return返回一个值。不带参数值的return语句返回None。
源代码:
def input_student_info():
name = input("请输入学生姓名:")
gender = input("请输入学生性别:")
age = input("请输入学生年龄:")
dormitory_number = input("请输入学生宿舍号:")
college = input("请输入学生学院:")
major = input("请输入学生专业:")
phone = input("请输入学生电话:")
student_info = {
"姓名": name,
"性别": gender,
"年龄": age,
"宿舍号": dormitory_number,
"学院": college,
"专业": major,
"电话": phone
}
return student_info
def display_student_info(student_info):
# 输出学生信息
print("学生信息如下:")
for key, value in student_info.items():
print(f"{key}: {value}")
if __name__ == "__main__":
student_info = input_student_info()
display_student_info(student_info)
列出测试数据和实验结果截图:
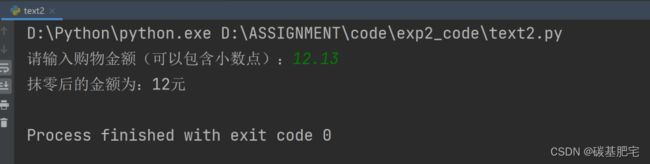
2、超市抹零
逛超市购物结账的时候,商家都会给顾客回馈一张清单小票,票面上的金额往往会精确到角或分。大部分商家通常会采用四舍五入的原则进行结算,不过有些商家为了让利顾客,会将小数点后面的数字金额全部抹零。下面使用数字类型转换实现收银抹零行为。
源代码:
amount = float(input("请输入购物金额(可以包含小数点):"))
rounded_amount = int(amount)
print(f"抹零后的金额为:{rounded_amount}元")这里要注意input函数输入时,如果希望输入的是一个数字,那么需要用int()或float()进行转化。

注意:有些同学可能会直接这样写:
amount = int(input("请输入购物金额(可以包含小数点):"))
print(f"抹零后的金额为:{amount}元")这样偷懒是不可取的:
 抛出了异常:ValueError 传入无效参数。Python使用被称为异常的特殊对象来管理程序执行期间发生的错误。这里表示试图将一个与数字无关的类型转化为整数,抛出了ValueError异常。int()可以将一个指定进制的数字型字符串或者十进制数字转化为整形,详见:Python int函数-CSDN博客
抛出了异常:ValueError 传入无效参数。Python使用被称为异常的特殊对象来管理程序执行期间发生的错误。这里表示试图将一个与数字无关的类型转化为整数,抛出了ValueError异常。int()可以将一个指定进制的数字型字符串或者十进制数字转化为整形,详见:Python int函数-CSDN博客
(异常可以用 try-except 进行处理。)
列出测试数据和实验结果截图:
3、个人用户登录
当用户登录时给3次机会。如果成功,显示欢迎xxx。如果登录失败,显示录入错误你还有x次机会。如果3次机会使用完毕,则显示登录超限,请明天再登录。
分支if和循环while的简单使用。要注意python里面布尔表达式的运算符是and,or,not,不要写成其它语言的与或非运算符了。

源代码:
def login(username, password):
correct_username = "user" # 正确的用户名
correct_password = "123" # 正确的密码
if username == correct_username and password == correct_password:
return True
else:
return False
def main():
login_attempts = 3 # 允许尝试的次数
while login_attempts > 0:
username = input("请输入用户名:")
password = input("请输入密码:")
if(login(username,password)):
print(f"欢迎{username}!")
break
else:
login_attempts -= 1
if login_attempts > 0:
print(f"登录错误,你还有 {login_attempts} 次机会。")
else:
print("登录超限,请明天再登录。")
if __name__ == "__main__":
main()
login()的返回语句也可以简化为:
return username == correct_username and password == correct_password列出测试数据和实验结果截图:
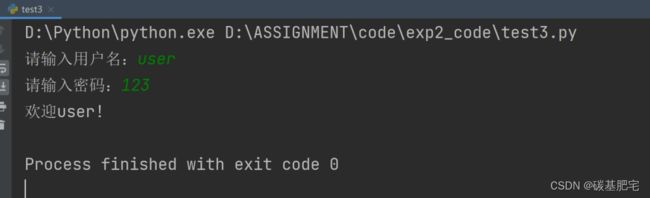
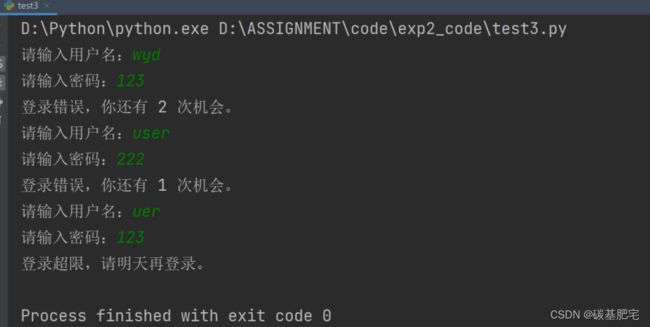
4、模拟斐波那契数列输出
用户输入指定的数列范围,正确输出结果。
斐波那契数列的规则这里不说了,不熟悉的朋友可以自己百度或看这篇文章的前言部分:青蛙跳台阶:我如何得知它是一道斐波那契数列题?——应用题破题“三板斧”_青蛙跳台阶和斐波拉契_碳基肥宅的博客-CSDN博客
题意是输入要生成的斐波那契数列的项数,然后返回从第1项到第n项的列表。这段逻辑很简单。这里贴上Java语言版本:
public class Solution {
public static void fib(int[] nums, int n){
nums[0] = 0;
nums[1] = 1;
for (int i = 2; i < n; i++) {
nums[i] = nums[i-1] + nums[i-2];
}
}
}
Java里采用数组和循环,类比到python,可以采用列表(List)和循环。我们可以定义一个函数fib()来完成这个操作:
def fib(n):
a, b = 0, 1
result = []
for _ in range(n):
result.append(a)
a = b
b = a + b
return result关于列表:Python 列表(List) | 菜鸟教程
关键在于python中的列表是可变数据。通过append函数可以在原列表中直接追加值。a表示第n项斐波那契数的值,b则用来让a迭代。
a = b
b = a + b
等价于
a, b = b, a + bfor循环的语法是 for 循环变量 in 可遍历序列 。由于循环变量在循环体中并不用到,所以用下划线作为占位符。
源代码:
def fib(n):
a, b = 0, 1
result = []
for _ in range(n):
result.append(a)
a, b = b, a + b
return result
if __name__ == "__main__":
n = int(input("请输入要生成的斐波那契数列项数:"))
sequence = fib(n)
print(f"斐波那契数列前 {n} 项为:{sequence}")
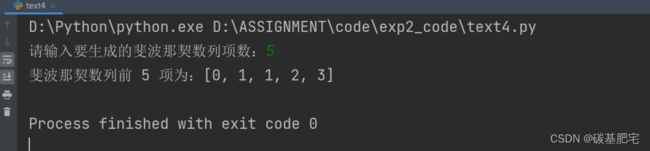
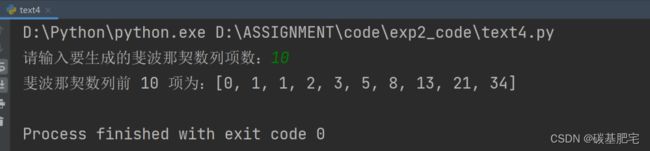
5、银行金额大写汉字转换
银行电子支票业务在金额部分需要使用大写的汉字,因此需要将用户录入的数字信息转变为汉字。目前只需完成1~5位整数转换即可。
1. 采取字典类型来建立数字与汉字之间的关系:
chinese_dict = {
0: "零",
1: "壹",
2: "贰",
3: "叁",
4: "肆",
5: "伍",
6: "陆",
7: "柒",
8: "捌",
9: "玖"
}
unit_dict = {
0: "",
1: "拾",
2: "佰",
3: "仟",
4: "万"
}2. 因为字符串 String 是不可变的类型,因此采用列表来存储结果:
result = [] # 记录结果3. 从低位到高位取出number中各数位上的数(注意,由于是从低位到高位操作数位,因此存储到result中的值是倒序的,最后还需要将result中的值reverse):
digit = number % 10
4. 对digit进行处理:根据digit的值将数字转换成汉字以及对应的单位。
if digit != 0:
# 结果=汉字+单位
result.append(chinese_dict[digit] + unit_dict[position])
else:
# 拼接零的条件
if result and result[-1] != "零":
result.append("零")一般情况下,结果就是汉字和单位进行拼接。比如123 -> 壹佰贰拾叁。但是也有一些特殊情况:
- 数字0开头。比如用户输入001,那么输出应该是壹,而不是零零壹。【对应result为空】
- 有连续多个数字0。比如1001,应该输出壹仟零壹,而不是壹仟零零壹。【对应result的最后一位已是零】
只有不满足上面这两种情况时,才能够拼接汉字零。因此只需检查当digit为0时result的情况即可。
if result and result[-1] != "零" 该条语句的含义是:如果result不为空(因为空列表会被视为假,非空列表视为真)且result的最后一位不为“零”。
5. 最终结果时,要将列表 [] 转换成 String,可以使用字符串的内建函数 join():
![]()
在合并时别忘了result列表中的元素是倒序的,可以通过字符串切片来reverse,得到最后结果:
"".join(result[::-1])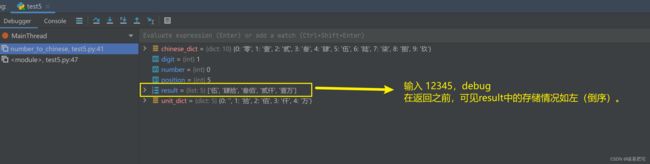
源代码:
def number_to_chinese(number):
# 数字0要特殊处理:number只有0的情况
if number == 0:
return "零"
chinese_dict = {
0: "零",
1: "壹",
2: "贰",
3: "叁",
4: "肆",
5: "伍",
6: "陆",
7: "柒",
8: "捌",
9: "玖"
}
unit_dict = {
0: "",
1: "拾",
2: "佰",
3: "仟",
4: "万"
}
result = [] # 记录结果
position = 0 # 指示单位
while number > 0:
# 从低位到高位取出number中各数位上的数
digit = number % 10
if digit != 0:
result.append(chinese_dict[digit] + unit_dict[position]) # 结果=汉字+单位
else:
# 零
if result and result[-1] != "零":
result.append("零")
number //= 10
position += 1
return "".join(result[::-1])
if __name__ == "__main__":
number = int(input("请输入金额(1-5位整):"))
if 1 <= number <= 99999:
chinese_amount = number_to_chinese(number)
print(f"大写汉字金额:{chinese_amount}")
else:
print("非法!")
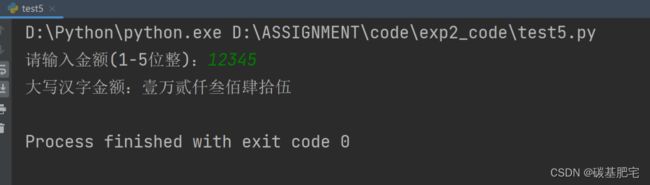
列出测试数据和实验结果截图:
6、天天向上的力量
一年365天,每天进步1‰,累计进步多少?如果每天退步1‰,累计剩下多少?如果以3天打鱼2天晒网的学习态度持续学习一年,学习效果如何?
这题比较简单就不多说了。注意python中的幂运算符:**
a**b表示a的b次方。a和b 都可以取浮点数。
源代码:
def calculate():
increase_rate = 0.001
total_increase = (1 + increase_rate) ** 365
total_decrease = (1 - increase_rate) ** 365
return total_increase, total_decrease
def main():
total_increase, total_decrease = calculate()
print(f"每天进步1‰,一年的累计:{total_increase:.2%}")
print(f"每天退步1‰,一年的累计:{total_decrease:.2%}")
if __name__ == "__main__":
main()
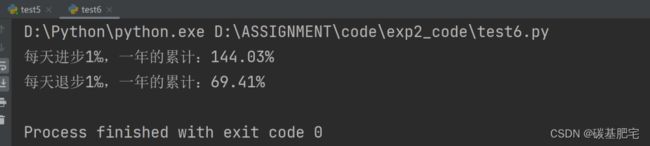
列出测试数据和实验结果截图:
7、一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?
⭐判断一个数是否是完全平方数
math.sqrt(num).is_integer()is_integer() 是Python中内建在浮点数(float)对象上的方法,这个方法的作用是检查浮点数是否表示一个整数。
x = 5.0
result = x.is_integer()
print(result) # 输出 True,因为 5.0 表示整数 5
y = 5.5
result = y.is_integer()
print(result) # 输出 False,因为 5.5 不是整数
源代码:
import math
def func():
for x in range(1, 10000):
y = x + 100
z = y + 168
if math.sqrt(y).is_integer() and math.sqrt(z).is_integer():
return x
return None
def main():
result = func()
if result is not None:
print(f"整数是:{result}")
else:
print("未找到")
if __name__ == "__main__":
main()
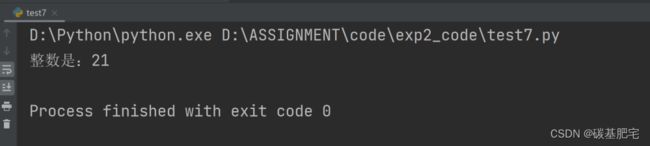
列出测试数据和实验结果截图:
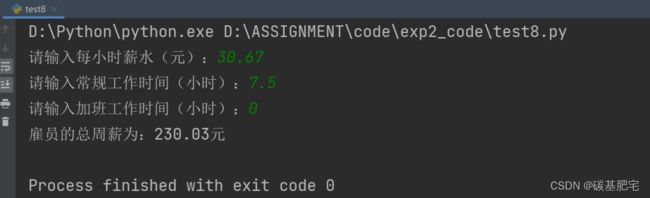
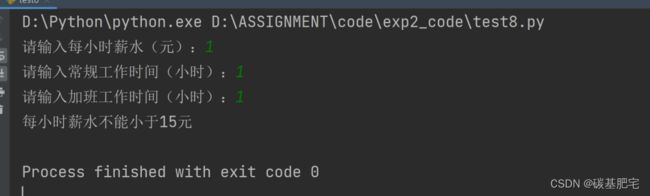
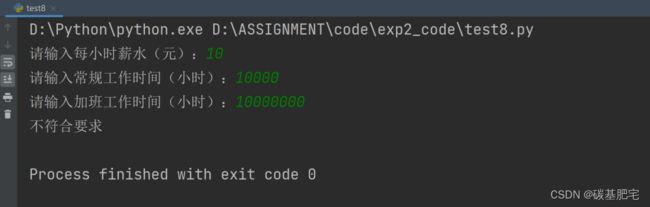
8、一个雇员一周的总薪水
一个雇员一周的总薪水,等于其每小时的时薪,乘以其一周工作的正常小时数,再加上加班费。加班费等于总的加班时间,乘以每小时薪水的1.5倍。
编写一个程序,以每小时的薪水,常规工作时间,加班工作时间作为输入,显示一个雇员的总周薪。按照要求:每周常规工作时间不能超过40小时且不能小于等于0,正常工作时薪不能小于15元。
源代码:
def func(hourly_wage, regular_hours, overtime_hours):
if regular_hours > 40 or regular_hours <= 0:
return "不符合要求"
if hourly_wage < 15:
return "每小时薪水不能小于15元"
regular_salary = hourly_wage * regular_hours
overtime_salary = hourly_wage * 1.5 * overtime_hours
total_salary = regular_salary + overtime_salary
return total_salary
def main():
hourly_wage = float(input("请输入每小时薪水(元):"))
regular_hours = float(input("请输入常规工作时间(小时):"))
overtime_hours = float(input("请输入加班工作时间(小时):"))
result = func(hourly_wage, regular_hours, overtime_hours)
if isinstance(result, str):
print(result)
else:
print(f"雇员的总周薪为:{result:.2f}元")
if __name__ == "__main__":
main()
⭐格式化字符串以保留两位小数
{result:.2f} 是一个格式化字符串(f-string)中的表达式,用于控制浮点数的输出格式。在这个表达式中,result 是要格式化的浮点数变量,.2f 指定了浮点数的格式化方式。
:.2f 的含义如下:
- : 表示格式说明的开始。
- .2 表示保留小数点后两位。
- f 表示要格式化成浮点数。
如果 result 是一个浮点数,{result:.2f} 会将其格式化为小数点后保留两位的浮点数,并以字符串的形式返回。例如 result 的值是 123.45678,那么{result:.2f} 将返回字符串 "123.46"。
当然还有别的方式进行浮点数的格式化:
pi = 3.1415926
print('%.2f' %pi)
规则和C语言类似。感兴趣的同学可以去搜一搜,这里不再赘述。
列出测试数据和实验结果截图:
9、水仙花数是3位整数(100-199),它的各位数字立方和等于该数本身。请编写程序。
源代码:
def get_number():
lily_numbers = []
for number in range(100, 1000):
digit1 = number // 100
digit2 = (number // 10) % 10
digit3 = number % 10
# 立方和
sum_of_cubes = digit1 ** 3 + digit2 ** 3 + digit3 ** 3
# 判断
if sum_of_cubes == number:
lily_numbers.append(number)
return lily_numbers
def main():
lily_numbers = get_number()
if lily_numbers:
print("3位水仙花数有:", lily_numbers)
else:
print("未找到3位水仙花数。")
if __name__ == "__main__":
main()
列出测试数据和实验结果截图:

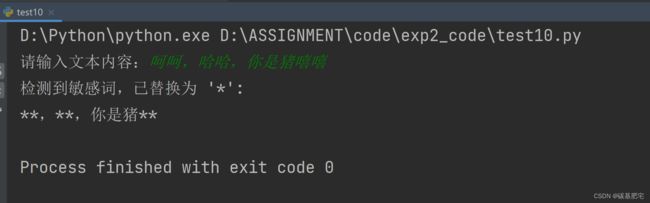
10、过滤敏感词
敏感词一般是指带有敏感政治倾向、暴力倾向、不健康色彩的词或不文明用语,论坛、网站管理员一般会设定一些敏感词,以防不当发言影响论坛、网站环境。若论坛、网站设置了敏感词,用户编辑的内容又含有敏感词,论坛和网站会将其判定为不文明用语,阻止内容的发送,或使用“*”替换其中的敏感词。(censor:审查/删减的意思)
⭐正则表达式
正则表达式是一个特殊的字符序列,它能方便地检查一个字符串是否与某种模式匹配。
正则表达式模块:re
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。

def censor_text(text, sensitive_words):
censored_text = text
for word in sensitive_words:
pattern = re.compile(re.escape(word), re.IGNORECASE)
censored_text = pattern.sub('*' * len(word), censored_text)
return censored_text- re.escape() :一个预防措施,word可能包含正则表达式中的特殊字符,这样写用于对word中的文本进行转义以确保文本中的特殊字符不被解释为正则表达式的元字符
- pattern.sub():正则表达式对象的
sub方法用于替换匹配到的文本。它接受两个参数:
- 替换文本:在这里使用
'*' * len(word)来生成与敏感词word相同长度的星号串,将敏感词完全替换为星号。 - 要替换的文本:这是原始文本
censored_text,在其中查找敏感词word,如果匹配上了,再进行替换。
源代码:
import re
def censor_text(text, sensitive_words):
censored_text = text
for word in sensitive_words:
# 创建正则表达式用的
pattern = re.compile(re.escape(word), re.IGNORECASE)
censored_text = pattern.sub('*' * len(word), censored_text)
return censored_text
def main():
sensitive_words = ["呵呵", "哈哈", "嘻嘻"] # 定义敏感词列表
user_text = input("请输入文本内容:")
censored_text = censor_text(user_text, sensitive_words)
if censored_text != user_text:
print("检测到敏感词,已替换为 '*':")
print(censored_text)
else:
print("文本内容合法,无敏感词。")
if __name__ == "__main__":
main()
列出测试数据和实验结果截图: