python-爬虫项目<实现爬取豆瓣TOP250并保存于Excel和数据库>
python-爬虫项目<实现爬取豆瓣TOP250并保存于Excel和数据库>
- 前言
- 一、程序运行结果
- 二、程序源码
- 三、源码注释
-
- 1、所使用依赖包
- 2、函数功能
- 四、爬取思路
- 五、爬虫常用的第三方库
-
- 1、模拟浏览器访问
-
- (1)urllib.request
- (2)requests
- (3)fake-useragent
- 2、解析HTML文件
-
- (1)BeautifulSoup
- 3、提取我们所需的信息
-
- (1)re
- 4、保存数据
-
- (1)存入txt文档(codecs)
- (2)存入Excel表(xlwt)
- (3)存入数据库-sqlite(sqlite3)
- 5、其他库
-
- (1)打印进度条(tqdm)
前言
本文为原创,代码并非原创,如有侵权,请联系我删除。转自bilibili视频:Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析
本文仅为学习过程的记录,非常好的课程教学。那么从此项目中我们可以学到哪些东西呢?我总结主要有以下几点:
1、可以学习一个完整爬虫项目的编码思路;
2、可以学习在爬虫项目中几个常用的第三方库;
3、可以学习正则匹配的在爬虫中的简单应用;
4、可以学习保存数据方式:Excel表格、sqlite数据库;
5、可以学习python操作sqlite的方式。
在将源码进行注解分享之后,我会按照以上的5个方面对自己学习的成果进行一个总结交流。
一、程序运行结果
首先我们从结果开始学习,程序运行结果如下:

那我们来检查一下是否已存入数据库和Excel表格:
首先我们可以看到在sqlite数据库是已经保存了的:

其次表格也是保存完好的:

到这里我们知道,这个源码是可运行的!话不多说,我们上源码!
二、程序源码
以下为实现爬取豆瓣TOP250并保存于Excel表格和sqlite数据库源码:
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
# 全局正则规则!
# .匹配所有;*前面出现无数次;?前面出现0/1次
#影片链接
findLink = re.compile(r'') # 创建正则表达式对象,表示规则
#影片图片
findImgSrc = re.compile(r',re.S) # 让换行符包含在字符中
# 影片片名
findTitle = re.compile(r'(.*)')
#影片评分
findRating = re.compile(r'')
#影片评价人数
findJudag = re.compile(r'(\d*)人评价')
#影片概况
findInq = re.compile(r'(.*)')
#影片详细内容
findBd = re.compile(r'(.*?)
',re.S)
# 主函数
def main():
print("[*]已开始爬取网页数据...")
baseurl = "https://movie.douban.com/top250?start="
# 爬取网页
datalist = getData(baseurl)
print("[*]网页数据爬取已完成...")
## 定义路径
savepath = "豆瓣电影TOP250.xls"
dbpath ="movie.db"
# 保存数据
print("[*]正在将数据保存至数据库...")
savaDataDB(datalist,dbpath)
print("[*]正在将数据保存至Excel表格...")
saveData(datalist,savepath)
# 爬取网页
def getData(baseurl):
datalist = []
# 共10页
for i in range(0,10): # 共10页,每页25个
url = baseurl + str(i*25)
html = askURL(url) # 保存获取到的网页源码
# 逐页解析数据
soup =BeautifulSoup(html,"html.parser") # 用html.parser解析文件,形成文件树
for item in soup.find_all('div',class_="item"): # 查找所有符合要求的字符串,形成列表
data = [] # 保存一部电影的所有信息
item = str(item)
# 影片链接
link = re.findall(findLink,item)[0] # re库通过正则表达式查找指定的字符串
data.append(link)
# 影片图片
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc)
# 影片片名
titles = re.findall(findTitle,item) # 名字有俩,中外
if len(titles) == 2:
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/","")
data.append(otitle)
else: # 外名没有,留空
data.append(titles[0])
data.append(' ')
# 影片评分
rating = re.findall(findRating,item)[0]
data.append(rating)
# 影片评价人数
judgeNum = re.findall(findJudag,item)[0]
data.append(judgeNum)
# 影片概况
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append(' ')
# 影片详细内容
bd = re.findall(findBd,item)[0]
## 替换其他内容
bd = re.sub(' 在源码中我已经给出了详细的代码注释,接下来我们交流一手爬取的实现思路。
三、源码注释
1、所使用依赖包
# 用来解析返回的HTML文件,形成文件树,方便我们提取信息
from bs4 import BeautifulSoup
# 正则匹配
import re
# 模拟浏览请求
import urllib.request,urllib.error
# 用来操作Excel表格
import xlwt
# 引入sqlite数据库
import sqlite3
2、函数功能
# 主函数,很容易看出编码思路
def main():
# 功能函数,模拟浏览器访问目标URL,得到网页内容
def askURL(url):
# 功能函数,爬取网页,并提取网页我们所需的数据
def getData(baseurl):
# 功能函数,将数据存入Excel表格
def saveData(datalist,savepath):
# 功能函数,将数据存入数据库
def savaDataDB(datalist,dbpath):
# 功能函数,初始化数据库
def init_db(dbpath):
# 功能函数,主函数,函数入口
if __name__ == "__main__":
四、爬取思路
其实爬虫这东西,我的理解就是用程序代替浏览器访问,然后将本该返回渲染在浏览器的网页文件通过编码解析(反渲染),利用规则匹配提取出我们需要的信息,然后保存下来。最终达到方便我们使用信息的目的。
接下来我们就按照我的理解,来阐述一下本项目编码的实现思路:首先是模拟浏览器访问,那就是得先有一个目标URL然后访问对应第三方库:urllib.request,然后是将本该返回渲染在浏览器的网页文件通过编码解析(反渲染,这个词是我杜撰的…)对应第三方库:BeautifulSoup,利用规则匹配提取出我们需要的信息对应第三方库:re,然后保存下来对应第三方库:xlwt、sqlite3。
到这里,此项目就差不多已经结束了。完整的实现思路就不多就是这样,接下来我将对我在本项目,以及自己写爬虫过程中用到的一些第三方库函数做一些学习记录以供交流学习。
五、爬虫常用的第三方库
我将按照爬取思路,将每一步我所用到的库函数做出解释,系统的学习可参考相关库函数的官方文档或菜鸟教程。
1、模拟浏览器访问
(1)urllib.request
此函数可用作访问目标URL,方式可以是get、post;但是只能封装伪装头,不能封装代理ip,使用方法如下:
import urllib.request
# 封装请求包
request = urllib.request.Request(url,headers=head)
# 发起请求,也可直接给URL访问
response = urllib.request.urlopen(request)
# 解析返回的包
html = response.read().decode("utf-8")
(2)requests
此函数是对urllib.request的再封装,也是用作访问目标URL,它可以封装伪装头,可封装代理ip,使用方法如下:
# 发起请求,括号为封装内容,其中headers、proxies均为字典;也可直接给URL访问
import requests
response = requests.get(url=url,headers=header,proxies=ip)
# 解析返回的包
html = response.text
(3)fake-useragent
之前说了那么多封装头,封装ip,这是一个第三方库提供的伪造头的包,但我在使用的过程中会报错。当然这个函数我们也可以自己写,编码可参考博客:python-爬虫项目<实现增加博客访问量>,使用方法:
from fake_useragent import UserAgent
# 随机一个headers头
header = {"User-Agent":UserAgent().random}
2、解析HTML文件
(1)BeautifulSoup
此函数可用作解析HTML文件,但不只是解析,它还提供了许多检索文档的方式,使用如下:
from bs4 import BeautifulSoup
# 使用html.parser解析器解析文件
bs = BeautifulSoup(html,"html.parser")
## tag 标签机器内容:拿到他所找到的第一个
bs.title
bs.title.string
## NavigableString 标签里面的内容(字符串)
bs.a.attrs # 返回字典
## BeautifulSoup 表示整个文档
bs.
## Comment 是一个特殊的NavigableString,不带会携带注释
# 文档的遍历(可查看官方文档学习)
## 遍历头
bs.head.contents
# 文档搜索
1、find_all()
## 字符串过滤:会查找与字符串完全匹配的内容
bs.find_all('a') # 返回列表
### 正则表达式搜索:使用search()方法来匹配内容
bs.find_all(re.compile("a"))
### 方法 :传入一个函数(方法),根据函数要求来搜索
2、kwargs 参数
bs.find_all(id=2)
3、text 参数
bs.find_all(text=[1,2,3])
4、limit 参数
bs.find_all('a',limit=4)
5、css选择器
bs.selsct('title') # 通过标签查找
bs.selsct('.mnav') # 通过类名
bs.selsct('#u1') # id
bs.selsct("a[class]") # 通过属性、类名
bs.selsct('head > title') # 通过子标签
bs.selsct('.mnav ~ .bri') # 通过兄弟节点
3、提取我们所需的信息
(1)re
正则匹配,基本匹配规则和用法如下:(常用的正则表达式不会写可以去网上直接搜)常见正则表达式
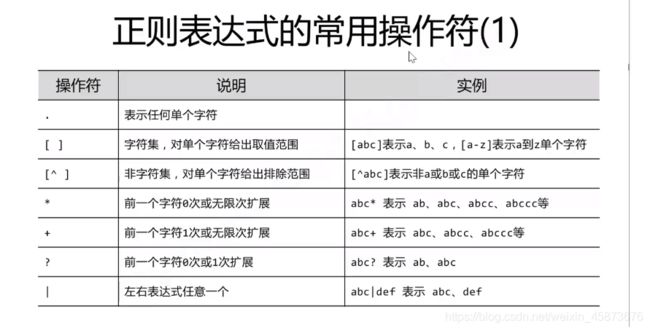

python中的使用:
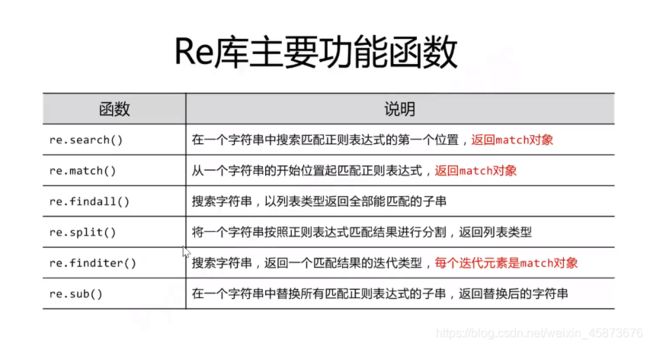
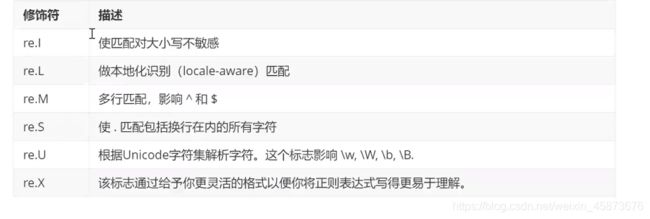
编码使用如下:
# .匹配所有*前面出现?前面出现0/1次
#定义匹配规则
findLink = re.compile(r'') # 创建正则表达式对象,表示规则
findImgSrc = re.compile(r',re.S) # 让换行符包含在字符中
findTitle = re.compile(r'(.*)')
findRating = re.compile(r'')
findJudag = re.compile(r'(\d*)人评价')
findInq = re.compile(r'(.*)')
findBd = re.compile(r'(.*?)
',re.S)
#锁定范围
item = soup.find_all('div',class_="item")
#应用匹配规则
## 一般使用
link = re.findall(findLink,item)[0] # re库通过正则表达式查找指定的字符串
## 匹配多个
titles = re.findall(findTitle,item) # 名字有俩,中外
if len(titles) == 2:
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/","") # 替换
data.append(otitle)
else: # 外名没有,留空
data.append(titles[0])
data.append(' ')
## sub使用
bd = re.findall(findBd,item)[0]
## 替换其他内容
bd = re.sub(' 4、保存数据
(1)存入txt文档(codecs)
操作txt文档时,可直接用内置的open函数,但是由于编码问题,中文会乱码,使用codecs库指定编码方式即可解决问题,如下:
import codecs
result = [1,2,3,4,5,6]
f = codecs.open('url.txt','w+',encoding='utf-8')
for link in tqdm(result,desc="本页面爬取中",ncols=70):
f.write(link)
f.write("\n")
f.close()
(2)存入Excel表(xlwt)
示例如下:
import xlwt
def saveData(datalist,savepath):
# 创建表格
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
# 创建工作表
sheet = book.add_sheet('豆瓣电影',cell_overwrite_ok=True)
# 表头
col = ("电影链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
# 写入表头
for i in range(0,8):
sheet.write(0,i,col[i])
#写入数据
for i in range(0,250):
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
# 保存表格
book.save(savepath)
print("[*]Excel表格已保存...")
(3)存入数据库-sqlite(sqlite3)
示例如下,使用此方法必须熟悉数据库语法,动态的构造sql语句:
def savaDataDB(datalist,dbpath):
# 初始化数据库,建表
init_db(dbpath)
# 连接数据库
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
# 动态构造sql语句,数据存入数据库
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"'+data[index]+'"'
sql = '''
insert into movie250(
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' %",".join(data)
cur.execute(sql)
conn.commit()
# 断开连接
cur.close()
conn.close()
print("[*]数据库已保存...")
# 初始化数据库,建表
def init_db(dbpath):
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric,
rated numeric ,
instroduction text,
info text
);
''' #创建数据表
# 执行SQL语句
cursor.execute(sql)
# 提交运行
conn.commit()
# 断开连接
conn.close()
5、其他库
(1)打印进度条(tqdm)
此库可以嵌套在for循环、list中使用,会生成进度条!示例如下:
from tqdm import tqdm
result = [1,2,3,4,5,6,7,7,8,9,0]
def saveResult(result):
f = codecs.open('url.txt','w+',encoding='utf-8')
for link in tqdm(result,desc="本页面爬取中",ncols=70): #desc:进度条标题;ncols:进度条长度。
f.write(link)
f.write("\n")
f.close()
到这里本文正式结束啦!!代码可CV大法直接运行。
欢迎关注,点赞。与我交流一同学习python、Django、爬虫、docker、路由交换、web安全等一切东西。