数字图像处理——第八章 图像压缩
文章目录
- 8.1 为何要压缩
-
- 8.1.1 图像信息的度量
- 8.1.2 编码冗余
- 8.1.3 空间和时间(像素)冗余
- 8.1.4 压缩评价方法
- 8.2 基本的压缩方法
-
- 8.2.1 霍夫曼编码
- 8.2.2 行程编码
- 8.2.3 JPEG编码
- 8.3 数字图像水印
- 8.4 总结
8.1 为何要压缩
图象和视频通常在计算机中表示后会占用非常大的空间,而出于节省硬盘空间的考虑,往往要进行压缩。同时,传输过程中,为了节省珍贵的带宽资源和节省时间,也迫切要求压缩。压缩之后,传输过程中的误码率也会相应地减少。
且人眼对颜色只有一定的感应能力,当某些颜色十分相近时,人是感觉不出差异的(或者很小)。这一点为压缩提供了机会。我们把相近的颜色用一种颜色表示,从而减少了图象的存储空间,实现压缩。同时,通过解压缩,我们可以根据之前采取的压缩方法(有损压缩、无损压缩等)进行相应的解压缩措施,保证图象的真度恢复。
在信息传递的过程中,数据是信息传递的手段,信息中包含不相关或重复信息的表示认为包含冗余数据,用 b b b和 b ′ b^{'} b′来表示相同信息的两种表示中的比特数,也就是说二者存在冗余数据,引入压缩率 C = b b ′ C=\frac{b}{b^{'}} C=b′b相对数据冗余R是 R = 1 − 1 C R=1-\frac{1}{C} R=1−C1
8.1.1 图像信息的度量
在信息理论中,一个随机变量的熵表示的是“信息”、“意外”或者“不确定性”的平均水平。如果一件事的可能性越小,那么如果这件事发生了就会给人带来极大的震撼,信息量也就越大。用公式来表达: I ( x ) = − l o g P ( x ) ( 一 件 事 的 信 息 ) I(x)=-logP(x)(一件事的信息) I(x)=−logP(x)(一件事的信息)
平均信息量(信息熵): H ( X ) = − ∑ i = 1 m p ( x i ) l o g P ( x i ) H(X)=-\sum_{i=1}^m p(x_i)logP(x_i) H(X)=−i=1∑mp(xi)logP(xi)
8.1.2 编码冗余
编码冗余是指在图像编码过程中,由于直方图分布的不平均,使灰度出现的概率并不相同,若不考虑灰度发生的概率来分配码字的长度,就会使得某些概率较大的灰度值获得的码长较长,从而造成了编码冗余,自然的二进制编码同样达不到最佳码长的效果。
8.1.3 空间和时间(像素)冗余
像素间冗余是一种与像素间相关性有直接联系的数据冗余。
同一景物表面上采样点的颜色之间通常存在着空间关联性,相邻各点的取值往往近似或者相同,这就是空间冗余。例如图片中有一篇连续的区域,这个区域的像素都是相同的颜色,那么空间冗余就产生了。
对于一张静态图片,存在空间冗余(几何冗余),这是由于在一张图片中单个像素对图像的视觉贡献常常是冗余的,可借助其相邻像素的灰度值进行推断。
对于连续图片或视频,还会存在时间冗余(帧间冗余),大部分相邻图片间的对应点像素都是缓慢过度的。
8.1.4 压缩评价方法
性能评价
还原图像质量是评价图像压缩编码方法的最为重要的标准之一,它包括两方面的含义:一方面是图像的逼真度,即还原图像与 原始图像的偏离程度;另一方面是图像的可懂度,即图像能向人或机器提供特征信息的能力。 对于限失真编码,原图像与还原图像之间存在着差异,差异的大小意味着恢复图像的质量不相同。 但是,由于人的视觉冗余度 的原因,则对有些差异的灵敏度较低,这就产生了两种判别标准:一种是客观判别标准,它建立在原始图像与还原图像之间的误差 上;另一种是主观评价标准,通过用人的肉眼对图像打分而得到。
客观评价
对图像质量进行定量描述是一个比较复杂的问题,进展比较缓慢,一方面是因为人们还没有充分了解视觉感知的过程和方法;另一方面是由于图像是多维信号,很难用确定的几个统计参数来表示其特征。 彩色图像由于量纲数增多,而且必须满足人眼对彩色 的视觉感知,因此对彩色图像逼真度进行定量表示是一个更加复杂的问题。 目前应用得较多的是对灰度级图像逼真度的定量表示。 一个合理的尺度应该与图像的主观测试结果相吻合或密切相关,要求便于计算分析而且简单易行。
保真度判定准则:
e m s = [ 1 M N ∑ x = 0 M − 1 ∑ y = 0 N − 1 [ g ( x , y ) − f ( x , y ) ] 2 ] 0.5 e_{ms}=[\frac{1}{MN}\sum_{x=0}^{M-1}\sum_{y=0}^{N-1}[g(x,y)-f(x,y)]^{2}]^{0.5} ems=[MN1x=0∑M−1y=0∑N−1[g(x,y)−f(x,y)]2]0.5为M*N阵列上平均误差平方的均方跟,g(x,y)是f(x,y)的近似,均方根越小,图像压缩效果就越好。
8.2 基本的压缩方法

压缩分类
根据压缩后的图像能否完全恢复将图像压缩方分为两种:一种是无损压缩;另一种是有损压缩。
无损压缩
利用无损压缩方法消除或减少的各种形式的冗余可以重新插入到数据中,因此,无损压缩是可逆过程,也称无失真压缩。 为了消除或减少数据中的冗余度,常常要用信源的统计特性或建立信源的统计模型,因此许多实用的无损压缩技术均可归结为统计编 码方法。 统计编码方法中常用的有 Huffman 编码、算术编码、RLE(Run Length Encoding)编码等。 此外统计编码技术在各种有损压缩 方法中也有广泛的应用。
有损压缩
有损压缩法压缩了熵,信息量会减少,而损失的信息量不能再恢复,因此有损压缩是不可逆过程。 有损压缩主要有两大类:特征 提取和量化方法。 特征提取的编码方法如模型基编码、分形编码等。 量化是有损压缩最基本的形式,其优点是可以得到比无损压缩 高得多的压缩比。 有损压缩只能用于允许一定程度失真的情况,比如对图像、声音、视频等数据的压缩。
无损压缩和有损压缩结合形成了混合编码技术,它融合了各种不同的压缩编码技术,很多国际标准都是采用混合编码技术,如 JPEG,MPEG 等标准。 利用混合编码对自然景物的灰度图像进行压缩一般可压缩几倍到十几倍,而对于自然景物的彩色图像压缩比 将达到几十甚至上百倍。
我们选取霍夫曼(针对编码冗余)、行程(针对空间冗余)、JPEG编码(主流)来重点学习下。
8.2.1 霍夫曼编码
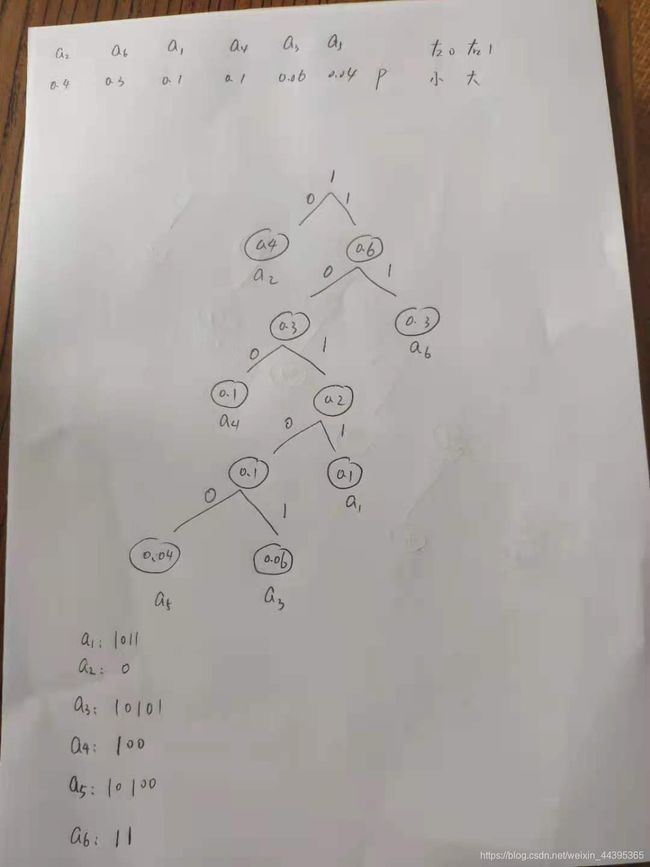
在无损压缩的编码方法中,霍夫曼编码是一种有效的编码方法。 它是霍夫曼博士在 1952 年根据可变长最佳编码定理提出的。 依据信源数据中各信号出现的频率分配不同长度的编码。 其基本思想是在编码过程中,对出现频率越高的值,分配越短的编码长度,相应地对出现频率越低的值则分配较长的编码长度,它是一种无损编码方法。 采用霍夫曼编码方法的实质是针对 统计结果对字符本身重新编码,而不是对重复字符或重复子串编码,得到的单位像素的比特数最接近图像的实际熵值。
编码过程:
import copy
class Node:
def __init__(self, name, weight):
self.name = name #节点名
self.weight = weight #节点权重
self.left = None #节点左孩子
self.right = None #节点右孩子
self.father = None # 节点父节点
#判断是否是左孩子
def is_left_child(self):
return self.father.left == self
#创建最初的叶子节点
def create_prim_nodes(data_set, labels):
if(len(data_set) != len(labels)):
raise Exception('数据和标签不匹配!')
nodes = []
for i in range(len(labels)):
nodes.append( Node(labels[i],data_set[i]) )
return nodes
# 创建huffman树
def create_HF_tree(nodes):
#此处注意,copy()属于浅拷贝,只拷贝最外层元素,内层嵌套元素则通过引用,而不是独立分配内存
tree_nodes = nodes.copy()
while len(tree_nodes) > 1: #只剩根节点时,退出循环
tree_nodes.sort(key=lambda node: node.weight)#升序排列
new_left = tree_nodes.pop(0)
new_right = tree_nodes.pop(0)
new_node = Node(None, (new_left.weight + new_right.weight))
new_node.left = new_left
new_node.right = new_right
new_left.father = new_right.father = new_node
tree_nodes.append(new_node)
tree_nodes[0].father = None #根节点父亲为None
return tree_nodes[0] #返回根节点
#获取huffman编码
def get_huffman_code(nodes):
codes = {}
for node in nodes:
code=''
name = node.name
while node.father != None:
if node.is_left_child():
code = '0' + code
else:
code = '1' + code
node = node.father
codes[name] = code
return codes
if __name__ == '__main__':
labels = ['a','b','c','d','e','f']
data_set = [9,12,6,3,5,15]
nodes = create_prim_nodes(data_set,labels)#创建初始叶子节点
root = create_HF_tree(nodes)#创建huffman树
codes = get_huffman_code(nodes)#获取huffman编码
#打印huffman码
for key in codes.keys():
print(key,': ',codes[key])
输出结果
a : 00
b : 01
c : 100
d : 1010
e : 1011
f : 11
下一步是统计图像中像素值,构造霍夫曼树(包括节点,权重,值),将编码打印出来。
8.2.2 行程编码
行程编码的基本思想:将一行中颜色值相同的相邻象素用一个计数值和该颜色值来代替。例如aaabccccccddeee可以表示为3a1b6c2d3e。如果一幅图象是由很多块颜色相同的大面积区域组成,那么采用行程编码的压缩效率是惊人的。然而,该算法也导致了一个致命弱点,如果图象中每两个相邻点的颜色都不同,用这种算法不但不能压缩,反而数据量增加一倍。
行程编码的可行性讨论:行程编码的压缩方法对于自然图片来说是不太可行的,因为自然图片像素点错综复杂,同色像素连续性差,如果硬要用行程编码方法来编码就适得其反,图像体积不但没减少,反而加倍。鉴于计算机桌面图,图像的色块大,同色像素点连续较多,所以行程编码对于计算机桌面图像来说是一种较好的编码方法。行程编码算法特点:有算法简单、无损压缩、运行速度快、消耗资源少等优点。
def count_string(s):
count=[]
num=1
for i, ch in enumerate(s):
if i==0:
count.append([1,ch])
print(count)
if i>=1:
next_ele=s[i]
first_ele=s[i-1]
if next_ele!=first_ele:
num=1
if next_ele==first_ele:
num+=1
print(num)
count.pop()
count.append([num,ch])
else:
count.append([1,ch])
return count
str1=count_string('iiiiijjsssshioajjjjj')
print(str1)
结果为:[[5, ‘i’], [2, ‘j’], [4, ‘s’], [1, ‘h’], [1, ‘i’], [1, ‘o’], [1, ‘a’], [5, ‘j’]]
# 用python压缩图像
import cv2 as cv
import numpy as np
##彩色图像灰度化
#image = cv.imread('image/shayu.jpg',1)
image = cv.imread('pic/cat500x480.jpg',0)
#grayimg = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
rows, cols = image.shape
image1 = image.flatten() #把灰度化后的二维图像降维为一维列表
#print(len(image1))
#二值化操作
for i in range(len(image1)):
if image1[i] >= 127:
image1[i] = 255
if image1[i] < 127:
image1[i] = 0
data = []
image3 = []
count = 1
#行程压缩编码
for i in range(len(image1)-1):
if (count == 1):
image3.append(image1[i])
if image1[i] == image1[i+1]:
count = count + 1
if i == len(image1) - 2:
image3.append(image1[i])
data.append(count)
else:
data.append(count)
count = 1
if(image1[len(image1)-1] != image1[-1]):
image3.append(image1[len(image1)-1])
data.append(1)
#压缩率
ys_rate = len(image3)/len(image1)*100
print('压缩率为' + str(ys_rate) + '%')
#行程编码解码
rec_image = []
for i in range(len(data)):
for j in range(data[i]):
rec_image.append(image3[i])
rec_image = np.reshape(rec_image,(rows,cols))
show(rec_image)
原图与压缩过的图像,压缩后的图像去除了多余的数据,基本保留了图像的信息,但似乎会损失一些细节,比如猫的嘴唇和左手的细节,形态被勾勒得不完全。

8.2.3 JPEG编码
JPEG 是联合图形专家组 (Joint Photograpic Experts Group) 的缩写名称。JPEG 致力于研制彩 色的和单色的、多灰度连续色调的静态图像的数 字图像压缩的通用国际标准。JPEG 利用了人眼的 心理和生理特征及其局限性,因而它非常适合不 太复杂以及一般来自于真实景象的图像。JPEG 的性能依赖于图像的复杂性。对于一般图像的压缩 比为 20:1 到 25:1。如果要做到无损压缩,压缩比 将在 2:1。对于非真实图像,例如线条或卡通图像,JPEG 压缩效果并不理想。 基于DCT 的 JPEG 标准的压缩是有失真的,DCT 变换后系数的量化是引起失真的主要原因。 压缩效果与图像内容本身有较大的关系。
步骤
JPEG算法的第一步,图像被分割成大小为8X8的小块,这些小块在整个压缩过程中都是单独被处理的;
JPEG压缩算法中,需要把图案转换成为YCbCr模型,这里的Y表示亮度(Luminance),Cb和Cr分别表示绿色和红色的“色差值”。YCbCr模型广泛应用在图片和视频的压缩传输中。有损压缩首先要做的事情就是“把重要的信息和不重要的信息分开”,YCbCr恰好能做到这一点;
接着进行DCT变换:数据经过DCT变化后,被明显分成了直流分量和交流分量两部分,为后面的进一步压缩起到了充分的铺垫作用,可以说是整个JPEG中最重要的一步;
数据量化和压缩:最后一步是对数据进行哈弗曼编码(Huffman coding)。
8.3 数字图像水印
可见水印:
数字图像水印处理是把数据插入到一幅图像中的过程,目的是在图像上添加信息和数据,形成对图像的保护。水印是一幅不透明的或半透明的子图像。 f w = ( 1 − α ) f + a w f_w=(1-\alpha)f+aw fw=(1−α)f+aw
f w f_w fw代表水印图像, f f f为原图像,w为水印,若 α \alpha α为1,水印不透明,衬底图像完全为暗色调, α \alpha α接近0,水印会越来越少。
不可见水印:
即为最低有效位信息隐藏,指的是将一个需要隐藏的二值图像信息嵌入载体图像的最低有效位,即将载体图像的最低有效位层替换为当前需要隐藏的二值图像,从而实现将二值图像隐藏的目的。由于二值图像处于载体图像的最低有效位上,所以对于载体图像的影响并不明显,其具有较高的隐蔽性。
在必要时直接将载体图像的最低有效位层提取出来,即可得到嵌入在该位上的二值图像,达到提取秘密信息的目的。
8.4 总结
本章我们学习了数字图像压缩的基础,图像压缩在当今应用得很广泛,要注意压缩是否有损。在学习过程中,要注意对理论的掌握,编程方面,由于涉及的基本是open cv以外的语法知识,对算法的设计要求较高,我掌握比较困难,所以这章了解好基本知识是主要目的。