Python爬虫笔记2——Requests:让HTTP服务人类
虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人感觉不好,而Requests自称“HTTP for Humans”,说明使用更简洁方便。
Requests继承了urli2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定相应内容的编码,支持国际化的URL和POST数据自动编码。
Requsets的底层实现就是urllib3
Requests的文档非常完备,中文文档也相当不错.Requests能完全满足当前网络的需求,支持Python 2.6-3.5,而且能在PyPy下完美运行。
安装方式:
利用 pip 安装或者利用 easy_install 都可以完成安装:
(1) pip install requests
(2) easy_install requests
基本GET请求(headers参数和parmas参数):
1.最基本的GET请求可以直接用get方法:
response = requests.get("http://www.baidu.com/");
#也可以这么写
#response = requests.request("get", "http://www.baidu.com/")2.添加 headers 和 查询参数:
如果想添加 headers,可以传入 headers 参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
(1)添加headers参数:
Tip1:由于当我们用网络访问某些网站时,某些网站会对请求进行识别,判断这个请求究竟是由用户发起的,还是由代码发起的,所有就有了下面的Tip2。
Tip2:在使用 requests 的 get 方法前,我们一般需要模拟编造一个 headers ,headers一般时利用字典的数据类型进行构造,而键值对的值,则是我们开发者工具中的 User-Agent 的内容信息,以 User-Agent 为键,其值为值。如下所示:
下图为开发者工具中截取的豆瓣网的 User-Agent 信息:

下图为在根据上图编写的headers信息:
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78'}但是在编写完 headers 之后我们不能直接运行代码,我们需要把 headers 加入到我们的 get 方法中去,如下:
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78'}
r = requests.get('https://www.douban.com', headers)但是这样运行之后返回的状态码数据还是418(关于状态码的信息去看Python爬虫笔记第一记),所以有下面的知识点。
当我们在函数里面传递参数时,分为位置参数和关键字参数,在使用 get 方法时我们不知道第二个参数甚至于后面的参数是什么,所以我们在这里需要使用关键字传参。
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78'}
r = requests.get('https://www.douban.com', headers=headers)之后利用 print 对r进行输出就可以看见返回的状态码是200。
(2)添加查询参数 params:
举例:当我们在网址栏输入 https://www.baidu.com/s?wd=python
网页会直接跳转到使用百度搜索引擎查询 python 的页面:其中 wd 就是查询参数之一。
如下图(输入网址):

跳转后:
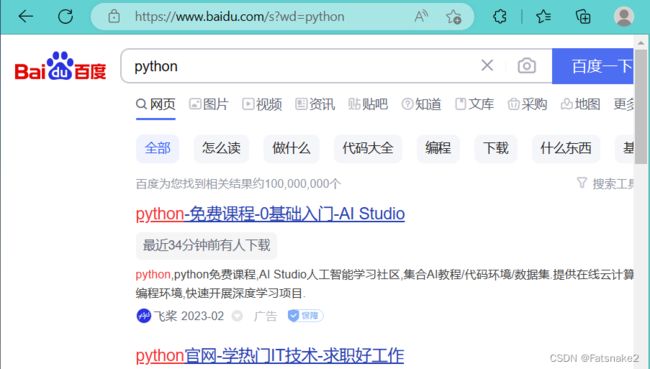
Tip1:在使用get方法时,除了默认的 url 参数外,其余的参数我们都需要使用关键字传值,且都是使用字典数据类型进行编写。
Tip2:我们在进行函数传参时,我们最好都养成使用关键字传参的习惯。
在传递 params 参数前我们需要先编写 params 参数,编写完之后再进行传参:
kw = {'wd':'python'}
r = requests.get('https://www.baidu.com', params=kw)由于响应对象具有多个数据类型的值:所以我们可以使用如下方式进行输出:
#查看响应内容,r.text 返回的是Unicode格式的数据
print(r.text)
#查看相应内容,r.content 返回的是字节流数据
print(r.content)
#查看完整url地址
print(r.url)
#查看响应头部字符编码
print(r.encoding)
#查看响应码
print(r.status_code)
Tip3:但是由于网页本身的编码和requests进行解码时,编码格式不匹配,会经常导致我们爬虫时,所获取的信息出现乱码。
对于爬取内容出现乱码的解决方法:
(1)查看requests解码格式:
print(r.encoding)(2)查看爬取网页编码格式:
我们可以在爬取网页单机鼠标右键,选择查看网页源代码,之后我们可以在源代码里面找到charset属性,charset属性后面就是这个网页所用的编码格式。
如下图:
![]()
(3)手动设置编码格式:
r.encoding = 'utf-8'(4)手动设置完编码格式之后我们就可以输出我们爬取的编码内容了。
Tip4:我们在使用 get 方法时,一定要确保我们的url地址是正确的,不能少任何字符。
举例:
百度搜索python的url地址是:http://www.baidu.com/s?wd=python
代码是(注意这里的url地址和之前的url地址的不同):
import requests
kw = {'wd' : 'python'}
r = requests.get('http://www.baidu.com/s?', params=kw)
r.encoding = 'utf-8'
print(t.text)Tip5:假如我们在浏览器中可以正常看见信息,但是在python中我们看不见的话,只有一种可能,那就是我们的 headers 信息是错误的。
所以我们上述的代码还需要加上 headers 信息:
#导入requests包
import requests
#根据开发者工具所获取的内容设置headers参数
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78'}
#设置params参数
kw = {'wd' : 'python'}
#调用get方法
r = requests.get('http://www.baidu.com/s?', headers=headers, params=kw)
#手动设置编码格式
r.encoding = 'utf-8'
#输出相应内容中text格式的内容
print(t.text)