讯飞星火:整体超越ChatGPT,医疗超越GPT4!一手实测在此
杨净 发自 凹非寺
量子位 | 公众号 QbitAI
整体超越ChatGPT,医疗全面超越GPT-4!
五个月之后,在科大讯飞全球1024开发者节现场,刘庆峰如约而至兑现诺言,并给出新的Flag:
2024年上半年对标GPT-4!

不光讯飞最强星火大模型来袭,七大维度全面升级,尤其是多模态、代码生成以及复杂推理的能力,还能生成符合自己人设的AI助手。
除此之外,还有科技文献大模型、医疗大模型以及同其他企业合作的12个行业大模型一并发布。
以科技文献大模型为例,它可以一分钟就能整合18篇论文,生成一篇5页的综述报告。
还能直接生成论文中提到的代码。
医疗大模型也正式公开,化身每个人的健康助手,进行自查、用药指导以及检查/体检报告解读,并首发“讯飞晓医”APP及小程序。
在底层基础设施上,讯飞华为再次联手,发布基于昇腾生态的“飞星一号”平台发布。
正如刘庆峰所强调的那样:唯有自主可控,才有生生不息的未来。

全面对标ChatGPT、医疗超越GPT-4
既然如此,当初的Flag都实现了吗?
首先就星火大模型V3.0本身,我们自然进行了第一手的实测。
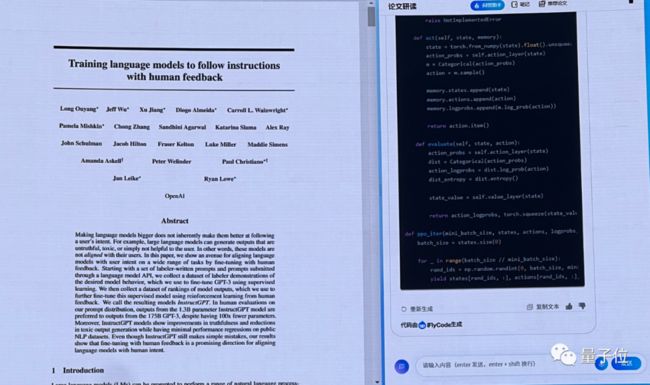
据介绍,此次七大能力持续提升,并且全面对标ChatGPT。尤其像中文能力客观评测上超越ChatGPT,在医疗、法律、教育等专业表现也格外突出,还有在代码项目级理解能力、小样本学习、多模态指令跟随与细节表达等能力有所提升。
并且此次还新增了虚拟人格功能,它可以根据性格模拟、情绪理解、表达风格来形成一个初始人设,再结合特定知识学习、对话记忆学习,形成一个更个性化的AI人设。
既然如此,那么第一波就来考验一下它的基本功。
理解能力。
比如一些只在中文语境下才能get到的网络梗,没想到星火与时俱进直接get。

就连昨天的消息也都知道。

接下来第二波进阶,也是最能考验大模型真正实力的代码生成能力。据介绍,目前讯飞星火代码能力已经超过ChatGPT,但略逊于GPT-4。

既然如此,就来实际评测一下(提示词故意有点语病):
你现在顶级程序员,请写出Resnet神经网络代码,并给出每一段代码的解释。
首先两者都正确识别了问题,给出的代码表现基本一致。
讯飞星火的回答直接分成了代码部分和解读部分。

而GPT-4的回答,直接将代码部分拆分并解释,这样方便代码修正和学习。
最后,再来看看新晋的看家本领——多模态生成能力。
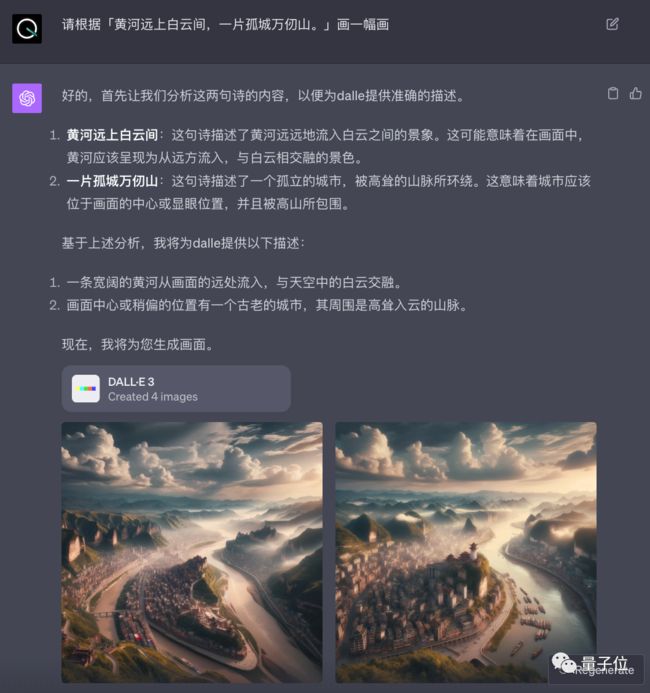
请根据「黄河远上白云间,一片孤城万仞山。」画一幅画。
这一来考验对中文诗词的理解能力,二来考究的是大模型对空间感知的能力。

△讯飞星火回答截图
△GPT-4(部分回答截图)
可以看到,讯飞星火绘制的画不仅理解来中文古诗词的内容,画风也是更具有古色古韵,而且巧妙地将黄河、白云和孤城在整个空间里组合在一起。
而GPT-4则将孤城直接理解成了城市,画面也是更为现代感……
大模型AI人设这块,这也是此次发布的重点更新。可以看到在「发现友伴」这一功能上有近20种AI人格可供选择,包括像马斯克、林黛玉、哪吒、于大爷、樱花木道、秦始皇等等。
比如像这位硅谷钢铁侠,一上来脑子里全都是地球保护、殖民火星那些事儿。

还有像林妹妹,说话语气里带有些许婉转诗意~

据刘庆峰介绍,这一功能上线12小时,已有3000+人设由开发者自创。
此次大模型的专业性上也有所提升,比如在医疗领域,问上这样一个常识问题。
我24小时尿量<100毫升,我怎么了

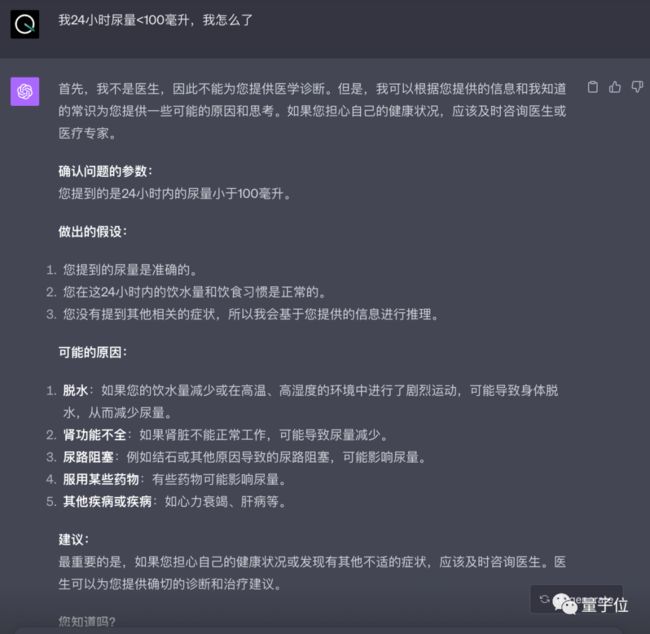
可以看到,在「可能的原因」上双方的回答基本一致。讯飞星火风格则简单直接,还给出了「严重性」提醒。而GPT-4更为完备一些。
最后再来简单总结一下测评结果:
基础能力:语义理解、时效把握以及代码生成能力上都有很大的提升;
多模态生成表现不错,尤其在空间感知能力的表现;
个性化上也有人格表现,但会出现原形的情况;
专业性表现也基本无事实性错误,尤其医疗能力水平,给出适时诊疗提醒。
每个人的AI助手时代正在到来
除了星火大模型本身,此次科大讯飞1024开发者节可谓是干货满满——
不光有编程产品iFlyCode、科技文献大模型、医疗大模型等这些垂直领域大模型落地应用;还有同与行业龙头共创12个行业大模型、10万家企业用户,通用大模型产业生态初见雏形;另外,超脑计划2030也在有序进行。
可以说是眼花缭乱了。

但细细梳理不难发现,这些进展其实围绕着一个底层逻辑——
每个人的AI助手时代正在到来 。
正如刘庆峰在发布会上所强调的那样。这也是科大讯飞基于大模型技术发展的趋势理解。
ChatGPT刚出现时,就曾探讨过以ChatGPT为代表的大模型产品强大之处在于同时具备知识、推理和沟通能力。
一方面,这是实现认知智能必备的几项能力;另一方面,也是个人AI助手场景相契合。
前者是科大讯飞一直以来的技术深耕,后者则是科大讯飞在工业、科研、医疗、教育、智能汽车,甚至超脑计划的最终落地形态。
以教育为例,科大讯飞就认为目前教育「因材施教」进入到第三个层次:类人式对话辅导,进行逐层讲解。
基于这样的逻辑,从科大讯飞半年落地成果,也就能从中窥见大模型发展一二。
首先是应用和业务场景。
科大讯飞认为,大模型赋能首要就是工业和科研。而要赋能工业,则首先要赋能代码。
iFlyCode。
8月15日iFlyCode发布以来,已有62万开发者应用、107家机构深度应用。
比如“智慧教育大屏”性能优化,传统方案需要15天解决,在iFlyCode辅助下只需7天。
本次iFlyCode2.0在设计阶段、编码阶段、自测阶段都有一定的升级。

科技文献大模型。
同中科院知识文献中心合作,有着包括成果调研、论文研读、学术写作、生成论文代码、润色、学术翻译等功能,可以化身当下高校研究生的科研小助手。
给一篇中文文献,结果一键就能生成英文版。

还能与时俱进、补充跨领域知识,比如一篇大模型文章,问到ChatGPT发展历程,还补充了现下GPT-4的发展。
医疗大模型。
它能根据体检报告、检查报告进行解读。
传统体检报告一般会有单项解读,以及像复查这种比较粗放的结论。而讯飞晓医不光给出具体指数指标,还会主动询问最近身体情况,联合各个单项结果并更新风险等级。

还可以根据药品照片、自身情况,给出用药建议,比如禁忌、推荐等。
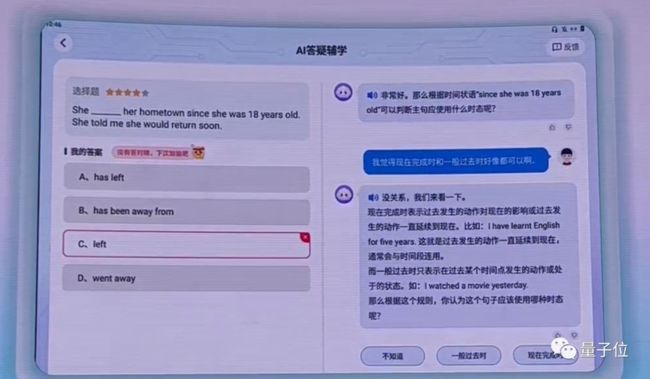
除此之外,还有科大讯飞历来深耕的教育领域,讯飞AI学习机升级了英语AI答疑赋学;同科普中国一起合作发布科普大模型;还打造了AI心理伙伴等等,因材施教已取得规模化应用成果,在全国50000+所学校深度应用。
当然,这些进展其实都是加速讯飞超脑2030计划一部分——懂知识、善学习、能进化、让机器人走进每个家庭。
AIBOT去年发布以来,已为工业、教育、服务等领域372家企业提供服务。
中国玩家大模型加速度优势明显
不可否认的是,以星火大模型等为代表的国产大模型,在确定性方向上发展优势明显。
并且同样保持着同样明显且持续的加速度。
已经形成全球共识的,当前大模型发展已经进入到第二阶段——
大模型AI产品从炒作、演示Demo、到真正的价值导向,用户导向、场景导向。
像微软谷歌亚马逊在内的全球巨头,却面临增长的烦恼:不仅不赚钱,还要倒贴。
以AI编程工具GitHub Copilot为例,微软平均每个月在每个用户身上都要倒贴20美元,最高能达80美元。
个中原因,用户找不到为大模型产品付费的理由。
更本质一点来说,大模型尚未发挥出最大的价值效能。
在这一方面上,中国玩家正在展现出自己的产业发展优势,并且优势明显。
有场景。前一波技术浪潮,AI能落地到千行百业,大模型技术同样也能落地千行百业。一方面,我国有着全球最完整的产业体系,为大模型的落地应用提供了广阔的创新空间;另一方面,在一些场景中,我国还有着不同于其他的独特优势。像教育、医疗,要实现真正的全民普惠,对技术其实提出了更高的要求。
有数据。数据的价值,从未像今天这样受到前所未有的关注。场景数据质量的好坏,直接决定了大模型的性能表现。
此前国内AI应用,已经有深厚的场景积累。如科大讯飞的认知智能技术已经在教育、医疗、金融、汽车、服务等多个领域落地,并构筑起了深厚的行业壁垒。
根据IDC研究显示,中国数据量规模将从2022的23.88ZB增长至2027年的76.6ZB,复合年均增长速度(CAGR)达到26.3%,为全球第一,为大模型的持续优化提供了海量的数据来源。
有市场。ChatGPT作为通用人工智能的代表,本身不是项好生意。OpenAI商业化只是少数,身处于国内市场大环境下的企业,通用路线往往不是一个最佳选择。垂直场景应用路线更受国内市场青睐。
有场景有数据有市场,也再次印证中国玩家率先吃到ChatGPT红利,如今发展加速度明显。
从科大讯飞的迭代应用速度就可见一斑。

今年2月,科大讯飞首次回应:在搞类ChatGPT产品,并给出确定时间点;
5月,讯飞星火V1.0正式发布,在语义理解,长文本生成以及数据能力三方面,据称“已经超过了ChatGPT”,并直接展现五大应用成果。
6月,星火升级至V1.5;8月,讯飞星火V2.0发布,多模态能力实现。
10月,科技文献大模型、医疗大模型等12大行业大模型发布,通用人工智能产业生态初具雏形。
……
当下大模型的发展进入到了冷静期,每个企业都在思考如何能让大模型充分发挥价值效能。即便如OpenAI的奥特曼,也在寻找自身第二增长点。
关于大模型的评测和判断,不再看发布效率、榜单分数,而是看实际应用、看产业应用生态。
这背后既需要国内底层软硬生态更紧密的合作——华为昇腾生态“飞星一号”平台发布。
也需要同行业龙头、万千开发者一起共建起通用大模型产业生态。目前关于星火大模型开发者已经有17.8万,涵盖各个领域。
大模型时代的序幕才刚刚到来。
好了,对于刘庆峰说的「明年上半年对标GPT-4」的Flag,你怎么看?
— 完 —
点这里关注我,记得标星哦~