DB-GPT发布:用私有LLM技术彻底改革数据库互动
01
项目介绍
随着大模型的发布迭代,大模型变得越来越智能,在使用大模型的过程当中,遇到极大的数据安全与隐私挑战。在利用大模型能力的过程中我们的私密数据跟环境需要掌握自己的手里,完全可控,避免任何的数据隐私泄露以及安全风险。基于此,我们发起了DB-GPT项目,为所有以数据库为基础的场景,构建一套完整的私有大模型解决方案。此方案因为支持本地部署,所以不仅仅可以应用于独立私有环境,而且还可以根据业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。我们的愿景是让围绕数据库构建大模型应用更简单,更方便。
DB-GPT 是一个开源的以数据库为基础的GPT实验项目,使用本地化的GPT大模型与您的数据和环境进行交互,无数据泄露风险,100% 私密。
02
特性一览
目前已经发布了多种关键的特性,这里一一列举展示一下当前发布的能力。
私域问答&数据处理
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
多数据源&可视化
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。
Multi-Agents&Plugins
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准
多模型支持与管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱等。
隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全。
支持数据源
DataSource、MySQL、PostgresSQL、Spark、DuckDB、Sqlite、MSSQL、ClickHouse。
03、
架构方案
DB-GPT基于FastChat 构建大模型运行环境。此外,我们通过LangChain提供私域知识库问答能力。同时我们支持插件模式, 在设计上原生支持Auto-GPT插件。我们的愿景是让围绕数据库和LLM构建应用程序更加简便和便捷。整个DB-GPT的架构,如下图所示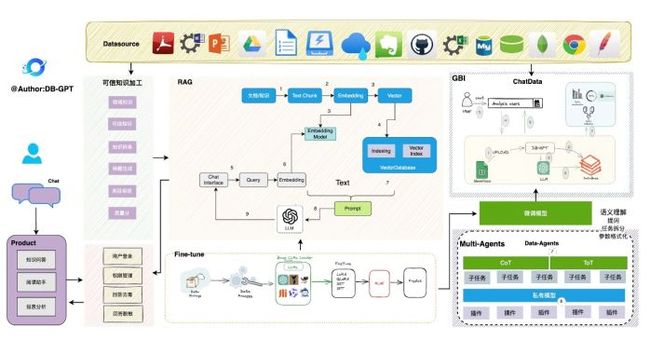 核心能力主要有以下几个部分。
核心能力主要有以下几个部分。
1.多模型:支持多LLM,如LLaMA/LLaMA2、CodeLLaMA、ChatGLM、QWen、Vicuna以及代理模型ChatGPT、Baichuan、tongyi、wenxin等
2.私域知识库问答: 可以根据本地文档(如pdf、word、excel等数据)进行高质量的智能问答。
3.统一数据向量存储和索引: 将数据嵌入为向量并存储在向量数据库中,提供内容相似性搜索。
4.多数据源: 用于连接不同的模块和数据源,实现数据的流动和交互。
5.Agent与插件: 提供Agent和插件机制,使得用户可以自定义并增强系统的行为。
6.隐私和安全: 您可以放心,没有数据泄露的风险,您的数据100%私密和安全。
7.Text2SQL: 我们通过在大型语言模型监督微调(SFT)来增强文本到SQL的性能
RAG生产落地实践架构
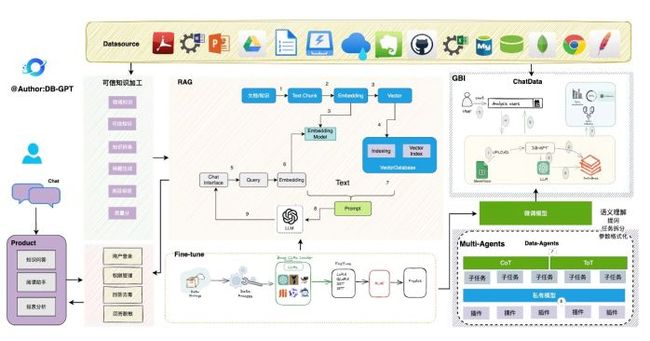
子模块
DB-GPT-Hub 通过微调来持续提升Text2SQL效果
https://github.com/eosphoros-ai/
DB-GPT-Hub·DB-GPT-Plugins DB-GPT 插件仓库, 兼容Auto-GP
Thttps://github.com/eosphoros-ai/
DB-GPT-Plugins·DB-GPT-Web 多端交互前端界面
https://github.com/eosphoros-ai/DB-GPT-Web
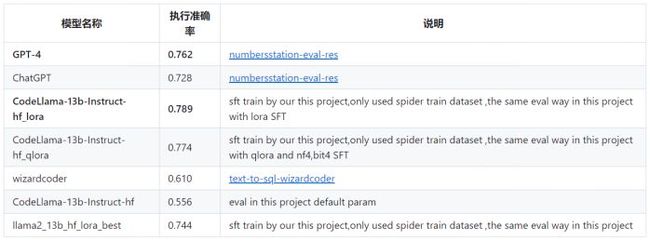
SFT模型准确率 截止20231010,利用本项目基于开源的13B大小的模型微调后,在Spider的评估集上的执行准确率,已经超越GPT-4!