Linux调度器负载计算之PELT
/******以下结论和代码分析都是基于最新Linux master分支(Linux5.0)******/
PELT算法中,每个周期为1024us(方便移位操作),也可以认为是1毫秒. 一个进程对系统负载贡献,包含当前负载和历史负载,对于过去的负载在计算时需要乘一个衰减因子,如果Li表示在周期i中该调度实体的对系统负载贡献,那么一个调度实体对系统负荷的总贡献可以表示为:
L= L0 + L1*y + L2*y2 + L3*y3 + Li*y^i + ...... + Ln*y^n ;
其中y是衰减因子,L0表示当前周期负载值,通过上面的公式可以看出:
(1) 调度实体对系统负荷的贡献值是一个序列之和组成
(2) 最近的负荷值拥有最大的权重
(3) 过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
(4) y32 = 0.5, y = 0.97857206,可以看出每经过32个周期,衰减值减半.
(5) 使用这个公式,内核不用维护n个周期的负载值,只需要记录上一次负载和,因为根据公式很容易得到Ln = L0 + Ln-1*y
(6) PELT是计算累加时间的衰减和。load = 累加时间衰减值* weight
1. 衰减负载值计算
比如过去的第32个周期负载值为100,那么对当前周期的负载贡献值=100*y32 = 51 可以看到大概减半了.
内核提供一张表,可以快速查找过去[1,32]周期负载值,对当前周期的负载贡献值
static const u32 runnable_avg_yN_inv[] = {/* 为了避免浮点(除法)计算,每项乘以2^32次方,计算完后,再右移32位*/
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
Linux内核函数decay_load函数了第n个周期的衰减负载值计算,就是根据runnable_avg_yN_inv.
2. 当前负载贡献(负载值)计算
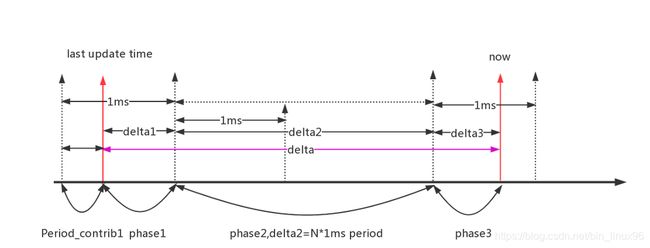
下面我们推导计算当前负载贡献的过程. 首先需要有Ln = L0 + (Ln-1)*y
设上一次统计(last update time)时的负载贡献Period_contrib1 = prev,且到当前时间now经过了delta = delta1 + delta2 + delta3
经过的周期p = (deltal + (1024-delta1))/1024,假如p = 3 ;
L0 = prev + deltal1
L1 = (prev+deltal1)*y + 1024
L2 = ((prev+deltal1)*y+1024)*y + 1024
L3 =(((prev+delta1)*y + 1024)*y + 1024)*y + 1024 +delta3
从而可以得出当前负载值Ln = (prev+deltal1)*y^p + 1024(y + y^2 + y^3 + .... + y^p-1) + delta3
可以分成三项:Ln = s1 + s2 + s3
s1 = (prev+deltal1)*y^p,
s2 = 1024(y + y^2 + y^3 + .... + y^p-1)
s3 = deltal3
s1可以直接利用衰减数组查表得出. 且当p非常大时(内核定义为2016个1024us),s1==0
我们把S2继续分解,
s2 = 1024*(y^1 + y^2 + ... +y^p-1)
s2a= (y^0 + y^1+y^2 + ... + y^n)
s2b = (y^p + y^p+1 + ..... y^n)=s2a*y^p
从而s2 = 1024(s2a - s2b - y^0) = 1024(s2a-s2b-1024)= s2a - s2a*y^p - 1024
我们知道s2a是等比数列,等比数列求和Sn = (a1 *(1-q^n))/(1-q),当q小于1,且n无穷大时,最大值max=1024*a1/(1-q)= y/(1-y) =47742= LOAD_AVG_MAX,所以有s2 = max - max*y^p -1024
s3是常量,且小于1024.
所有当前负载贡献值Ln = s1 + s2 + s3 = (prev)*y^p + (delta1*y^p + max - max*y^p -1024 ) + delta3
可以把当前负载值理解为以上3部分.Linux内核计算函数为accumulate_sum(基于Linux内核5.0.0版本)
static u32
accumulate_sum(u64 delta, int cpu, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
unsigned long scale_freq, scale_cpu;
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
scale_freq = arch_scale_freq_capacity(cpu);
scale_cpu = arch_scale_cpu_capacity(NULL, cpu);
delta += sa->period_contrib;/*period_contrib可以理解为上一次计算负载时的delta3 */
periods = delta / 1024; /* 计算经过了多少个周期 */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods);/*公式中的第一部分 */
sa->runnable_load_sum =
decay_load(sa->runnable_load_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024; /*计算delta3 , delta1 = 1024 - sa->period_contrib */
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);/*计算第二部分和第三部分的和 */
}
sa->period_contrib = delta;/*记录当前delta3到下一次使用 */
contrib = cap_scale(contrib, scale_freq);
if (load)
sa->load_sum += load * contrib;/*这里load为1 ,也可能是当前进程的权重,需要根据上下文判断*/
if (runnable)
sa->runnable_load_sum += runnable * contrib;
if (running)
sa->util_sum += contrib * scale_cpu;
return periods;
}
根据推导的最终公式,就很容易理解下面的函数了
Ln = s1 + s2 + s3 = (prev)*y^p + (delta1*y^p + max - max*y^p -1024 ) + deltal3
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}
从这里也可以看出,最新内核已经放弃了runnable_avg_yN_sum数组
负载更新函数:
static __always_inline int
___update_load_sum(u64 now, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
/*距离上一次更新负载时间 */
delta = now - sa->last_update_time;
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
最小单位为1us,去掉纳秒
*/
delta >>= 10;
if (!delta)
return 0;
/*更新负载时间 */
sa->last_update_time += delta << 10;
/*
* running is a subset of runnable (weight) so running can't be set if
* runnable is clear. But there are some corner cases where the current
* se has been already dequeued but cfs_rq->curr still points to it.
* This means that weight will be 0 but not running for a sched_entity
* but also for a cfs_rq if the latter becomes idle. As an example,
* this happens during idle_balance() which calls
* update_blocked_averages()
*/
if (!load)
runnable = running = 0;
/*调用accumulate_sum计算负载 */
if (!accumulate_sum(delta, sa, load, runnable, running))
return 0;
return 1;
}
参考资料
http://www.wowotech.net/process_management/PELT.html
http://www.wowotech.net/process_management/450.html