Kettle体系结构及源码解析
介绍
- ETL是数据抽取(Extract)、转换(Transform)、装载(Load)的过程。
- Kettle是一款国外开源的ETL工具,有两种脚本文件transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
- Job:一个作业,由不同逻辑功能的entry组件构成,数据从一个entry组件传递到另一个entry组件,并在entry组件中进行相应的处理。
- Transformation:完成针对数据的基础转换,即一个数据转换过程。
- Entry:实体,即job型组件。用来完成特定功能应用,是job的组成单元、执行单元。
- Step:步骤,是Transformation的功能单元,用来完成整个转换过程的一个特定步骤。
- Hop:工作流或转换过程的流向指示,从一个组件指向另一个组件,在kettle源工程中有三种hop,无条件流向、判断为真时流向、判断为假时流向。
体系结构

kettle平台是整个系统的基础,包括元数据管理引擎、数据集成引擎、UI和插件管理模块。
元数据管理引擎
元数据管理引擎管理ktr、kjb或者元数据库,插件通过该引擎获取基本信息,主要包括TransMeta、JobMeta和StepMeta三个类。
- TransMeta类,定义了一个转换(对应一个.ktr文件),提供了保存和加载该文件的方法;
- JobMeta类,同样对应于一个工作(对应一个.kjb文件),提供保存和加载方法;
- StepMeta类,保存的是Step的一些公共信息的类,每个类的具体的元数据将保存在显示了StepMetaInterface的类里面。
数据集成引擎
数据集成引擎包括Step引擎、Job引擎和数据库访问引擎三大部分,主要负责调用插件,并返回相应信息。
UI
UI显示Spoon这个核心组件的界面,通过xul实现菜单栏、工具栏的定制化,显示插件界面接口元素,其中的TransGraph类和JobGraph类是用于显示转换和Job的类。
- TransGraph类
选中转换标签后,红框内的编辑区对象对应org.pentaho.di.ui.spoon.trans包中的TransGraph类。
- JobGraph类
选中Job标签后,红框内的编辑区对象对应org.pentaho.di.ui.spoon.job包中的JobGraph类。

- 插件管理模块
Kettle是众多“可供插入的地方”(扩展点)和“可以插入的东西”(扩展)共同组成的集合体。在我们的生活中,电源接线板就是一种“扩展点”,很多“扩展”(也就是电线插头)可以插在它上面。
插件管理引擎主要负责插件的注册,在Kettle中不管是以后的扩展还是系统集成的功能,本质上来讲都是插件,管理方式和运行机制是一致的。系统集成的功能点也均实现了对应的扩展接口,只是在插接的说明上略有不同。
Kettle的扩展点包括step插件、job entry插件、Database插件、Partioner插件、debugging插件。
功能模块
Kettle的主要包括四大功能模块:
- Chef——工作(job)设计工具 (GUI方式);
- Kitchen——工作(job)执行器(命令行方式);
- Spoon——转换(transform)设计工具 (GUI方式);
- Span——转换(trasform)执行器(命令行方式)。
- Chef—工作(job)设计器
这是一个GUI工具,操作方式主要通过拖拽。
何谓工作?多个作业项,按特定的工作流串联起来,形成一项工作。正如:我的工作是软件开发。我的作业项是:设计、编码、测试!先设计,如果成功,则编码,否则继续设计,编码完成则开始设计,周而复始,作业完成。- Chef中的作业项
- 转换:指定更细的转换任务,通过Spoon生成,通过Field来输入参数;
- SQL:sql语句执行;
- FTP:下载ftp文件;
- 邮件:发送邮件;
- 检查表是否存在;
- 检查文件是否存在;
- 执行shell脚本:如dos命令。
- 批处理:(注意:windows批处理不能有输出到控制台)。
- Job包:作为嵌套作业使用。
- JavaScript执行:如果有自已的Script引擎,可以很方便的替换成自定义Script,来扩充其功能;
- SFTP:安全的Ftp协议传输;
- HTTP方式的上传/下载。
- 工作流
工作流是作业项的连接方式,分为三种:无条件,成功,失败。
为了方便工作流使用,KETTLE提供了几个辅助结点单元(也可将其作为简单的作业项):- Start单元:任务必须由此开始。设计作业时,以此为起点。
- OK单元:可以编制做为中间任务单元,且进行脚本编制,用来控制流程。
- ERROR单元:用途同上。
- DUMMY单元:什么都不做,主要是用来支持多分支的情况。
- 存储方式
支持XML存储,或存储到指定数据库中。
一些默认的配置(如数据库存储位置……),在系统的用户目录下,单独建立了一个.Kettle目录,用来保存用户的这些设置。 - LogView
可查看执行日志。
- Chef中的作业项
- Kitchen—作业执行器
是一个作业执行引擎,用来执行作业。这是一个命令行执行工具,参数如下:- rep : Repository name 任务包所在存储名
- user : Repository username 执行人
- pass : Repository password 执行人密码
- job : The name of the job to launch 任务包名称
- dir : The directory (don’t forget the leading / or /)
- file : The filename (Job XML) to launch
- level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志级别
- log : The logging file to write to 指定日志文件
- listdir : List the directories in the repository 列出指定存储中的目录结构。
- listjobs : List the jobs in the specified directory 列出指定目录下的所有任务
- listrep : List the defined repositories 列出所有的存储
- norep : Don’t log into the repository 不写日志
- Spoon—转换过程设计器
GUI工作,用来设计数据转换过程,创建的转换可以由Pan来执行,也可以被Chef所包含,作为作业中的一个作业项。- Input-Steps:输入步骤
- Text file input:文本文件输入
可以支持多文件合并,有不少参数,基本一看参数名就能明白其意图。
Table input:数据表输入
实际上是视图方式输入,因为输入的是sql语句。当然,需要指定数据源(数据源的定制方式在后面讲一下) - Get system info:取系统信息
就是取一些固定的系统环境值,如本月最后一天的时间,本机的IP地址之类。 - Generate Rows:生成多行。
这个需要匹配使用,主要用于生成多行的数据输入,比如配合Add sequence可以生成一个指定序号的数据列。 - XBase Input
- Excel Input
- XML Input
- Text file input:文本文件输入
- Output-Steps: 输出步聚
- Text file output:文本文件输出。这个用来作测试蛮好,呵呵。很方便的看到转换的输出。
- Table output:输出到目的表。
- Insert/Update:目的表和输入数据行进行比较,然后有选择的执行增加,更新操作。
- Update:同上,只是不支持增加操作。
- XML Output:XML输出。
- Look-up:查找操作
- Data Base
- Stream
- Procedure
- Database join
- Transform 转换
- Select values
对输入的行记录数据的字段进行更改 (更改数据类型,更改字段名或删除) 数据类型变更时,数据的转换有固定规则,可简单定制参数。可用来进行数据表的改装。 - Filter rows
对输入的行记录进行指定复杂条件的过滤。用途可扩充sql语句现有的过滤功能。但现有提供逻辑功能超出标准sql的不多。
- Select values
- Sort rows
对指定的列以升序或降序排序,当排序的行数超过5000时需要临时表。 - Add sequence
为数据流增加一个序列,这个配合其它Step(Generate rows, rows join),可以生成序列表,如日期维度表(年、月、日)。 - Dummy
不做任何处理,主要用来作为分支节点。 - Join Rows
对所有输入流做笛卡儿乘积。 - Aggregate
聚合,分组处理 - Group by
分组,用途可扩充sql语句现有的分组,聚合函数。但我想可能会有其它方式的sql语句能实现。 - Java Script value
使用mozilla的rhino作为脚本语言,并提供了很多函数,用户可以在脚本中使用这些函数。 - Row Normaliser
该步骤可以从透视表中还原数据到事实表,通过指定维度字段及其分类值,度量字段,最终还原出事实表数据。 - Unique rows
去掉输入流中的重复行,在使用该节点前要先排序,否则只能删除连续的重复行。 - Calculator
提供了一组函数对列值进行运算,用该方式比用户自定义JAVA SCRIPT脚本速度更快。 - Merge Rows
用于比较两组输入数据,一般用于更新后的数据重新导入到数据仓库中。 - Add constants:
增加常量值。 - Row denormaliser
同Normaliser过程相反。 - Row flattener
表扁平化处理,指定需处理的字段和扃平化后的新字段,将其它字段做为组合Key进行扃平化处理。
除了上述基本节点类型外还定义了扩展节点类型 - SPLIT FIELDS:按指定分隔符拆分字段;
- EXECUTE SQL SCRIPT:执行SQL语句;
- CUBE INPUT:CUBE输入;
- CUBE OUTPUT:CUBE输出。
- Input-Steps:输入步骤
- Pan—转换的执行工具
命令行执行方式,可以执行由Spoon生成的转换任务。同样,不支持调度。参数与Kitchen类似。 - 其它
- Connection
可以配置多个数据源,在Job或是Trans中使用,这意味着可以实现跨数据库的任务。支持大多数市面上流行的数据库。
- Connection
概念模型
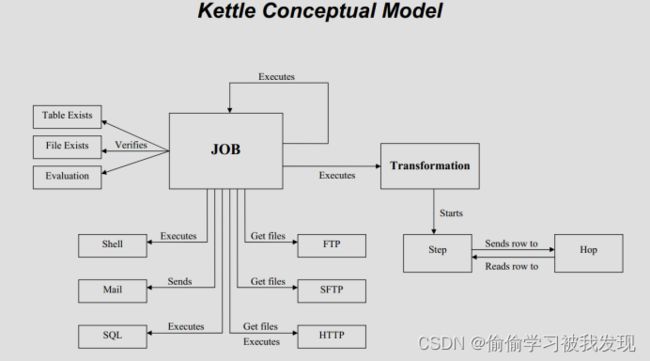
Kettle的执行分为两个层次:Job和Transformation。两个层次的最主要区别在于数据传递和运行方式。
Transformation(转换)
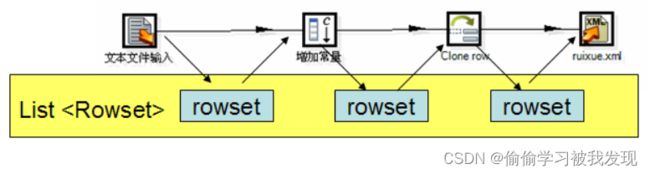
Transformation(转换)是由一系列被称之为step(步骤)的逻辑工作的网络。转换本质上是数据流。
下图是一个转换的例子,这个转换从文本文件中读取数据,过滤,然后排序,最后将数据加载到数据库。本质上,转换是一组图形化的数据转换配置的逻辑结构。
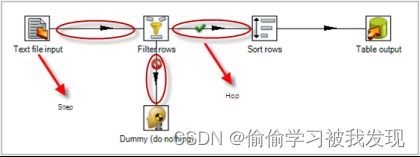
转换的两个相关的主要组成部分是step(步骤)和hops(节点连接)。
转换文件的扩展名是.ktr。
- 转换机制
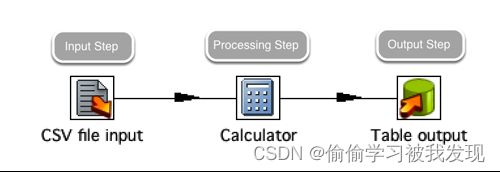
每个转换步骤都是ETL数据流里面的一个任务。
转换步骤包括输入、处理和输出。
输入步骤从外部数据源获取数据,例如文件或者数据库;
处理步骤处理数据流,字段计算,流处理等,例如整合或者过滤。
输出步骤将数据写回到存储系统里面,例如文件或者数据库。
- Steps(步骤)
Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。- Step类图简介
每个类都有其特定的目的及扮演的角色。以TableInput为例,下图说明了这4个类的继承体系。-
StepInterface继承体系:
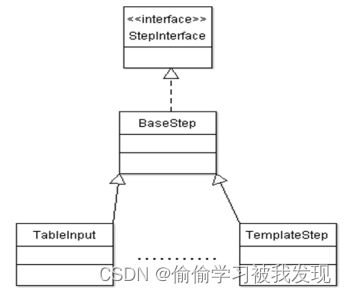
实现StepInterface接口的类,在转换运行时,将是数据实际处理的位置。每个执行线程都表示一个实现StepInterface的实例。
BaseStep实现了StepInterface是各step具体实现类的基类。完成了公用的处理函数,如putRow(),但是对于更具体的processRow()在StepBase的子类中。StepBase的主要成员有
public ArrayList inputRowSets,outputRowSets;
StepBase的子类每次从inputRowSets中取出一行数据,向outputRowSets中写入一行数据。 -
StepDataInterface继承体系:
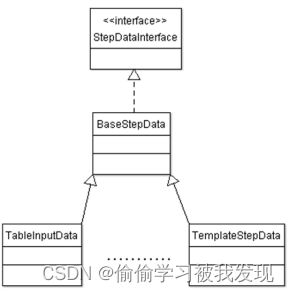
实现StepDataInterface接口的类为数据类,当插件执行时,对于每个执行执行的线程都是唯一的。保存于step相关的数据信息,比如行的元数据信息。 -
StepMetaInterface继承体系

实现了StepMetaInterface接口的类为元数据类。它的职责是保存和序列化特定步骤的实例配置,例如保存步骤的名称、字段名称等,如何生成加载xml或者读写数据库。 -
StepDialogInterface继承体系

实现了StepDialogInterface接口的类为对话框类,该类实现了该步骤与用户交互的界面,它显示一对话框,通过对话框用户可以根据自己的要求进行步骤的设定。该对话框类与元数据类关系非常密切,对话框里面的配置数据均会保存在元数据类里面。
-
- Step类图简介
- 步骤间交互通信类
-
步骤之间通信机制:
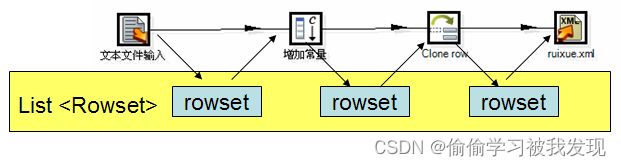
RowSet的实现类,负责步骤之间的相互通信,rowset对象即是前一个step的成员也是后一个step的成员,访问是线程安全的。 -
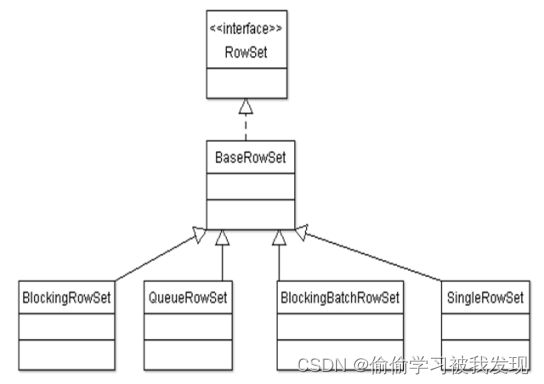
RowSet实现类内存快照:

RowSet类中包含源step,目标step和由源向目标发送的一个rowMeta和一组data。其中data数据是以行为单位的队列(queArray)。一个RowSet作为此源step的outputrowsets的一部分。同时作为目标step的inputRowsets一部分。源Step每次向队列中写一行数据,目标step每次从队列中读取一行数据。 -
RowSet实现类:
-
- 行元数据
行元数据UML类图:
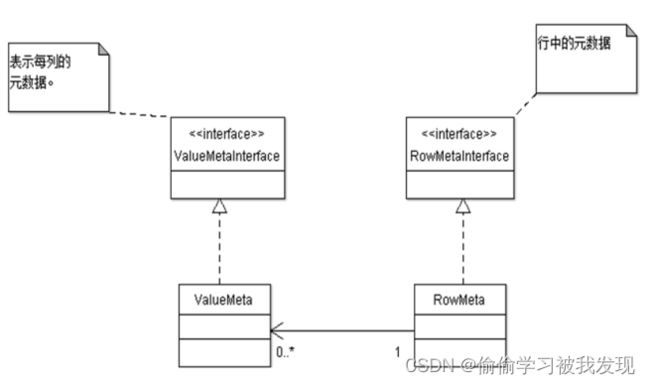
所有的data均为object对象。步骤与步骤之间以行为单位进行处理,自然需要知道每行的结构,即行元数据。行元数据至少需要包括类型、名称,当然还可能包括字段长度、精度等常见内容。
行元数据不仅在执行的时候需要,而且在转换设置的时候同样需要。每个步骤的行元数据都会保存在.ktr文件或者数据库里面,所以可以根据步骤名称从TransMeta对象中获取行元数据。
行元数据的UML类图结构如下所示,主要有单元格元数据组成行元数据。在现有的版本中,支持的数据类型有String、Date、BigNumber、Boolean、SerializableType、Binary、Integer、Numberic。
- Hops(节点连接)
Hops(节点连接)是数据的通道,用于连接两个步骤,使得元数据从一个步骤传递到另一个步骤。节点连接决定了贯穿在步骤之间的数据流,步骤之间的顺序不是转换执行的顺序。当执行一个转换时,每个步骤都以自己的线程启动,并不断的接受和推送数据。
注意:所有的步骤是同步开启和运行的,所以步骤的初始化的顺序是不可知的。因为我们不能在第一个步骤中设置一个变量,然后在接下来的步骤中使用它。
在一个转换中,一个步骤可以有多个连接,数据流可以从一个步骤流到多个步骤。在Spoon中,hops就想是箭,它不仅允许数据从一个步骤流向另一个步骤,也决定了数据流的方向和所经步骤。如果一个步骤的数据输出到了多个步骤,那么数据既可以是复制的,也可以是分发的。 - Trans配置及开启
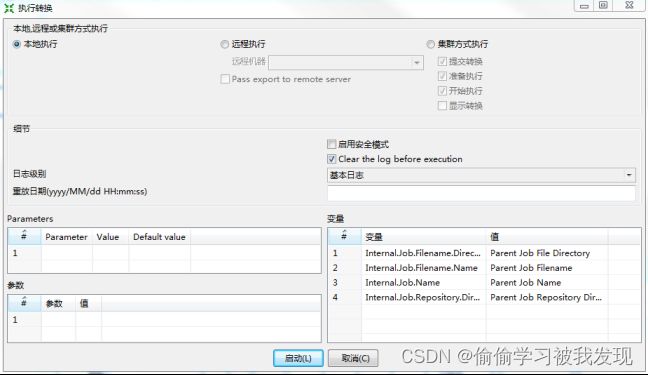
Trans执行时序图

在真正运行trans之前,还需要对运行模式进行一个设置。设置结果,会传给TransGraph.start(executionConfiguration)。配置界面如下所示:
执行转换模式设置
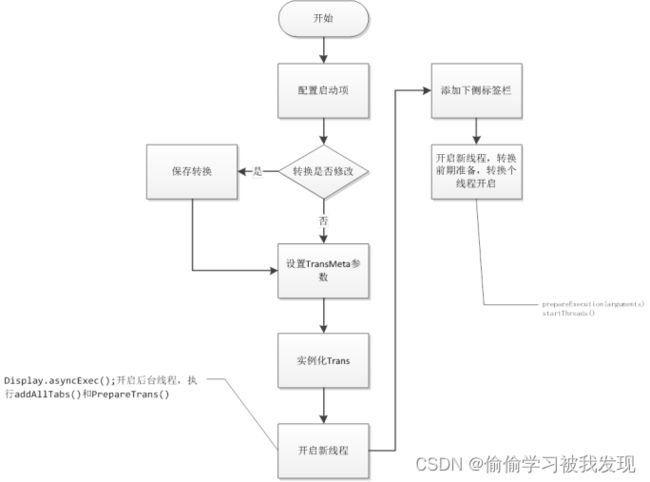
实例化Trans的基本流程如下,Trans类是最后真正执行转换的类。实例化之前需要配置启动项,保持.ktr文件同步,然后实例化Trans类。最后,开启后台程序,这样不会影响UI的操作,真正的转换在后台执行。
实例化Trans流程图:
- Trans执行
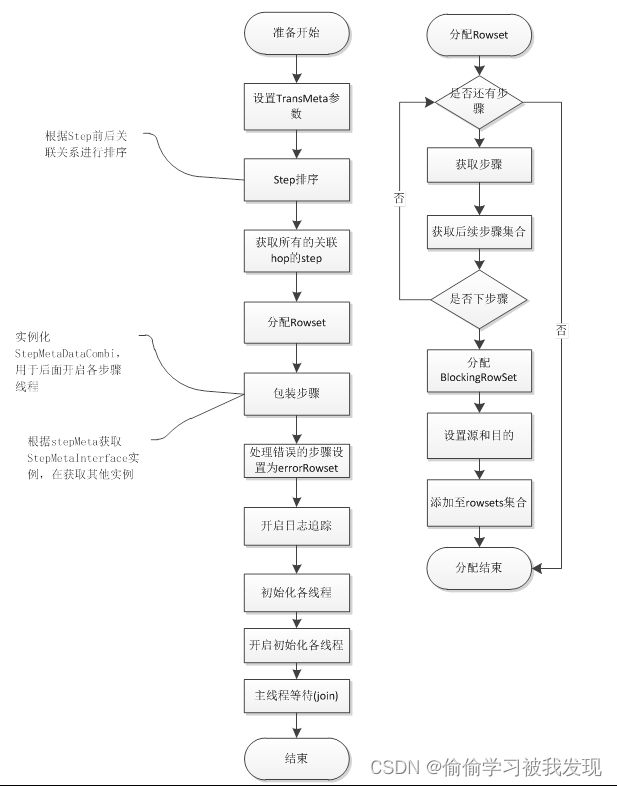
trans类的执行由execute()负责,主要包含两个步骤:转换执行前的准备工作和所有线程的开启。Trans每一个步骤都会对应一个独立的线程,线程之间通过RowSet进行通信交互。- 执行准备(prepareExecution)
主要完成对通信类的初始化,对步骤的包装初始化。最后启动各个步骤初始化线程,即调用各个步骤的init()方法。准备结束之后,步骤之间的通信机制完成了,各个步骤的初始化工作也完成了。具体的流程如下所示:
准备执行流程图
- 转换处理执行
Trans转换执行引擎类,通过startThreads()启动步骤线程。为所有步骤添加监听器,在开启监听进程对所有线程进行监听。具体的步骤如下图所示:
启动所有步骤线程
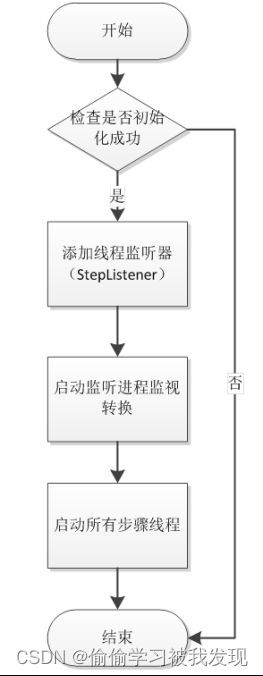
- 执行准备(prepareExecution)
- Jobs(工作)
Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动。
Jobs(工作)将功能性和实体过程聚合在了一起,由工作节点连接、工作实体和工作设置组成,工作文件的扩展名是.kjb。
下图是一个工作的例子。

一个工作中展示的任务有从FTP获取文件、核查一个必须存在的数据库表是否存在、执行一个转换、发送邮件通知一个转换中的错误等。最终工作的结果可能是数据仓库的更新等。 - 机制
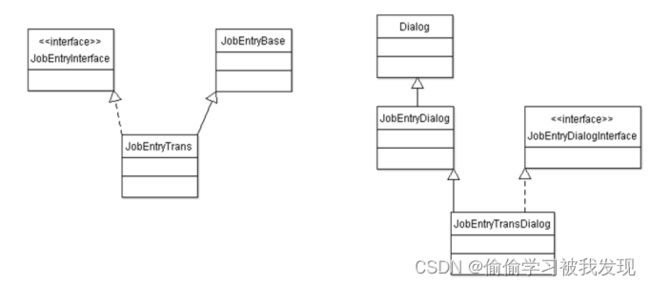
一个job项代表ETL控制流中的一项逻辑任务。Job项将会顺序执行,每个job项会产生一个结果,能作为别的分支上job项的条件。 - 类图简介
Job entry类图结构
- Job配置及开启
Job开启时序图
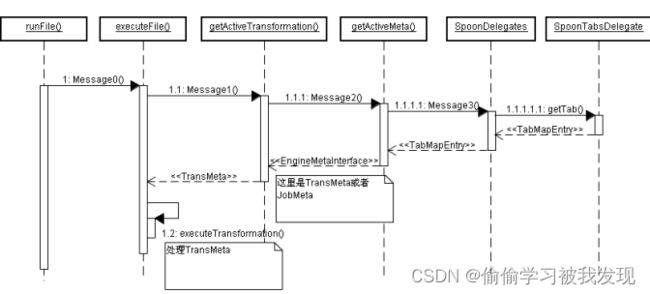
Job的开启与Trans相类似,配置执行的参数,检查.kjb文件是否发生变化,实例化一个Job对象,开启该线程。 - Job执行步骤
kettle数据流图
程序正常工作需要3种类型的文件:
- 配置文件
程序首先是从系统中读取相关的配置文件,用来初始化程序。然后加载组件库到程序中,组件的加载需要用到相关的XML文件和图标。 - 工作文件
Kjb文件是job的工作文件,ktr文件是transformation的工作文件,要打开或者运行一个job或者transformation,需要存在相应的kjb或ktr文件。 - 数据文件
需要处理的数据。 - 顶层数据流图
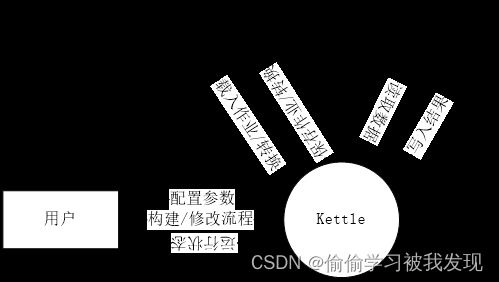
- 第一层数据流图
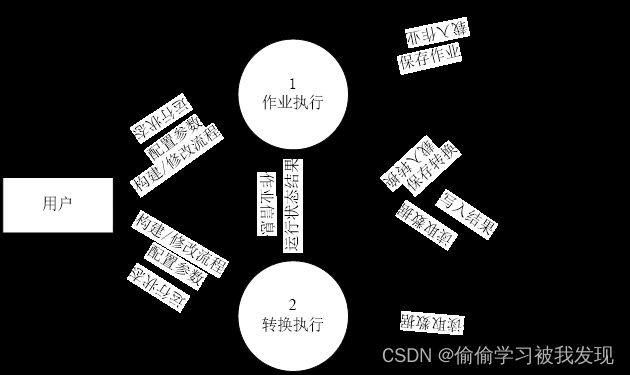
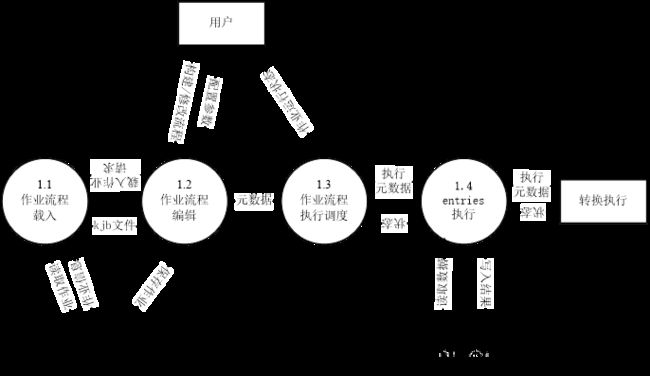
- 第二层数据流图
- 作业执行
转换执行
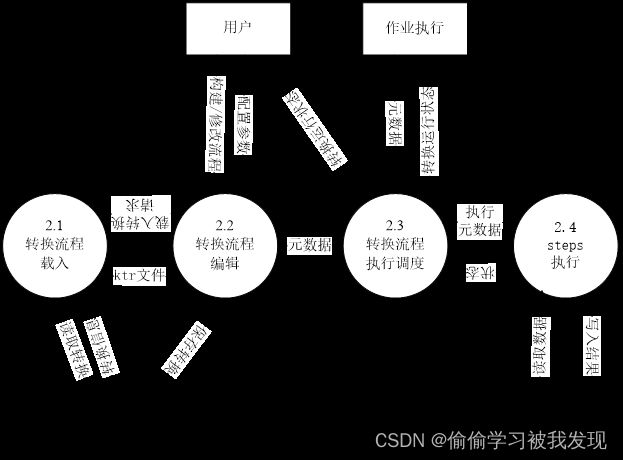
- 作业执行
插件扩展机制
Kettle并不能做到热插拔,每次添加或者删除插件的时候都需要重启。安装或删除插件,只需要在plugins文件夹下添加或删除对应的文件即可。
Kettle的扩展点包括step插件、job entry插件、Database插件、Partioner插件、debugging插件,这里我们重点介绍step、job entry、database插件。暴露的扩展点如下表所示:
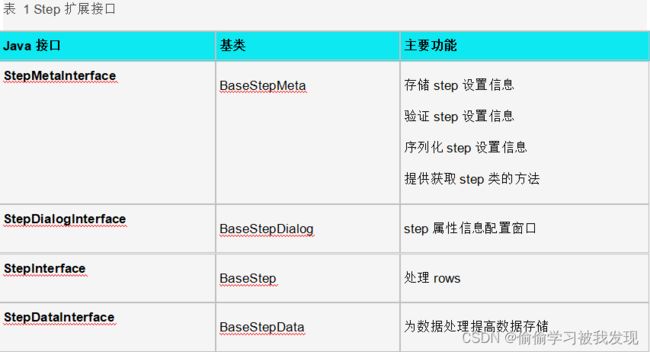

- 插件的建立
Kettle中的插件包含两部分,一是系统本身就已经实现的功能点,在源码目录src中说明,如kettle-steps.xml;二是系统之外开发的插件,在plugins目录对应插件目录下的plugins.xml说明,plugins/steps/S3CsvInput/plugins.xml。- 系统集成插件定义

插件说明信息中包括描述信息、类名(包括package,反射用)、父级目录(Spoon左侧栏目录)、提示信息和图片信息。Kettle使用国家化方式编程,所以软件中的所有文字描述均由messages_**.properties提供。
系统集成插件说明xml结构如下:

- 扩展插件定义
所有新开发的扩展插件,均放在同一的目录下进行管理,插件管理模块会自动去该目录下进行搜索查找。插件目录结构如下所示:
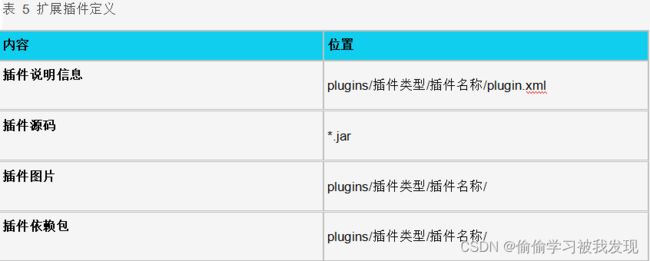
扩展插件与系统集成插件的说明内容相似,扩展插件增加ID属性和依赖属性,同时他的目录结构、描述信息和提示信息均能进行国际化配置。
扩展插件说明xml结构如下:

- 系统集成插件定义
- 插件的注册
Spoon在启动的时候会对所有插件进行注册,并保存在PluginRegistry类里面。平台通过查找PluginRegistry注册表获取插件信息。Kettle安装插件需要进行重启,卸载插件也只需简单的删除plugins目录结构下对应的文件即可。
插件注册时序图

plugin注册相关的UML类图
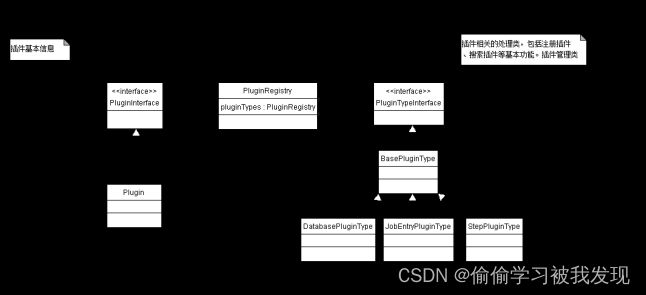
- 插件查找
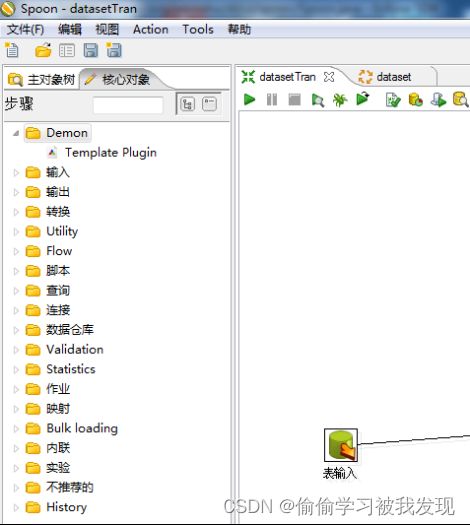
PluginRegistry提供了插件查找功能,准确的来说是插件信息的查找功能。以steps在左侧功能栏里面的显示为例,进行插件查找的说明。提供了getPlugins获取指定插件类型列表、getPlugin获取指定成名插件、getCateories获取目录结构、getClass获取指定插件类等方法。
Spoon中step列表
左侧显示由Spoon.refreshCoreObjects()函数实现,如果选择时trans相关的内容,将显示所有的step插件。流程图如下所示:
spoon界面step插件显示流程
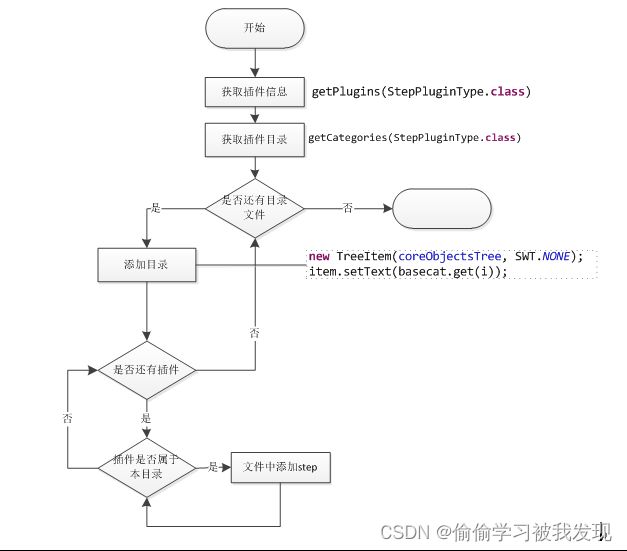
- 插件调用
Kettle中调用插件时,平台通过元素管理引擎获取对应的插件信息,通过反射生成插件对象,调用对应的函数。Kettle以外观模式的方式调用插件,我们以双击某个插件图表,弹出对应配置界面为例进行说明。
Spoon界面交互相关的处理器都封装到SpoonDelegates中,根据不同的事件类型调用对应的事件处理函数。UML类图如下所示。
事件代理类
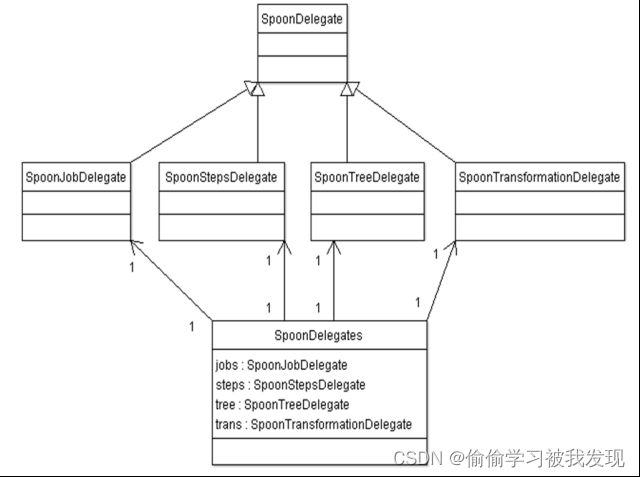
SpoonStepsDelegate提供了与UI交互相关的处理事件,如复制、删除、粘贴、编辑等。双击某个step时会调用编辑功能,编辑功能是对插件StepDialogInterface的封装。时序图如下:
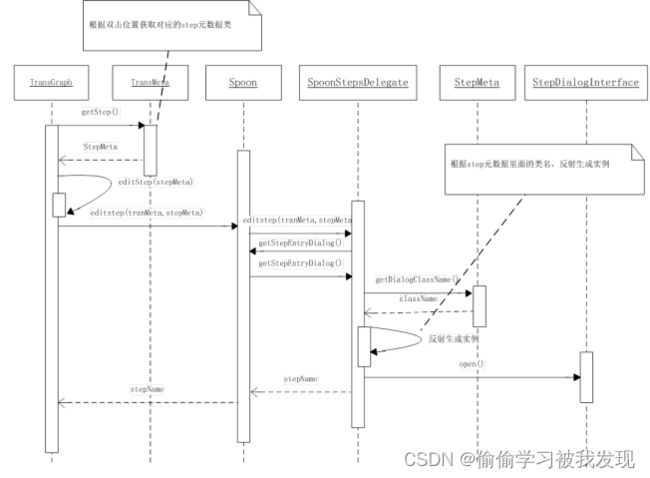
双击是TransGraph对象注册的时间,双击是根据页面上的坐标信息获取双击的stepmeta对象(来自于*.ktr)。然后,将这个对象传给事件代理类处理,根据stepmeta对象,获取对应的插件类名,通过反射生成StepDialogInterface的实例并调用open()方法。 - 插件间通信
Kettle插件之间天生就具有通信共享数据的特点,kettle中最主要通信方式是通过插件之间共同关联一个数据类对象的方式进行通信;使用单例模式实现插件间信息共享。
核心包(模块)、类和接口
kettle包含的核心包(模块)、类和接口,分为辅助层(底层)、逻辑层和界面层。其对应的源码包结构是core,src, ui的顺序,如下列表所示。
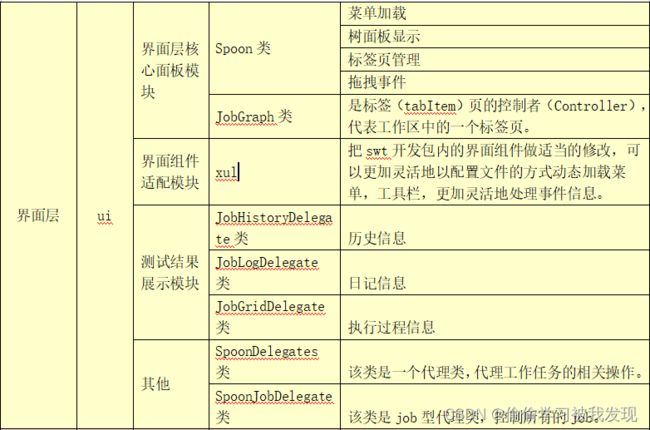

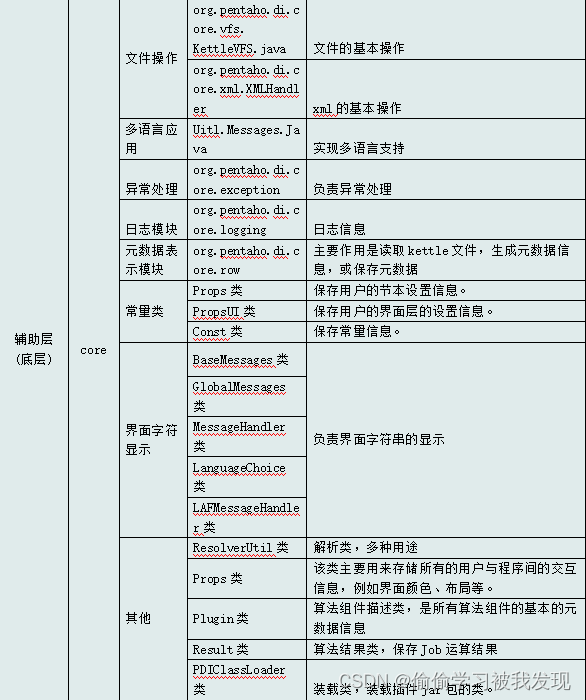
- 界面层
- 核心面板模块
- Spoon类
Spoon类是图形界面的入口类,它处于整个程序运行的核心地位,连接界面和逻辑功能,从界面获取配置。
Spoon类作用主要是主界面的Handle,实现界面的显示、刷新、菜单加载、菜单及界面按钮功能的实现、工作流信息的收集等。即与界面相关的、与delegates相关的、与props相关的。
Spoon的一些重要的成员函数如下表:
Spoon的一些成员变量

Spoon的一些重要函数:


- 菜单加载
Spoon中加载菜单是在界面初始化的时候完成的,Spoon.init()函数完成界面的初始化,然后调用addMenu()添加菜单。
菜单加载原理:Kettle通过读取配置文件的方式加载主菜单。当Kettle建立Shell对象时,需要为Shell对象增加菜单。这个任务有XulHelper完成。详细过程见6.9
XulHelper.createMenuBar(XUL_FILE_MENUBAR, shell,new XulMessages());
XulHelper解析配置文件,根据配置文件,生成相应的menubar,menu,menuitem或menuseparator。每一项都可能有自己的id,快捷键和label,并且id和快捷键在handler中注册(但是没有说明每一个菜单项调用哪个方法)。
加载完之后,需要对每一个id和快捷键加上事件的触发的函数。该过程通过读取ui/menubar.properties文件获得一个id对应的事件函数体名称,Handler在把id和对应的函数体关联起来,这样每次事件触发都有hanhler统一根据id调用相应的函数。 - 树面板显示
Kettle主界面中的树面板是通过addTree()函数添加的。
Spoon类中的mainComposite变量就代表树面板,view、design 、expandAll、collapseAll、selectionFilter和coreObjectsTree分别表示主对象树、核心对象、编辑框、展开按钮、收起按钮和树列表。如下图
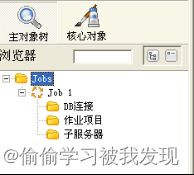
- 标签页管理
标签页实际上就是一个TabItem类,标签页的管理涉及到两个类对象: Spoon中的delegates.tabs和Spoon中的delegates.jobs和delegates.trans,它们都管理着所有的正在编辑的页面,但是各有各的职责。
tabs的职责的是维护标签页列表List tabMap (TabMapEntry中有变量TabItem tabItem),包括列表元素的增删查找等,以及实现标签选择、不选择和关闭等事件。
delegates.jobs和delegates.trans类似,主要的职责是记录job标签页的信息,delegates.jobs根据标签页维护这一个jobMeta列表 Map
原理:(以增加一个job为例)
当触发一个增加job的事件时,Spoon会将首先事件委托给SpoonJobDelegate处理。
SpoonJobDelegate会把增加标签页面的工作交给SpoonTabsDelegate处理。
同理,当关闭一个标签页时,Spoon会首先事件委托给SpoonJobDelegate处理。
SpoonJobDelegate会把去除标签页面的工作交给SpoonTabsDelegate处理。 - 拖拽事件
这里拖拽事件是指将树面板中的组件拖拽到标签页中。
原理:SpoonTreeDelegate监听树的事件信息,当有拖拽离开事件发生时,SpoonTreeDelegate会把算法在核心对象树的文本展示保存到全局变量,当在编辑面板有拖拽放下事件发生时会根据得到的全局变量在算法列表里索引相应的算法,实例化一个相应的算法类和算法界面类。
SpoonTreeDelegate的dragSetData()内有拖拽离开事件发生后的代码。
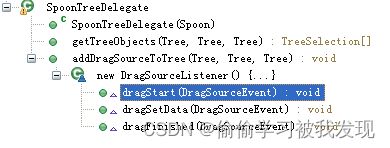
data = treeObject.getItemText();
event.data = new DragAndDropContainer(type, data);
最后将事件和携带的组件信息传递到JobGraph类中的drop函数中,这个函数是处理拖拽放下事件的。该函数的其中三个语句如下:
DragAndDropContainer container = (DragAndDropContainer) event.data;
String entry = container.getData();
container.getType()
…
JobEntryCopy jge = spoon.newJobEntry(jobMeta, entry, false);
可见,首先根据传入的事件数据event.data构建DragAndDropContainer对象,然后从中获取组件类型描述信息(entry)、组件类型(container.getType)。最后根据类型描述构建JobEntryCopy对象。
这样便实现了拖拽添加组件。
- 菜单加载
- Spoon类
- 核心面板模块
- JobGraph类
是标签(tabItem)页的控制者(Controller),代表工作区中的一个标签页。负责标签页上的各种触发事件的传递或处理,比如说:将组件拖拽到工作区事件、编辑entry事件、删除entry或者hop事件、移动组件位置等等;还有获取当前工作区中的工作流界面信息;还有响应标签页的菜单选择事件,菜单如下图:

JobGraph类重要成员如下:
//相应的jobMeta对象,每一个标签页就是一个工作流,也就是一个jobMeta
protected JobMeta jobMeta
// Job类对象,它是一个线程对象,负责当前jobMeta的执行
private Job job
private Repository rep;
private Job parentJob;
private JobTracker jobTracker;用于跟踪日志记录
private Date startDate, endDate, currentDate, logDate, depDate;
private boolean active, stopped;状态位
private List sourceRows; 返回结果的数据内容
private Result result;每次执行完一个jobentry返回结果- 一些重要的函数:
public JobGraph(Composite par, final Spoon spoon, final JobMeta jobMeta)
这是它的构造函数。该函数不仅构造了JobGraph的对象,而且在这里同时设置了很多的监听器,比如监听鼠标的按下、移动、放开事件、选择事件等。 - 双击事件
canvas.addMouseListener(new MouseAdapter()
双击事件主要是指双击工作区的entry,进入entry的编辑对话框。当然也可能是双击工作区的其他地方。 - 拖拽事件
ddTarget.addDropListener(new DropTargetListener()
拖拽事件的一个主要功能是选择需要添加的entry,加入到job中来,即创建新的entry并加入到jobMeta中。当然也可能是拖动已有的entry改变其位置。 - 显示标签页上的新建菜单的下拉菜单
public void newFileDropDown()
- 标签页上的打开菜单
public void openFile() - 标签页的保存菜单
public void saveFile() - 运行工作流
public void runJob() { - Start()函数
函数主要是开启job的线程,执行当前工作流。主要代码如下:
job = new Job(log, jobMeta.getName(), jobMeta.getFilename(), null);
……
job.start();
- 一些重要的函数:
- 组件适配模块
该模块的主要作用是把swt开发包内的界面组件做适当的修改,可以更加灵活地以配置文件的方式动态加载菜单,工具栏,更加灵活地处理事件信息。
其包结构如下:
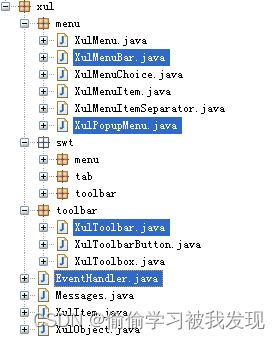
使用的原理:每一个XulMenuBar或XulToolBar都有自己的一个EventHandler成员,所有的MenuItem和XulToolBarButton都有唯一的id,这些内容可以通过配置文件读取。所有的MenuItem和XulToolBarButton会把自己的id和处理函数在EventHandler中注册,EventHandler维护一个列表,表示不同事件的id和对应的处理函数,快捷键,处理对象。如下图

当触发相应的Item或Button时,它们同一把id作为参数,调用handler的处理函数,handler根据索引得到相应的函数名,对象实例,通过反射调用,对象实例的函数方法。完成触发动作。 - 测试结果展示模块
结果的展示就是将执行结果展示到界面上。要展示的内容包括三个方面的信息:历史信息、日记信息和执行过程信息。执行完任务后调用JobGraph.addAllTabs()添加三个标签来分别显示这三个方面的内容。
JobHistoryDelegate类,表示历史信息。
JobLogDelegate类,表示日记信息。
JobGridDelegate类,表示执行过程信息。
当job运行时会设置 jobGridDelegate.jobTracker = job.getJobTracker();
当每次job运行结束之后会将结果保存到jobTracker对象内。JobGridDelegate会循环读取这个运行结果内容,并且把运行结果展示在界面上。 - ui其他重要的类
- SpoonDelegates类
该类是一个代理类,代理工作任务的相关操作。它的部分成员变量如下:
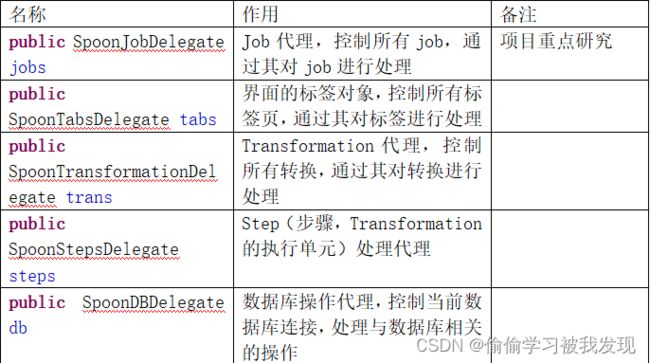
该类只有一个成员函数,用来初始化生成所有成员变量:
public SpoonDelegates(Spoon spoon)
- SpoonDelegates类
- SpoonJobDelegate类
该类是job型代理类,控制所有的job。其成员变量如下:
private Map
以及从父类SpoonDelegate继承的protected Spoon spoon
jobMap是所有job的映射列表,存储了所有的job,JobMeta代表一个job,下面会有相关介绍。
该类的函数主要是对jobMap进行增删修改复制jobMeta等操作,比如
添加一个job
public String addJob(JobMeta jobMeta)
复制jobMeta对象
public void copyJobEntries(JobMeta jobMeta, JobEntryCopy jec[])
根据tab名称(标签页名)获取job
public JobMeta getJob(String tabItemText)
执行所给的jobMeta
public void executeJob(JobMeta jobMeta, boolean local, boolean remote, Date replayDate, boolean safe) throws KettleException - ui中类的关系图
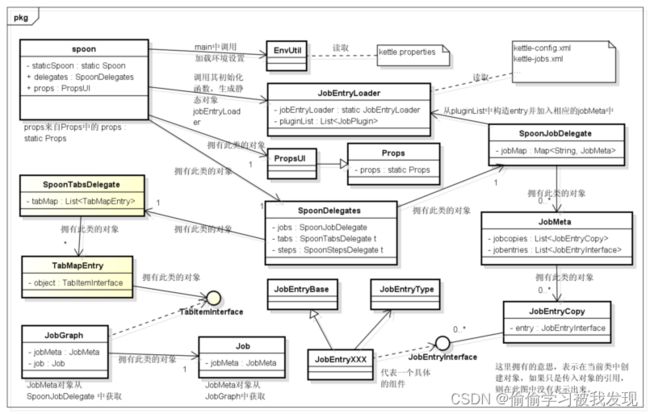
- 逻辑层
- Job模块
主要介绍src.org.pentaho.di.job包下的一些主要的类。这些类主要作用是实现job(作业)的逻辑功能,包括创建job、维护job及执行job等,后续有详细介绍。 - Trans模块
这个模块和job模块类似,主要是处理transformation任务,后续有详细介绍。 - Src中其他重要的类和接口
- EnvUtil类
EnvUtil类中的所有成员都是静态的,最主要的两个函数是:
public static Properties readProperties(String fileName)
public static void environmentInit()
第一个函数是读取kettle运行时主目录下的kettle.properties文件,文件是关于kettle应用程序的一些设置
第二个函数首先调用第一个读取文件后,加载文件中的所有设置,并加入一些临时的设置。
这个类负责kettle的环境设置。
- EnvUtil类
- PropsUI类
该类继承了Props类,Props类用来储存各种用户设置信息,并且有一个自身静态对象protected static Props props。PropsUI中还可储存最近用户文件。
下面介绍该类的一些重要函数
public static final void init(Display d, String filename)
该函数在Spoon的main中执行,最后创建了props静态对象。props是PropsUI的父类(Props)对象。
PropsUI的其他函数一般是用于加载和获取设置信息。 - PluginLoader类
该类通过load()接口函数对外提供加载插件jar包功能。有成员变量locs表示插件所在的目录地址。
- Job模块
- 底层(辅助层)
- 对文件的操作
以下各类封装了对文件的基本操作,几乎所有的模块都利用到以下的类。是最底层的类。
org.pentaho.di.core.vfs. KettleVFS.java
实现了对文件的基本操作,基本是静态方法,通过使用开源jar包org.apache.commons.vfs可以对不同操作系统的文件系统处理。
org.pentaho.di.core.xml.XMLHandler
实现了对xml的基本操作,基本是静态方法,得到对应标签的值,或者获取变量对应的xml字符串。 - 多语言应用
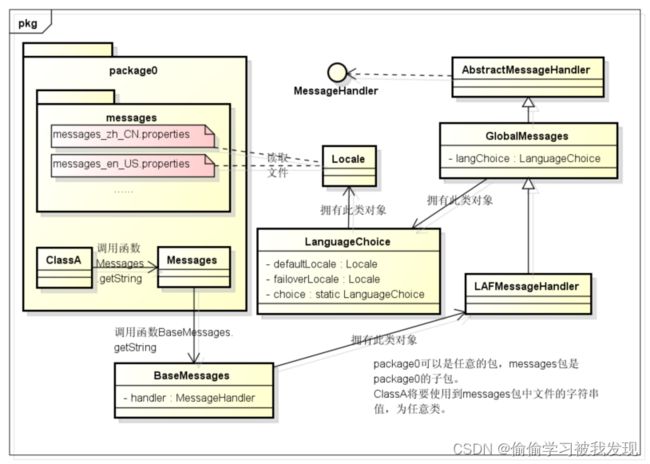
实现原理:在子包X中,如果子包x中所有的类需要多国语言支持,那么必须需要在子包x中增加一个Messages类和相应的不用语言的文件支持。
如下图
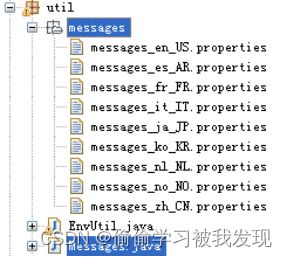
语言设置可以是默认语言,也可以用户指定,当用户指定时,Kettle把设置信息保存到用户目录下,这样下次启动时读取信息,设置依然生效。
Kettle中多语言是通过Messages类来实现的。在需要实现多语言的类包下编写相应的Messages类。而在Messages通过getString(“需要国际化的字符串”)方法调用基类BaseMessages获取给定别名的字符串值,BaseMessages交给GlobalMessages处理,GlobalMessages会根据语言设置,查找相应的文件(比如:messages_zh_CN.properties文件)得到相应的语言信息。
例如GlobalMessages的方法。如下
- 对文件的操作
public String getString(String packageName, String key)
{
Object[] parameters = new Object[] {};
return calculateString(packageName, key, parameters);
}
protected String calculateString(String packageName, String key, Object[] parameters)
{
String string=null;
try { string = findString(packageName, langChoice.getDefaultLocale(), key, parameters); } catch(MissingResourceException e) {};
if (string!=null) return string;
//首先从本包内搜寻相应的语言文件
try { string = findString(SYSTEM_BUNDLE_PACKAGE, langChoice.getDefaultLocale(), key, parameters); } catch(MissingResourceException e) {};
if (string!=null) return string;
//如果没有,就从i18n包内搜寻相应的语言
//搜索不到,那么就尝试用默认的第二语言
。。。。。。
return string;
}
上述类的关系如下图:
-
异常处理
在org.pentaho.di.core.exception内

-
日志模块
核心代码在src-core内org.pentaho.di.core.logging。

核心类是LogWriter.java。在应用中依赖于语言支持包,和文件操作类,其输出方式问文件和控制台端口两种方式,默认是控制台,也可以同时输出到文件中,只要调用不同的构造函数即可。
例如在LogWriter()中,有pentahoLogger.addAppender(consoleAppender);表示日志输出到控制台。
在LogWriter(String filename, boolean exact, int level)
{
this();调用LogWriter()构造函数
this.level = level;
fileAppender = createFileAppender(filename, exact);
addAppender(fileAppender);除了控制台的输出也增加了文件输出。
…
在日志记录中用以下函数记录不同的日志级别。
- 元数据表示模块
元数据表示模块是Kettle的Transformation部分的元数据表示类,用于Transformation的任务中,由于修改后的源码没有采用Kettle的元数据,而是采用了PDM的元数据,这里对Kettle的元数据只做大概介绍。
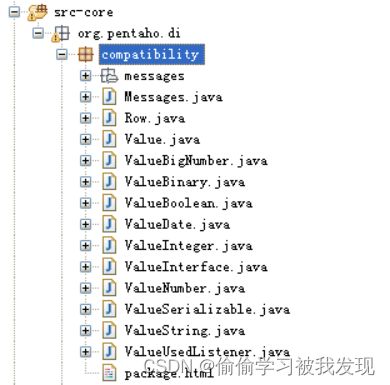
这是Kettle的基本的数据类型。
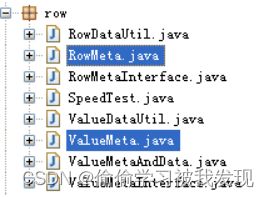
这是Kettle用于元数据处理的类,核心类是RowMeta’和ValueMeta,主要作用是读取kettle文件,生成元数据信息,或保存元数据,包含在org.pentaho.di.core.row子包内。 - core中的其他重要的类
- 工具类:ResolverUtil,解析类,多种用途,例如读取配置文件,加载他们的信息,搜寻有@标记的类,判断一个类和另一个类的关系(不是对象的关系)。
- Props类,该类主要用来存储所有的用户与程序间的交互信息,例如界面颜色、布局等。
- 算法组件描述类:Plugin,是所有算法组件的基本的元数据信息,子类是JobPlugin和StepPlugin类。
- 算法结果类:Result:保存Job运算结果:详细如下:
private boolean result;执行是否出现异常
private int exitStatus; 执行结果状态
private List rows;一个jobEntry完成处理后的数据(若存在)
private Map - 常量类:Props:保存用户的节本设置信息,PropsUI,保存用户的界面层的设置信息。Const。保存常量信息。
PDIClassLoader:装载类,装载插件jar包的类。 - 界面字符显示:BaseMessages、GlobalMessages、MessageHandler、LanguageChoice和LAFMessageHandler这几个类负责界面字符串的显示。
目录结构
- 总体目录结构

Kettle源代码主要由9个source folder组成,其中core、engine、ui和test实现了主要功能。 - core包
core包中是kettle的核心类。

- compatibility
compatibility是系统用到的数值类型及对应接口。 - core
core包是整个应用程序处理的基础。
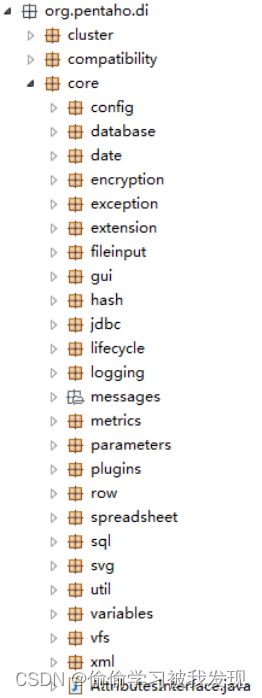
core.config:应用程序的核心配置类
core.exception包,异常处理类。
org.pentaho.di.core.xml包,XML相关接口及封装类。
org.pentaho.di.core.logging包,日志。
org.pentaho.di.core.plugins包,组件加载类。
org.pentaho.di.core.row包,行的数据、元信息、操作。
org.pentaho.di.core.gui包,界面接口类和一些基础图形类。
org.pentaho.di.core.database下包含各数据库对应的类以及对应的元数据类,还包括不同类型数据库必须继承的基类和必须实现的接口。
- compatibility
- engine包
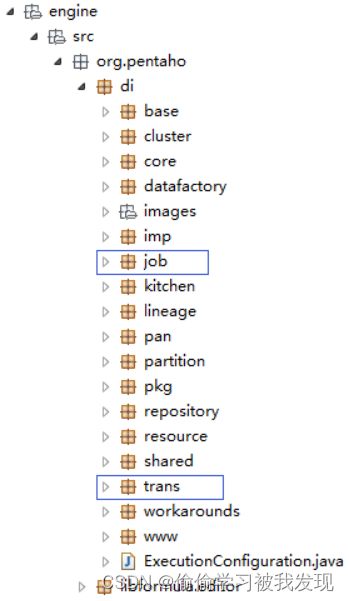
包含调度逻辑和具体的执行代码。最重要的两个包为engine.src.org.pentaho.di.job和engine.src.org.pentaho.di.trans。
Job中包含各个功能组件(entry)的逻辑实现,每一个entry具有特定的不同功能,实现不同的数据处理和应用。例如:文件输入组件(fileinput entry),实现从外部数据源导入数据文件到程序。
Trans类似job,每个特定的步骤(step)实现整个转换(transformation)中的特定步骤。- job包

Job的每个执行单元称为entry。
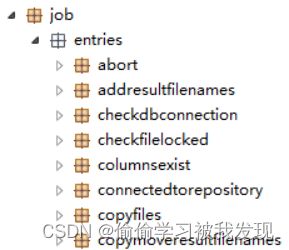
engine.src.org.pentaho.di.job.entry包中存放了每个entry必须继承的基类以及必须实现的接口。

engine.src.org.pentaho.di.job.entries包中存放了不同entry的具体实现。
- trans包
Transfromation中的每个执行步骤称为step。
engine.src.org.pentaho.di.trans.step包中存放了每个step必须继承的基类以及必须实现的接口。
engine.src.org.pentaho.di.trans.steps包中存放了不同step的具体实现。

- kitchen包
Job的命令行执行器类。
- pan包
Transformation的命令行执行器类。

- logging包
日志模块。

- job包
- ui包
这是关于界面部分的,最主要的就是其下的org.pentaho.di.ui包。

ui子包结构如上图所示,其中最重要的3个子包为:org.pentaho.di.ui.job,org.pentaho.di.ui.trans和org.pentaho.di.ui.spoon。
Job包中是各个entry参数配置对话框的实现,一般为一个弹出对话框。
Trans包和job包类似,为step的参数配置对话框的实现。
Spoon是整个kettle程序的主界面相关类所在的包,主要功能是初始化主界面、相关工作参数配置以及实现界面响应事件。
几个比较重要的类是:
org.pentaho.di.ui.spoon包中的Spoon类,对应整个程序的入口;
org.pentaho.di.ui.spoon.job包中的JobGraph类,编辑区的Job类型的标签页,负责标签页的菜单、组件等的显示和事件响应;
org.pentaho.di.ui.spoon.delegates包,此包中的类是负责作业或转换的装载、运行的控制。
整个包的功能比较多,也比较复杂,下面会有更详细的说明。- job包
每个entry的参数设置面板类、进程对话类及需要继承的基类。
- trans包
每个step的参数设置面板类、进程对话类及需要继承的基类。
- spoon包
整个软件的入口对应ui.src.org.pentaho.di.ui.spoon包中的Spoon类。

- job包
- test包
测试代码。
主要源码分析
- 用户界面工作过程
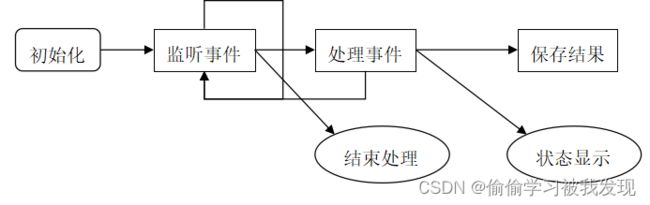
- 初始化过程
图形界面的应用程序的初始化包括程序环境的初始化、组件加载、用户历史信息初始化以及界面初始化。
环境初始化的内容主要包括:加载kettle.properties文件,获取和设置一些系统变量和路径值。
组件加载的内容主要包括:读取kettle-config.xml(指明下面的三个文件的路径、处理文件如kettle-job.xml所用的类、处理规则文件、处理起点)、kettle-job.xml(所有可用的entry组件均在此注册)、kettle-step.xml(所有可用的step组件均在此注册)、kettle-plugin.xml等文件,将文件中注册的组件加载到程序中,存放在对应的列表中(如entry要存放在jobEntryLoader.pluginList中,其中jobEntryLoader是JobEntryLoader类对象)。
用户历史信息加载内容主要包括:最近打开的一些文件、上次关闭时kettle的状态(打开的标签页、编辑区域的内容等)、用户对应用程序的偏好设置(颜色、字体、布局等)。
界面初始化内容主要包括: - 界面的初始化
创建PropsUI对象props存储之前加载的用户历史信息、创建Spoon对象并赋值给staticSpoon表示整个应用程序界面、绘制窗口、添加菜单及各种面板等、注册热键、将内容(组件等)显示到相应位置。 - 设置监听器
用来监听界面的按键或者鼠标等事件。 - main函数
初始化在主函数开始时进行,spoon类的main如下:
public static void main(String[] a) throws KettleException {
try {
// Do some initialization of environment variables
//环境初始化
EnvUtil.environmentInit();
List args = new ArrayList(java.util.Arrays.asList(a));
Display display = new Display();
//这是程序的加载界面
Splash splash = new Splash(display);
CommandLineOption[] commandLineOptions = getCommandLineArgs(args);
initLogging(commandLineOptions);
//组件加载
initPlugins();
//用户配置信息加载
PropsUI.init(display, Props.TYPE_PROPERTIES_SPOON); // things to //
// remember...
staticSpoon = new Spoon(display);
//主界面初始化
staticSpoon.init(null);
SpoonFactory.setSpoonInstance(staticSpoon);
staticSpoon.setDestroy(true);
//打开界面并显示
GUIFactory.setThreadDialogs(new ThreadGuiResources());
…
// listeners
//设置监听器
try {
staticSpoon.lcsup.onStart(staticSpoon);
} catch (LifecycleException e) {
……
}
staticSpoon.setArguments(args.toArray(new String[args.size()]));
//程序初始化完毕,进入响应-处理阶段,程序进行正常工作
staticSpoon.start(splash, commandLineOptions);
} catch (Throwable t) {
……
}
// Kill all remaining things in this VM!
System.exit(0);
}
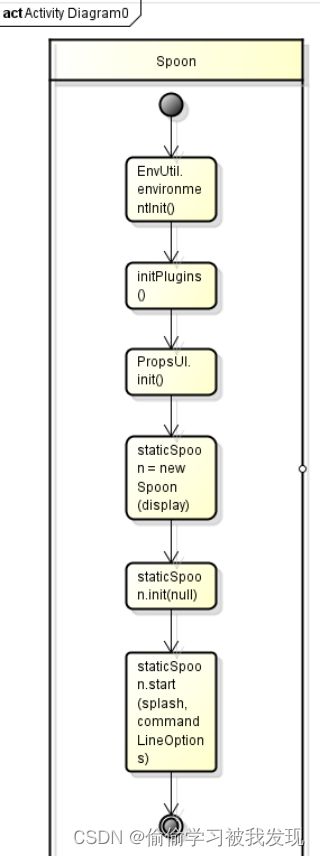
- 环境初始化
调用类:org.pentaho.di.ui.spoon包中的Spoon类
调用位置:public static void main(String[] a) throws KettleException {
…
//初始化Kettle运行环境
EnvUtil.environmentInit();
…}
初始化流程:首先主函数Spoon调用EnvUtil的静态函数environmentInit()。在environmentInit()中使用下面语句来读取加载运行环境。
//下面的语句是从kettle的主目录中读取配置文件kettle.properties
Map kettleProperties = EnvUtil.readProperties(Const.KETTLE_PROPERTIES);
System.getProperties().putAll(kettleProperties);
接着同时还要设定(使用语句System.getProperties().put(key,value))一些临时的环境变量(Also put some default values for obscure environment variables in there)。运行环境初始化结束,返回主函数Spoon。
对应engine.src.org.pentaho.di.core包中KettleEnvironment类负责初始化Kettle运行环境,主要包括调用cort.src.org.pentaho.di.core.plugins.PluginRegistry类的init()方法加载组件。
public static void init(boolean simpleJndi) throws KettleException {
//若未曾初始化
if (initialized==null) {
//若不存在则创建一个home文件夹
createKettleHome();
//加载home中kettle.properties文件的内容
EnvUtil.environmentInit();
//Log初始设置:容量大小、超时时长
CentralLogStore.init();
…
//加载Kettle需要用到的变量值,从Kettle-variables.xml文件
KettleVariablesList.init();
initialized = true;
}
}
- 组件初始化:
因为job和transformation类似,这里只拿job的entry来做说明组件加载过程。
在main函数中调用函数initPlugins(),初始化JobEntryLoader,最后返回主函数。
整个过程如下:
Spoon.main -> Spoon.initPlugins()-> JobEntryLoader.init()
下面是init()函数体
public static final void init() throws KettleException
{
JobEntryLoader loader = getInstance();
loader.readNatives();
loader.readPlugins();
loader.initialized = true;
}
getInstance()用来获取一个JobEntryLoader对象,进入函数体
public static final JobEntryLoader getInstance()
{
if (jobEntryLoader != null)
return jobEntryLoader;
jobEntryLoader = new JobEntryLoader();
return jobEntryLoader;
}
其中jobEntryLoader是JobEntryLoader的自身静态对象(private static JobEntryLoader jobEntryLoader = null;)可见getInstance()函数创建并返回了JobEntryLoader类的自身静态对象,此对象创建后便唯一存在。
loader.readNatives()读取并解析kettle-config.xml、kettle-job.xmlb等相关xml文件,最终将所有entry都加入到列表jobEntryLoader. pluginList中,实现了组件的加载。
public boolean readNatives()
{
try
{
// annotated classes first
ConfigManager jobsAnntCfg = KettleConfig.getInstance().getManager("jobs-annotation-config");
//读取文件kettle-config.xml文件中关于
//job-xml-config的部分,即标签
Collection jobs = jobsAnntCfg.loadAs(JobPluginMeta.class);
ConfigManager jobsCfg = KettleConfig.getInstance().getManager("jobs-xml-config");
Collection cjobs = jobsCfg.loadAs(JobPluginMeta.class);
jobs.addAll(cjobs);
//加入到pluginList ,类型为JobPlugin.TYPE_NATIVE
for (JobPluginMeta job : jobs)
if (job.getType() != JobEntryType.NONE)
pluginList.add(new JobPlugin(JobPlugin.TYPE_NATIVE, job.getId(), job.getType(), job.getTooltipDesc(), null, null, job.getImageFileName(), job.getClassName().getName(), job.getCategory()));
} catch (KettleConfigException e)
{…
}
return true;
}
loader.readPlugins()读取并解析kettle-config.xml、和kettle-plugin.xml等相关xml文件,最终将一些特别的组件(如dummy组件,这些组件以jar包的形式存放在plugin/jobentries目录下)加载到jo```bEntryLoader.pluginList中,类型为JobPlugin.TYPE_PLUGIN 。
- 用户历史信息初始化
- 用户历史信息包括:最近打开的一些文件、最近一次打开的kjb、用户对应用程序的偏好设置(颜色、字体、布局等)
在main函数中调用语句PropsUI.init(display, Props.TYPE_PROPERTIES_SPOON); 实现配置信息初始化,函数代码如下:
public static final void init(Display d, int t)
{
…
props = new PropsUI(t);
// Also init the colors and fonts to use...
GUIResource.getInstance();
…
}
public Spoon(Display d, Repository rep) {
…
props = PropsUI.getInstance();
…
}
public static final PropsUI getInstance()
{
if (props!=null) return (PropsUI) props;
…
}
PropsUI是Props的子类,props是Props的自身静态对象。
在PropsUI.init()函数中首先实例化props,这其实是加载了一些用户的历史信息,存放在props对象中。然后使用GUIResource.getInstance()来初始化应用程序的颜色、字体、风格等。
初始化spoon时(main函数中语句staticSpoon = new Spoon(display);)在Spoon(display)函数中语句props = PropsUI.getInstance();
- 界面初始化
staticSpoon = new Spoon(display);
staticSpoon.init(null);
SpoonFactory.setSpoonInstance(staticSpoon);
staticSpoon.setDestroy(true);
GUIFactory.setThreadDialogs(new ThreadGuiResources());
…
// listeners
try {
staticSpoon.lcsup.onStart(staticSpoon);
} catch (LifecycleException e) {
…
}
staticSpoon.start(splash, commandLineOptions);
…
第1-5行是界面的初始化,后面的第8行则是设置监听器,用来监听界面的按键或者鼠标等事件。而第10行是进入事件监听-处理的循环中,直到程序关闭。
staticSpoon = new Spoon(display)获取Spoon对象以及程序初始化所需要的配置信息
public Spoon(Display d, Repository rep) {
this.log = LogWriter.getInstance();
…
//获取系统配置信息和包括用户配置信息
props = PropsUI.getInstance();
shell = new Shell(display);
shell.setText(APPL_TITLE);
staticSpoon = this;
JndiUtil.initJNDI();
SpoonFactory.setSpoonInstance(this);
}
staticSpoon.init(null)函数用来初始化界面
public void init(TransMeta ti) {
//界面布局
FormLayout layout = new FormLayout();
layout.marginWidth = 0;
layout.marginHeight = 0;
shell.setLayout(layout);
…
// Load settings in the props设置配置信息
loadSettings();
…
…//其他设置,主要是热键的设置
initFileMenu();
//主界面
sashform = new SashForm(shell, SWT.HORIZONTAL);
…//主界面的设置
//加入菜单
addMenu();
//加入左边的树面板
addTree();
//加入标签,即上次未关闭的job
addTabs();
…
}
- 主界面标题
找到spoon.java下面的
public static final String APP_NAME = BaseMessages.getString(PKG, "Spoon.Application.Name");
- 初始化Spoon界面
读取ui*.xul文件进行部署。
对应Spoon类的init()方法:
public void init(TransMeta ti) {
//对界面布局进行设置
shell.setLayout(layout);
//加入ktr、kjb文件读写监听器
addFileListener(new TransFileListener());
addFileListener(new JobFileListener());
…
//加载初始化一些变量
…
try {
//SwtXulLoader类没有提供src
xulLoader = new SwtXulLoader();
…
} catch (…) {
…
}
//加载部分固定组件及对应监听器
…
}
- 初始化过程时序图

- Job、Transformation界面调用
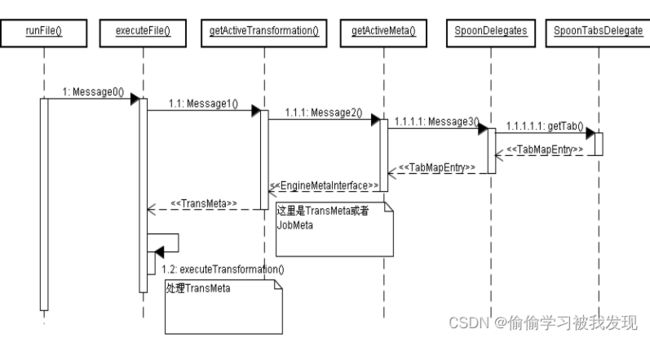
通过用户界面操作(点击运行按钮)触发监听器,调用Spoon的runFile()方法。 - Spoon类runFile( )
public void runFile() {
executeFile(true, false, false, false, false, null, false);
}
- Spoon类executeFile( )
在这一层决定执行Job还是Transformation。
public void executeFile(boolean local, boolean remote, boolean cluster, boolean preview, boolean debug,Date replayDate, boolean safe) {
//获取当前活跃的Transformation元信息
TransMeta transMeta = getActiveTransformation();
if (transMeta != null)
executeTransformation(transMeta, local, remote, cluster, preview, debug, replayDate, safe);
//获取当前活跃的Job元信息
JobMeta jobMeta = getActiveJob();
if (jobMeta != null)
executeJob(jobMeta, local, remote, replayDate, safe);
}
- Spoon类getActiveTransformation( )、getActiveJob( )
public TransMeta getActiveTransformation() {
EngineMetaInterface meta = getActiveMeta();
if (meta instanceof TransMeta) {
return (TransMeta) meta;
}
return null;
}
getActiveJob()类的实现同getActiveTransformation()。
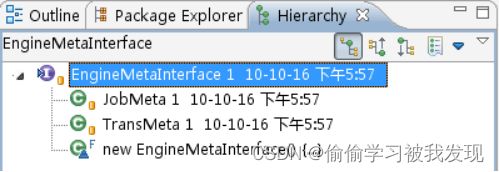
如上图,JobMeta和TransMeta都实现了EngineMetaInterface。
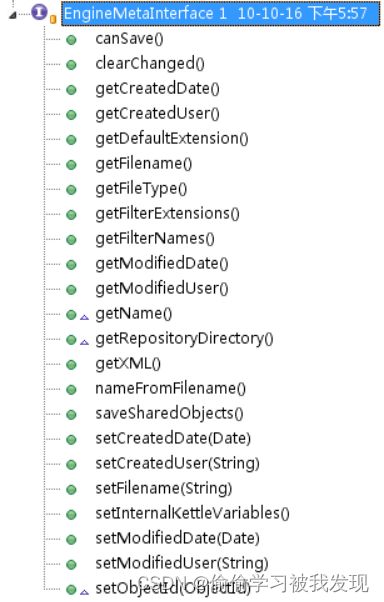
上图可见,EngineMetaInterface包含Job、Transformation的整体操作。
- Spoon类getActiveMeta( )
public EngineMetaInterface getActiveMeta() {
if (tabfolder == null)
return null;
TabItem tabItem = tabfolder.getSelected();
if (tabItem == null)
return null;
//通过当前活跃的Tab标签确定返回类型。
TabMapEntry mapEntry = delegates.tabs.getTab(tabfolder.getSelected());
EngineMetaInterface meta = null;
if (mapEntry != null) {
if (mapEntry.getObject() instanceof TransGraph)
meta = (mapEntry.getObject()).getMeta();
if (mapEntry.getObject() instanceof JobGraph)
meta = (mapEntry.getObject()).getMeta();
}
return meta;
}
下图红色方框内为活跃的Tab。

- Spoon类Splash
初始化显示的界面:
Splash splash = new Splash(display); - 选择执行时序图
下图总结了系统如何判定执行Job还是Transformation。
- Job调用后续步骤
最终转交给JobGraph负责执行。 - Transformation调用后续步骤
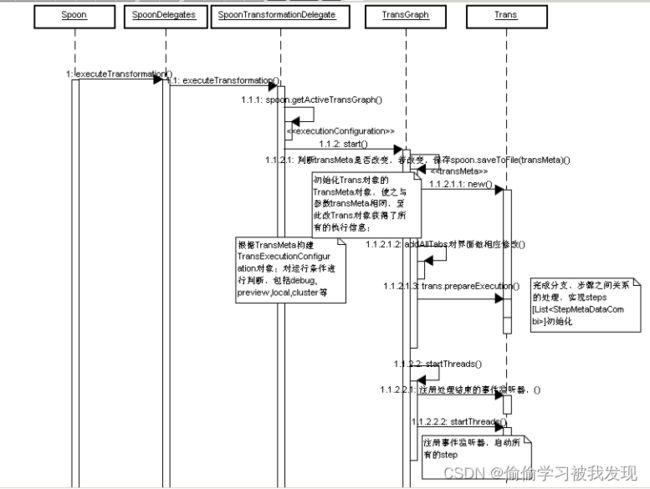
最终转交给TransGraph负责执行。 - Spoon类executeTransformation( )
public void executeTransformation(…) {
new Thread() {
…
//利用trans执行代理执行trans
delegates.trans.executeTransformation(transMeta, local, remote, cluster, preview, debug,
replayDate, safe);
…
}.start();
}
- SpoonTransformationDelegate类executeTransformation( )
public void executeTransformation(…){
…
//获取当前活跃的trans
TransGraph activeTransGraph = spoon.getActiveTransGraph();
…
//将配置设置入executionConfiguration后调用TransGraph实例执行
activeTransGraph.start(executionConfiguration);
…
}
- Job
主要介绍src.org.pentaho.di.job包下的一些主要的类。这些类主要作用是实现job(作业)的逻辑功能,包括创建job、维护job及执行job等。- 创建job
Job有创建有两种方式,一种是从kjb文件中加载到程序;另一种是用户手动通过菜单创建。两种过程都差不多,只是手动创建的初始时是一个空的没有组件的job。
创建job实质上就是创建一个jobMeta对象。
所有的job是由SpoonDelegates类来控制的, SpoonDelegates中有job和step两种类型的工作流。SpoonJobDelegate 是SpoonDelegatesd的子类,表示job类型的工作流控者。SpoonJobDelegate 中Map - 打开job(打开kjb)
打开job就是打开kjb文件,首先是由jobMeta调用loadXML加载作业的一些公共信息,然后调用具体组件的loadXML函数加载它们自己的组件信息,最后jobMeta加载hop信息;
有两种情况:
1、初始化时打开上次程序关闭前没有关闭的标签页(一个标签页代表一个job);
2、通过菜单项打开
两种情况下创建jobMeta的过程都是通过调用Spoon.openFile()来实现,不同的是初始化时加载需要使用handleStartOptions ()和loadLastUsedFile()获取上次关闭的信息。
handleStartOptions(options)中的相关代码如下:
- 创建job
List lastUsedFiles = props.getOpenTabFiles();
for (LastUsedFile lastUsedFile : lastUsedFiles) {
RepositoryMeta repInfo = (rep == null) ? null : rep.getRepositoryInfo();
loadLastUsedFile(lastUsedFile, repInfo, false);
}
首先是从props中获取上次关闭前打开的文件(已经在用户历史信息初始化阶段完成加载),然后逐个将工作流加载到当前应用程序。
private void loadLastUsedFile函数中调用openFile函数来打开job文件,调用语句如下:
if (lastUsedFile.isJob()) {
openFile(lastUsedFile.getFilename(), false);}
Spoon中的openFile函数
public void openFile(String fname, boolean importfile) {
…
loaded = listener.open(root, fname, importfile);
…
}
fname是文件(kjb)路径和名称。
JobFileListrener类中的open函数
public boolean open(Node jobNode, String fname, boolean importfile)
{
Spoon spoon = Spoon.getInstance();
try
{//生成jobMeta,此时里面没有entry
JobMeta jobMeta = new JobMeta(spoon.getLog());
//从kjb文件中加载entry到jobMeta中
jobMeta.loadXML(jobNode, spoon.getRepository(), spoon);
spoon.setJobMetaVariables(jobMeta);
//添加当前job为最近打开文件到菜单中
spoon.getProperties().addLastFile(LastUsedFile.FILE_TYPE_JOB, fname, null, false, null);
spoon.addMenuLast();
//如果job的名字改变,则刷新标签页上的名称
if (!importfile) jobMeta.clearChanged();
jobMeta.setFilename(fname);
//加入到spoon.delegates.jobs中为当前打开的一个job
spoon.delegates.jobs.addJobGraph(jobMeta);
spoon.refreshTree();
spoon.refreshHistory();
return true;
}
catch(KettleException e){
…
}
return false;
}
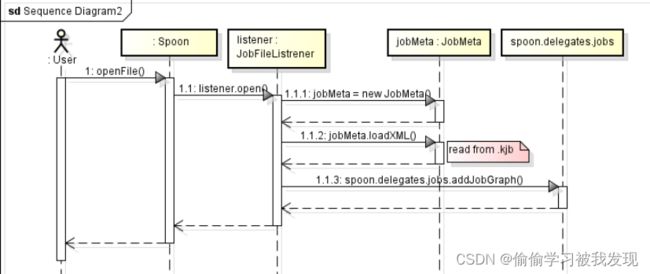
函数首先是创建一个jobMeta对象,然后通过所给的文件,构建entry并加入到jobMeta中,然后将整个jobMeta加入当前工作流集合spoon.delegates.jobs中。最后刷新主对象树面板。
jobMeta.loadXML(jobNode, spoon.getRepository(), spoon)函数从文件(由spoon.getRepository()提供)加载所有entry,并加入jobMeta。详细如何加载kjb文件请见“打开kjb”一节。
spoon.delegates.jobs.addJobGraph(jobMeta)函数的部分代码如下:
String key = addJob(jobMeta){… jobMap.put(key, jobMeta);…};
JobGraph jobGraph = new JobGraph(spoon.tabfolder.getSwtTabset(), spoon, jobMeta);
spoon.delegates.tabs.addTab(new TabMapEntry(tabItem, tabName, jobGraph,TabMapEntry.OBJECT_TYPE_JOB_GRAPH));
所以此函数不仅是将jobMeta加入到jobs( 列表变量jobMap中)中,还生成相应的JobGraph(标签页)。
打开kjb文件并创建job的过程如下图所示:
- 新建job
通过菜单或者鼠标新建job,实际上是调用函数Spoon.newJobFile()来实现的。
下面我们来看看这个函数
public void newJobFile() {
try {
//生成jobMeta对象
JobMeta jobMeta = new JobMeta(log);
…
//将jobMeta加入delegates.jobs中并创建标签页tab
delegates.jobs.addJobGraph(jobMeta);
…
refreshTree();
}
} catch (Exception e) {
…
}
}
和初始化创建那里的openFile()函数差不多,只是openFile()函数还有从xml文件加载组件这部分内容。newJobFile()这里只是新建一个JobMeta类的对象jobMeta,然后调用delegates.jobs.addJobGraph(jobMeta)将jobMeta对象加入到delegates.jobs的jobMap列表中,然后添加相应的标签页。
整个过程函数的调用关系如下:

- 保存job(保存kjb)
保存job就是保存kjb文件。
kjb等文件是kettle的工作文件,kettle将作业信息存放到kjb文件中。包括输入输出数据信息、当前所有组件配置,组件之间的连接关系等说明。
和打开kjb文件过程比较类似,保存kjb首先是由jobMeta调用getXML函数写入一些公共信息,当要写入具体的组件时,再调用特定的组件,由它们的getXML函数写入自己特定信息的内容,最后由jobMeta写入hop信息。
JobGraph.saveFile()响应鼠标单击保存按钮事件。
public void saveFile() {
spoon.saveFile();
}
Spoon.saveFile()完成保存kjb文件的功能。
public boolean saveFile() {
TransMeta transMeta = getActiveTransformation();
if (transMeta != null)
return saveToFile(transMeta);
//获取当前活动jobMeta
JobMeta jobMeta = getActiveJob();
if (jobMeta != null)
//保存到kjb文件
return saveToFile(jobMeta);
return false;
}
Spoon.saveToFile(EngineMetaInterface meta)函数
public boolean saveToFile(EngineMetaInterface meta) {
if (meta == null)
return false;
boolean saved = false;
…
if (rep != null) {
saved = saveToRepository(meta);
} else {
if (meta.getFilename() != null) {
//保存
saved = save(meta, meta.getFilename(), false);
} else {//另存为
saved = saveFileAs(meta);
}
}
…
return saved;
}
另存为和保存类似,下面拿保存作例子说明
saved = save(meta, meta.getFilename(), false)的调用函数如下:
public boolean save(EngineMetaInterface meta, String fname, boolean export) {
boolean saved = false;
FileListener listener = null;
// match by extension first
//获取扩展名
int idx = fname.lastIndexOf('.');
if (idx != -1) {
String extension = fname.substring(idx + 1);
listener = fileExtensionMap.get(extension);
}
if (listener == null) {
String xt = meta.getDefaultExtension();
listener = fileExtensionMap.get(xt);
}
//如果当前job名称被修改,则更改标签页上的名称
if (listener != null) {
String sync = BasePropertyHandler. getProperty(SYNC_TRANS);
if (Boolean.parseBoolean(sync)) {
listener.syncMetaName(meta, Const.createName(fname));
delegates.tabs.renameTabs();
}//保存到文件
saved = listener.save(meta, fname, export);
…
}
return saved;
}
上面的函数主要作用是获取文件的扩展名,并按照给定的job名称改变标签页的名称。最后保存到文件。
FileListener.save()函数代码如下:
public boolean save(EngineMetaInterface meta, String fname,boolean export) {
Spoon spoon = Spoon.getInstance();
EngineMetaInterface lmeta;
if (export)
{
lmeta = (JobMeta)((JobMeta)meta).realClone(false);
}
else
lmeta = meta;
//保存到文件
return spoon.saveMeta(lmeta, fname);
}
spoon.saveMeta(lmeta, fname)语句的调用函数如下:
public boolean saveMeta(EngineMetaInterface meta, String fname) {
//获取文件名
meta.setFilename(fname);
if (Const.isEmpty(meta.getName()) || delegates.jobs.isDefaultJobName(meta.getName())) {
meta.nameFromFilename();
}
boolean saved = false;
try {//构造XML文件内容
String xml = XMLHandler.getXMLHeader() + meta.getXML();
DataOutputStream dos = new DataOutputStream(KettleVFS.getOutputStream(fname, false));
//将内容写入文件
dos.write(xml.getBytes(Const.XML_ENCODING));
dos.close();
saved = true;
…
return saved;
}
先写入文件的头部(XMLHandler.getXMLHeader()),然后写入job(即标签)。
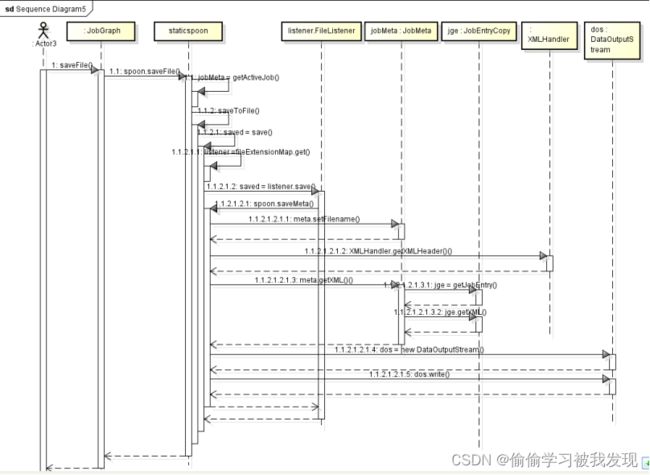
meta.getXML()调用JobMeta.getXML()函数,详细代码如下:
public String getXML() {
Props props = null;
if (Props.isInitialized())
props = Props.getInstance();
DatabaseMeta ci = getLogConnection();
StringBuffer retval = new StringBuffer(500);
//添加一些标签
retval.append("<").append(XML_TAG).append(">").append(Const.CR); //$NON-NLS-1$
retval.append(" ").append(XMLHandler.addTagValue("name", getName())); //$NON-NLS-1$ //$NON-NLS-2$
…//添加其他的很多标签
//添加所有属于该job的entry信息
retval.append(" ").append(Const.CR); //$NON-NLS-1$一一添加所有属于该job的entry信息
for (int i = 0; i < nrJobEntries(); i++) {
JobEntryCopy jge = getJobEntry(i);
//写入当前entry的信息
retval.append(jge.getXML());
}
retval.append(" ").append(Const.CR); //$NON-NLS-1$
//hop信息
retval.append(" ").append(Const.CR); //$NON-NLS-1$
for (JobHopMeta hi : jobhops) // Look at all the hops
{
retval.append(hi.getXML());
}
retval.append(" ").append(Const.CR); //$NON-NLS-1$
//其他标签
return retval.toString();
}
retval.append(jge.getXML())语句是具体类型的组件调用自己的getXML()函数写入自己的特定的信息,整个过程时序图如下:
- 执行job
程序中可能存在多个jobMeta,因此首先应该找到当前活动的jobMeta。然后用Job类来运行这个jobMeta(按照连接顺序,依次从jobMeta中取出entry,调用entry自己的execute函数执行,将执行结果存储到Result类中)。
JobGraph.runJob()响应鼠标单击运行按钮事件,然后调用Spoon.runFile()执行运行当前job。
public void runFile() {
executeFile(true, false, false, false, false, null, false);
}
public void executeFile(boolean local, boolean remote, boolean cluster, boolean preview, boolean debug, Date replayDate, boolean safe) {
…
//找到当前活动的jobMeta
JobMeta jobMeta = getActiveJob();
if (jobMeta != null)
//运行该jobMeta
executeJob(jobMeta, local, remote, replayDate, safe);
}
public void executeJob(JobMeta jobMeta, boolean local, boolean remote, Date replayDate, boolean safe) {
try {
delegates.jobs.executeJob(jobMeta, local, remote, replayDate, safe);
} catch (Exception e) {…}
}
delegates.jobs.executeJob调用函数如下:
public void executeJob(JobMeta jobMeta, boolean local, boolean remote, Date replayDate, boolean safe) throws KettleException {
…
JobExecutionConfiguration executionConfiguration = spoon.getJobExecutionConfiguration();
…
//运行参数配置对话框
JobExecutionConfigurationDialog dialog = new JobExecutionConfigurationDialog(spoon.getShell(), executionConfiguration, jobMeta);
if (dialog.open()) {
// addJobLog(jobMeta);
//获取当前活动标签(即当前jobMeta)
JobGraph jobGraph = spoon.getActiveJobGraph();
…
// Is this a local execution?
//运行当前job
if (executionConfiguration.isExecutingLocally()) {
jobGraph.startJob(executionConfiguration);
}
…
}
}
先弹出运行参数配置对话框,配置完毕并确定后,接着获取当前活动的标签对象,也就是获取当前活动的工作流。然后运行这个job。
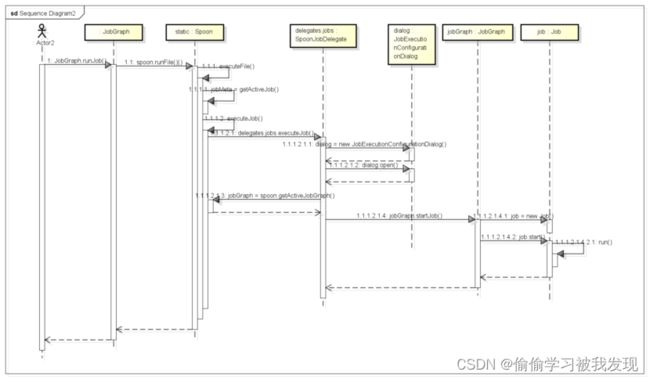
jobGraph.startJob函数代码如下:
public synchronized void startJob(JobExecutionConfiguration executionConfiguration) {
if (job == null) // Not running, start the transformation...
{
// Auto save feature...
//自动保存,如果当前job未保存,则必须先保存为kjb文件
if (jobMeta.hasChanged()) {
if (spoon.props.getAutoSave()) {
…
job = new Job(log, jobMeta.getName(), jobMeta.getFilename(), null);
…
job.start();
…
}
job 是JobGraph类的成员变量用来控制jobMeta的执行,它是一个线程类对象。这个函数首先如果当前jobMeta没有保存,则需要保存;接着新建一个Job类对象将job与当前jobMeta关联起来;最后启动线程job.start()。
上面的过程的时序图如下:
接下来我们看看Job.run()函数
public void run()
{
try
{
stopped=false;
finished=false;
initialized = true;
…
// Run the job, don't fire the job listeners at the end
//执行
result = execute(false);
}
catch(Throwable je)
{…
}}
Result用来保存执行结果
result = execute(false)函数代码如下:
private Result execute(boolean fireJobListeners) throws KettleException
{
…
// Where do we start?寻找开始组件
JobEntryCopy startpoint;
beginProcessing();
startpoint = jobMeta.findJobEntry(JobMeta.STRING_SPECIAL_START, 0, false);
if (startpoint == null) { throw new KettleJobException(Messages.getString("Job.Log.CounldNotFindStartingPoint")); }
JobEntrySpecial jes = (JobEntrySpecial) startpoint.getEntry();
Result res = null;
boolean isFirst = true;
while ( (jes.isRepeat() || isFirst) && !isStopped())
{
isFirst = false;
//进入递归执行组件
res = execute(0, null, startpoint, null, Messages.getString("Job.Reason.Started"));
}
…
return res;
}
递归方式执行job中的entry,自动的从一个entry到另一个entry执行。使用回溯算法。
private Result execute(final int nr, Result prev_result, final JobEntryCopy startpoint, JobEntryCopy previous, String reason) throws KettleException
{
…
// Execute this entry...
JobEntryInterface cloneJei = (JobEntryInterface)jei.clone();
((VariableSpace)cloneJei).copyVariablesFrom(this);
//调用cloneJei自己的execute函数,做和自己功能相关的处理。
// cloneJei是一个有确定类型的JobEntry
final Result result = cloneJei.execute(prevResult, nr, rep, this);
…
// Same as before: blocks until it's done
//递归执行该函数,运行下一个entry
res = execute(nr+1, result, nextEntry, startpoint, nextComment);
…
}
该过程的时序图如下:

- 结果展示
结果显示是指运行job后,将运行结果展示到应用程序的Execution results面板中,如下图:

包括三个标签:History、Logging和Job metrics,分别展示不同的信息。
JobGraph.startJob()函数中运行job,运行结束后获取结果信息。
jobGraph.startJob函数代码如下
public synchronized void startJob(JobExecutionConfiguration executionConfiguration) {
if (job == null) // Not running, start the transformation...
{
// Auto save feature...
if (jobMeta.hasChanged()) {
if (spoon.props.getAutoSave()) {
…
job = new Job(log, jobMeta.getName(), jobMeta.getFilename(), null);
…//运行
job.start();
…
// Show the execution results views
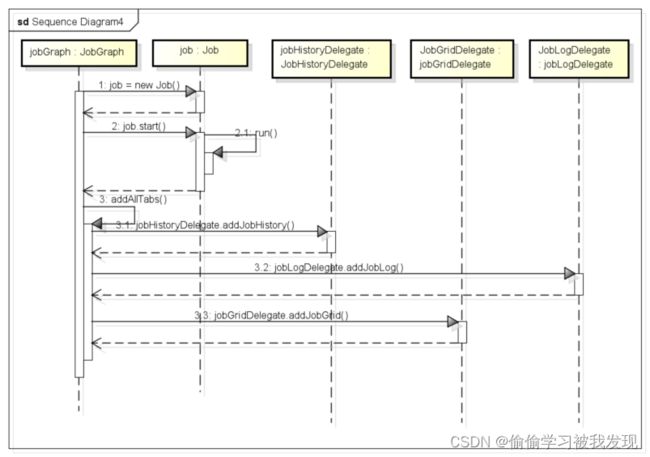
//添加结果显示的三个标签页
addAllTabs();
…
}
添加显示结果的三个标签页
public void addAllTabs() {
CTabItem tabItemSelection = null;
if (extraViewTabFolder != null && !extraViewTabFolder.isDisposed()) {
tabItemSelection = extraViewTabFolder.getSelection();
}
//三个标签页
jobHistoryDelegate.addJobHistory();
jobLogDelegate.addJobLog();
jobGridDelegate.addJobGrid();
…
}
整个时序图过程如下:
- 执行示例说明
调试一个Job,其拓扑如下:
黑色Hop代表无条件执行下一个JobEntry,红色代表结果为false执行下一jobEntry,绿色代表结果为true执行下一跳。
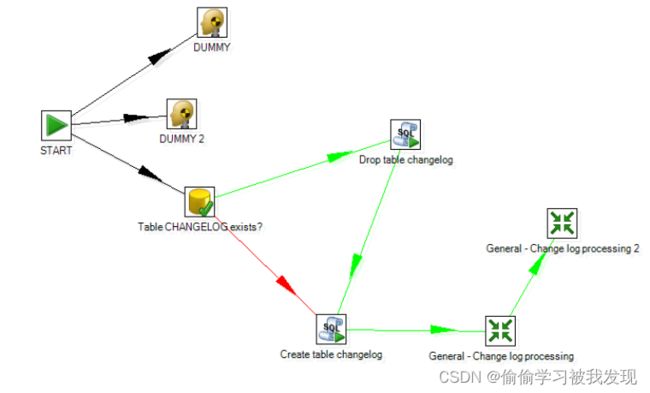
General-Change log Processing和General-Change log Processin 2是两个trans。
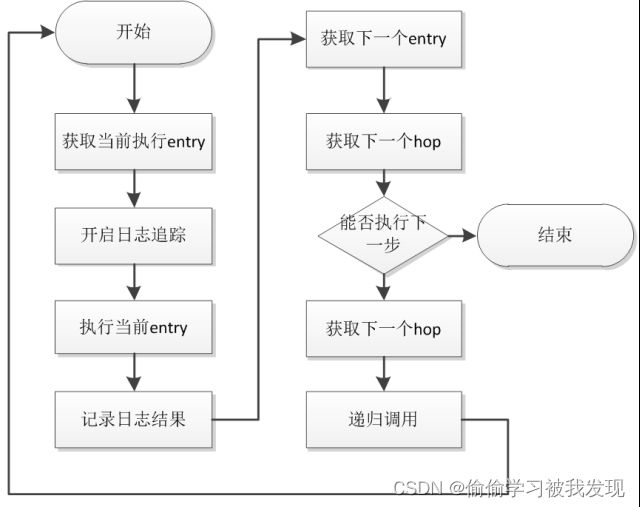
job的执行顺序为jobEntry的深度遍历,如标号所示。 - JobEntry
具体每个组件的执行体对应engine.src.org.pentaho.di.job.entries包内每个entry的具体实现。
execute()方法2中调用jobEntry的execute()完成jobEntry的具体功能。 - 向job添加entry
首先创建job,即jobMeta变量,它存储着整个job的相关信息和资源。然后将你所要的entry加入JobMeta.jobcopies中(用户界面表现为将组件拖拽到编辑区),并且连接好各个组件。
entry就是job类型的组件(区别于step),entry的添加也有两种不同的方式,分别使用在不同的场合:从kjb文件中加载原有的entry;创建新的entry并加入到job中。 - 从kjb文件中加载entry
从上面的打开job过程可知,entry的加载就是读取kjb文件达的相关部分。用JobMeta.loadXML函数来读取kjb文件)加载所有entry,并加入jobMeta。
调用语句jobMeta.loadXML(jobNode, spoon.getRepository(), spoon),由spoon.getRepository()提供文件路径和名称。
函数的部分代码如下:
public void loadXML(Node jobnode, Repository rep, OverwritePrompter prompter) throws KettleXMLException {
Props props = null;
…
// get job info:
setName( XMLHandler.getTagValue(jobnode, "name") );
…
/*
* read the job entries...读取xml文件中的相应节点
*/
Node entriesnode = XMLHandler.getSubNode(jobnode, "entries"); //$NON-NLS-1$
int tr = XMLHandler.countNodes(entriesnode, "entry");
//逐个读取节点,并根据节点信息,构建JobEntryCopy对象,加
//入到工作流中
for (int i = 0; i < tr; i++) {
Node entrynode = XMLHandler.getSubNodeByNr(entriesnode, "entry", i); //$NON-NLS-1$
JobEntryCopy je = new JobEntryCopy(entrynode, databases, slaveServers, rep);
…
// Add the JobEntryCopy...
addJobEntry(je);
}
//add hop连线
Node hopsnode = XMLHandler.getSubNode(jobnode, "hops"); //$NON-NLS-1$
int ho = XMLHandler.countNodes(hopsnode, "hop"); //$NON-NLS-1$
for (int i = 0; i < ho; i++) {
Node hopnode = XMLHandler.getSubNodeByNr(hopsnode, "hop", i); //$NON-NLS-1$
JobHopMeta hi = new JobHopMeta(hopnode, this);
jobhops.add(hi);
}
…
}
函数首先根据所给的根节点,逐个读取节点子节点,并根据节点信息,构建JobEntryCopy对象,然后加入到jobMeta中。最后加入hop信息。
语句JobEntryCopy je = new JobEntryCopy(entrynode, databases, slaveServers, rep)调用下面函数:
public JobEntryCopy(Node entrynode, List databases, List slaveServers, Repository rep) throws KettleXMLException
{
try
{//获取当前节点代表的组件类型
String stype = XMLHandler.getTagValue(entrynode, "type");
//根据该类型从pluginList 中获取对应的JobPlugin 对象
JobPlugin jobPlugin = JobEntryLoader.getInstance().findJobEntriesWithID(stype);
…
// Get an empty JobEntry of the appropriate class...
//根据jobPlugin获取与之相应的entry类对象,此时的entry并没有任何
//信息,只是一个特定类型的entry
entry = JobEntryLoader.getInstance().getJobEntryClass(jobPlugin);
if (entry != null)
{
//调用该entry自身的loadXML()函数,从文件中加载相应的组件信息
entry.loadXML(entrynode, databases, slaveServers, rep);
…
}
}
JobEntryCopy的构造函数,能够根据节点,构建节点中描述的相应组件实例。
JobEntryLoader.getInstance().getJobEntryClass(jobPlugin)函数下面有说明。
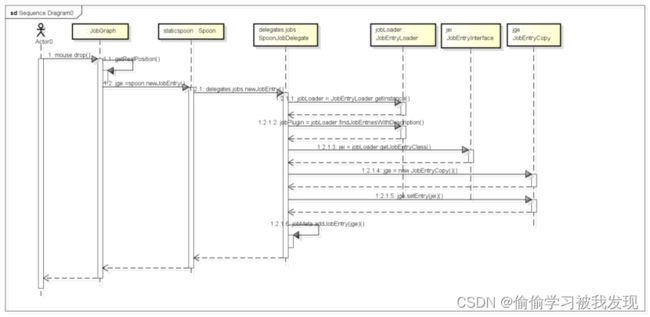
加载entry组件的时序图如下:

- 创建新的entry
通过从组件树中拖拽需要的组件到工作区中,可以创建新的组件。拖拽响应函数如下:
public void drop(DropTargetEvent event)是一个事件响应函数,响应鼠标拖拽放开事件。当我们从核心对象树中将组件拖拽到工作区并放下时便会触发这个事件。它的部分代码如下:
public void drop(DropTargetEvent event) {
…
//获取当前坐标
Point p = getRealPosition(canvas, event.x, event.y);
//获取组件类型
try {
DragAndDropContainer container = (DragAndDropContainer) event.data;
//entry是一个string对象,表示该类组件的描述,用来区别不同的组件
String entry = container.getData();
switch (container.getType()) {
case DragAndDropContainer.TYPE_BASE_JOB_ENTRY:
// Create a new Job Entry on the canvas
{//创建新的组件对象并加入到jobMeta中
JobEntryCopy jge = spoon.newJobEntry(jobMeta, entry, false);
…
newJobEntry函数,参数typeDesc是类型描述信息,jobMeta是当前job
public JobEntryCopy newJobEntry(JobMeta jobMeta, String typeDesc, boolean openit) {
return delegates.jobs.newJobEntry(jobMeta, typeDesc, openit);
}
delegates.jobs.newJobEntry函数,参数和上面的函数意义相同
public JobEntryCopy newJobEntry(JobMeta jobMeta, String type_desc, boolean openit)
{
//获取JobEntryLoader的自身静态变量jobEntryLoader
JobEntryLoader jobLoader = JobEntryLoader.getInstance();
JobPlugin jobPlugin = null;
try
{//从jobEntryLoader.pluginList中获取响应的jobPlugin
jobPlugin = jobLoader.findJobEntriesWithDescription(type_desc);
if (jobPlugin == null)
{//一些特殊组件
// Check if it's not START or DUMMY
if (JobMeta.STRING_SPECIAL_START.equals(type_desc)
|| JobMeta.STRING_SPECIAL_DUMMY.equals(type_desc))
{//特殊的组件
jobPlugin = jobLoader.findJobEntriesWithID(JobMeta.STRING_SPECIAL);}
}
if (jobPlugin != null)
{//
// Determine name & number for this entry.
String basename = type_desc;
int nr = jobMeta.generateJobEntryNameNr(basename);
String entry_name = basename + " " + nr; //$NON-NLS-1$
// Generate the appropriate class...
//根据jobPlugin 的信息,构建响应的JobEntry 对象
JobEntryInterface jei = jobLoader.getJobEntryClass(jobPlugin);
…
//创建JobEntryCopy对象,初始化一些相关信息
JobEntryCopy jge = new JobEntryCopy();
jge.setEntry(jei);
jge.setLocation(50, 50);
jge.setNr(0);
//加入到jobMeta中
jobMeta.addJobEntry(jge);
…
大概说说这个函数的整个过程:首先是传入参数jobMeta和String type_desc,一个是当前工作流对象,一个是要添加组件的描述信息。要构建一个entry,必须要从jobEntryLoader.pluginList列表(初始化部分有介绍)中获取和描述信息相符合的JobPlugin对象,然后再根据这个对象生成一个实现JobEntryInterface接口的对象(到此,已经获取了一个特定类型的entry,如本例中的JobEntrySuccess),最后将其装换成JobEntryCopy对象并加入到jobMeta中。
下面是JobEntryInterface jei = jobLoader.getJobEntryClass(jobPlugin) ;语句调用函数getJobEntryClass
public JobEntryInterface getJobEntryClass(JobPlugin sp) throws KettleStepLoaderException
{
…
//根据 sp 的类型获取该类型的组件的加载类cl
switch (sp.getType())
{
case JobPlugin.TYPE_NATIVE:{
cl = Class.forName(sp.getClassname());
}break;
case JobPlugin.TYPE_PLUGIN: {
ClassLoader ucl = getClassLoader(sp);
cl = ucl.loadClass(sp.getClassname());
}break;
…
}
//cl 对应着特定的类型组件,因此下面语句可以返回一个特定的entry对象
JobEntryInterface res = (JobEntryInterface)cl.newInstance();
…
return res;
…
}
总的来说就是根据传入的JobPlugin获取特定类型的entry加载类,然后使用加载类获取该类型的entry对象。
该过程时序图如下:
b)编辑entry
双击工作区域中的组件,弹出组件参数配置对话框,实现entry的编辑。
首先捕捉双击事件
canvas.addMouseListener(new MouseAdapter() {
public void mouseDoubleClick(MouseEvent e) {
clearSettings();
//获取坐标
Point real = screen2real(e.x, e.y);
//尝试根据坐标,从当前的jobMeta中获取entry
JobEntryCopy jobentry = jobMeta.getJobEntryCopy(real.x, real.y, iconsize);
if (jobentry != null) {
//如果当前双击的区域存在组件
if (e.button == 1) {
editEntry(jobentry);
}
…
}}
JobGraph中的editEntry函数
protected void editEntry(JobEntryCopy je) {
spoon.editJobEntry(jobMeta, je);
}
Spoon中的editJobEntry函数
public void editJobEntry(JobMeta jobMeta, JobEntryCopy je) {
delegates.jobs.editJobEntry(jobMeta, je);
}
delegates.jobs.editJobEntry(jobMeta, je)语句调用的函数如下:
public void editJobEntry(JobMeta jobMeta, JobEntryCopy je)
{
try{
…
JobEntryCopy before = (JobEntryCopy) je.clone_deep();
JobEntryInterface jei = je.getEntry();
…
//获取相应的对话框类
JobEntryDialogInterface d = getJobEntryDialog(jei, jobMeta);
if (d != null)
{
if (d.open() != null)
{
// First see if the name changed.
// If so, we need to verify that the name is not already used in the job.
//
…
spoon.refreshGraph();
spoon.refreshTree();
}
}
else{…
}
} catch (Exception e) {…
}
}
根据特定的entry,获取对应的对话框,并且打开对话框,编辑entry。
JobEntryDialogInterface d = getJobEntryDialog(jei, jobMeta)语句调用下列函数
public JobEntryDialogInterface getJobEntryDialog(JobEntryInterface jei, JobMeta jobMeta)
{
//获取对话框类的名称
String dialogClassName = jei.getDialogClassName();
try
{
Class dialogClass;
Class[] paramClasses = new Class[] { spoon.getShell().getClass(), JobEntryInterface.class,
Repository.class, JobMeta.class };
Object[] paramArgs = new Object[] { spoon.getShell(), jei, spoon.getRepository(), jobMeta };
Constructor dialogConstructor;
//获取对话框类
dialogClass = jei.getPluginID()!=null?JobEntryLoader.getInstance().loadClassByID(jei.getPluginID(), dialogClassName):JobEntryLoader.getInstance(). loadClass(jei.getJobEntryType().getDescription(),dialogClassName);
dialogConstructor = dialogClass.getConstructor(paramClasses);
//返回对话框类对象
return (JobEntryDialogInterface) dialogConstructor.newInstance(paramArgs);
} catch (Throwable t)
{…
}
return null;
}
getDialogClassName()用来获取对话框类名,它在JobEntryInterface中定义,在JobEntryBase中实现,代码如下:
public String getDialogClassName()
{
//当前类名
String className = getClass().getCanonicalName();
//加上前缀di.ui.
className = className.replaceFirst("\\.di\\.", ".di.ui.");
//加上后缀Dialog
className += "Dialog";
//最后的className为:di.ui.当前类名Dialog
return className;
}
在函数中根据当前的entry类名及其所在包,返回其对应的Dialog类所在的包及类名。
可见entry编辑时才去查找其对应的参数配置对话框类。
整个过程时序图如下
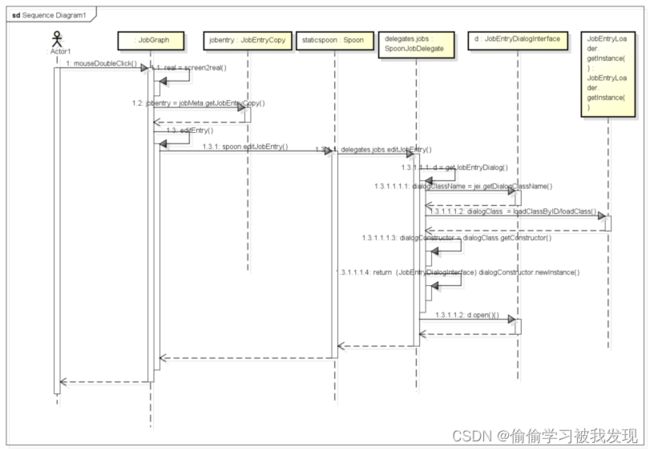
- 相关类和接口
- JobMeta
维护整个Job的元数据,用来定义一个Job及进行与该Job加载、保存、修改等相关的操作。
该类用来定义一个job及进行与该job加载、保存、修改等相关的操作。
它的部分成员变量如下表:
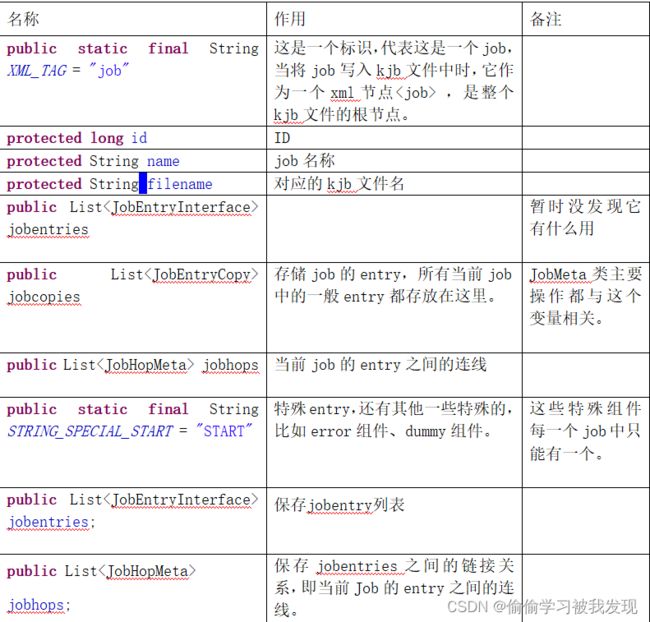
该类的部分成员函数如下
//添加entry,实际上是添加一个JobEntryCopy对象
- JobMeta
public void addJobEntry
//添加hop
public void addJobHop
//查找特定的entry
public JobEntryCopy findJobEntry
//查找特定的hop
public JobHopMeta findJobHop
//查找下一个entry,从当前entry到hop指出的entry
public JobEntryCopy findNextJobEntry
//查找前一个entry
public JobEntryCopy findPrevJobEntry
//找到start组件
public JobEntryCopy findStart()
//获取指定的entry
public JobEntryCopy getJobEntry
//获取指定的hop
public JobHopMeta getJobHop
//获取用户选择的entry
public JobEntryCopy getSelected
//写xml文件,将该工作流的信息写入到xml文件,不包括entry的实际内容
public String getXML()
//加载xml文件
public void loadXML()
该类的部分成员函数如下
//添加entry,实际上是添加一个JobEntryCopy对象
public void addJobEntry
//添加hop
public void addJobHop
//查找特定的entry
public JobEntryCopy findJobEntry
//查找特定的hop
public JobHopMeta findJobHop
//查找下一个entry,从当前entry到hop指出的entry
public JobEntryCopy findNextJobEntry
//查找前一个entry
public JobEntryCopy findPrevJobEntry
//找到start组件
public JobEntryCopy findStart()
//获取指定的entry
public JobEntryCopy getJobEntry
//获取指定的hop
public JobHopMeta getJobHop
//获取用户选择的entry
public JobEntryCopy getSelected
//写xml文件,将该工作流的信息写入到xml文件,不包括entry的实际内容
public String getXML()
//加载xml文件
public void loadXML()
- JobEntryCopy
该类代表一个entry及额外的关于图像界面的相关信息,如位置、选择状态。主要用于维护每一个不同entry或者相同entry的不同副本的信息。
主要成员:
private JobEntryInterface entry;当前组件,具体entry,执行入口
private int nr;副本数,一个编辑区里可以出现多个相同组件
private boolean selected;是否被选择
private Point location;图标位置,工作区中的坐标
private boolean draw;
private long id;
相关函数如下:
//写xml文件,主要是写entry的共性部分,比如坐标
public String getXML
//判断是否被选择
public boolean isSelected
//设置entry对象
public void setEntry(JobEntryInterface je)
//获取坐标
public Point getLocation
//设置坐标
public void setLocation(Point pt);
-
JobEntryLoader
这个类作用是加载所有的entry,entry的来源有两种,一种是内置的,一种是插件形式。
JobEntryLoader的一些重要成员变量如下:
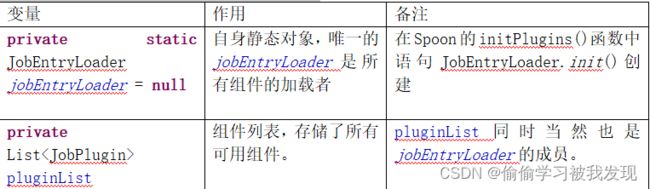
JobEntryLoader的一些重要成员函数如下: -
加载所有组件
public static final void init() throws KettleException
包括加载内置组件和加载插件 -
加载内置组件
public boolean readNatives()
内置组件在xml文件中定义。 -
加载插件
public boolean readPlugins()
插件在plugin目录下,一个plugin为一个jar -
根据特定的plugin返回相应的entry
public JobEntryInterface getJobEntryClass(String desc) throws
因为工作流中真正执行单元功能的是entry,pluginList中储存的并非entry,只是一些加载entry所需要的信息(比如加载类、entry类型、ID等),所以我们必须根据plugin加载相应的entry并返回。 -
JobEntryInterface
JobEntryInterface是Job Entry插件的主要实现接口,是所有具体entry必须实现的接口。需要实现的功能主要是获取entry的一些共性信息,比如名称、ID、类型、描述信息、是否是特殊entry、参数配置对话框类名、写xml、读xml等。
每个具体engine.src.org.pentaho.di.job.entries包下的 entry类需要实现的接口,包含execute()方法。
几个比较重要的函数如下:
//获取该entry对应的参数配置对话框类
public String getDialogClassName()
//读kjb中标签
public void loadXML
//写kjb中的< entry>标签
public String getXML
//执行entry
public Result execute(Result prev_result, int nr, Repository rep, Job parentJob) throws KettleException;
- JobEntryDialogInteface
负责构建和打开参数设置对话框。Spoon通过调用open函数打开该对话框,spoon是使用swt框架的,所以对话框也应使用swt来实现。 - JobEntryBase
该类是所有entry的基类,包含了entry一些共性的变量和操作。因为每一个具体的entry(如prime组件)都必须继续JobEntryBase类,并且实现JobEntryInterface接口,所以可以在JobEntryBase类中实现JobEntryInterface接口中的一些函数。这些函数应该不区别具体的entry,对每一种不同的entry都是一样的操作。
JobEntryBase中的一部分变量如下:

主要的函数和JobEntryInterface差不多。 - JobEntrySpecial
功能是开启一个job,只是简单地对传递来的preResult设置它的的result属性值为true,(Job项目据此判断前一结果执行完毕)。返回该对象即可。 - JobEntryTableExit
功能是判断一个table是否存在数据库中。JobEntryTableExit Job项目有属性tablename和DatabaseMeta(对数据库的元数据信息描述)根据DatabaseMeta得到一个Dabase对象db,建立连接db.connect(); 调用db.checkTableExists(tablename)根据此返回值设置preResult的result属性为否为true。返回preResult对象。 - JobEntryTrans
JobEntryJob和JobEntryTrans是嵌套job或trans的Job项目(JobEntry)。它们是比较复杂的job项目。
作用是执行一个trans。首先实例化一个TransMeta,之后实例化Trans。调用trans.start(),当执行完毕后调用函数trans.getResult(),并把结果加到preResult中,返回该对象即可。 - 组件JobEntryXXX
Entry有很多种,每种不同的entry代表不同功能。但是各个entry所具有的函数差别不大,只是内容有比较大的差别。下面拿prime组件来介绍一个具体的组件的实现类构成。
JobEntryPrime是主键约束组件的实现类,其主要功能是检查数据中的主键约束关系是否能够满足。支持多字段属性的主键检查,支持异常数据(不满足约束的数据)保存到其他文件。
类定义:public class JobEntryPrime extends JobEntryBase implements Cloneable,JobEntryInterface
继承JobEntryBase类,实现JobEntryInterface接口。
//克隆函数
public Object clone()
//写kjb文件函数
public String getXML()
//读取kjb文件
public void loadXML(Node entrynode, List databases,List slaveServers, Repository rep)
throws KettleXMLException
//执行该组件
public Result execute(Result previousResult, int nr, Repository rep,Job parentJob) throws KettleJobException
- JobEntryType枚举
列举所有内置entry类型及其描述,每一个内置entry必须注册一个类型以区别其他entry。 - Job类
Job的执行类,是一个线程类,本身实现了Thread是一个单独的线程。Job entry可以是单独的线程,也可以是顺序执行,大多数情况都是顺序执行下一步以上一步的执行结果为基础。Job类也包括转换加载、相关插件的实例化、初始化、运行、监视Job执行。
public class Job extends Thread implements VariableSpace, NamedParams
其主要功能是负责作业的执行。
该类的一些重要成员变量如下:
private JobMeta jobMeta//当前工作流
private Job parentJob//
private Result result//执行结果保存
private boolean finished//结束标志
线程的run函数
public void run()
执行entry
public Result execute(Boolean)
函数最终一一地从jobMeta中取出entry并调用entry它自己的execute方法。
m)Result
每一个jobEntryInterface的实现类在完成相应功能时,返回结果的类型。
Result中也可以有处理数据,这些处理数据可以作为下一个Job项目(JobEntry)的输入。但是容量受内存容量限制。
主要成员变量:
private boolean result;执行是否出现异常
private int exitStatus; 执行结果状态
private List rows;一个jobEntry完成处理后的数据(若存在)
private Map resultFiles;
- Transformation
这个模块和Job模块类似,主要负责转换执行相关的所有任务,包括转换加载、相关插件的实例化、初始化、运行、监视转换执行,并把内容放置到TransInfo类中。- 执行过程概述
Trans的执行机制是搭建一个结构,使得每一个step能够从自己的inputRowsets读,处理一行,将结果输出到自己的outputRowsets中。
注意:一个rowset对象既属于前一个step成员outputRowsets的一部分,也属于后一个对象的inputRowsets的一部分。所有的rowset信息都在Trans对象中以List形式维护。
- 执行过程概述
- Trans执行过程时序图
由于trans可以有TransGraph实例化,也可以由JobEntryTrans实例化。但基本过程是一样的,先实例化TransMeta,再实例化Trans,最终调用trans的start方法。
由TransGraph实例化如下图所示:
由JobEntryTrans实例化,如下图所示:

- Trans代码解释
- JobEntryTrans类execute( )
首先获取元数据,然后以此作为参数实例化trans
- JobEntryTrans类execute( )
TransMeta transMeta = getTransMeta(rep);
……
Trans trans = new Trans(transMeta);
……
trans.execute(args);
b)Trans类execute( )
具体执行前需要进行准备工作
public void execute(String[] arguments) throws KettleException{
prepareExecution(arguments);
startThreads();
}
- Trans的prepareExecution()
搭建以下结构:- 对每一个step根据hop信息进行找到下一个step或多个step。
- 对于每一个this step和nex tstep生成一个RowSet对象,作为缓存供this step写,同时供next step读取数据。
- 把此RowSet对象加入到Trans的List成员中保存。
List hopsteps=transMeta.getTransHopSteps(false);
得到step列表
……
对每一个step进行如下设置
for (int i=0;i nextSteps = transMeta.findNextSteps(thisStep);
int nrTargets = nextSteps.size();
for (int n=0;n - 根据TransMeta的step信息生成相应的StepMetaDataCombi(即steps)信息,加到steps列表中。
StepMetaDataCombi combi = new StepMetaDataCombi();
combi.stepname = stepMeta.getName();
combi.copy = c;
combi.stepMeta = stepMeta;
combi.meta = stepMeta.getStepMetaInterface();
StepDataInterface data = combi.meta.getStepData();
combi.data = data;
……
StepInterface step=combi.meta.getStep(stepMeta, data, c, transMeta, this);
在step初始化时,会把Trans中的List的相应的rowset加入到step的inputRowSets,和outputRowSets中。
combi.step = step;
steps.add(combi);
- Trans类startThreads( )
打开了所有的step线程,核心代码如下:
for (int i=0;i- Step执行
实现StepInterface的不同的step各个功能个不一样,但是它们之间也有一定的规律性。下图只列举了两个step,(TextInput)文本输入和Uniquerow(去重)。- 启动
每一个具体的step启动线程时,自动调用run函数,它们统一调用基类的静态方法
- 启动
public void run(){
BaseStep.runStepThread(this, meta, data);
}
- 处理
基类BaseStep采取了统一的处理方式,调用子类processRow以行为单位处理,核心代码如下:
while (stepInterface.processRow(meta, data) && !stepInterface.isStopped());
processRow( )通用过程是:调用基类BaseStep 的getRow( )得到数据,对一行数据处理,处理之后调用基类putRow( )方法数据保存至outputRowSets(即next step的inputRowSets)
- 元数据与数据关系。
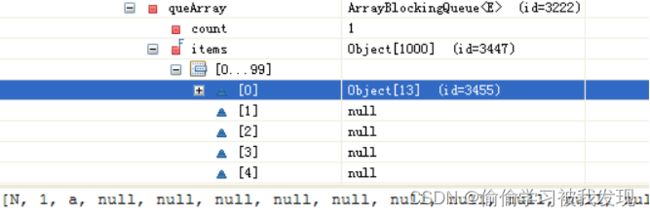
Trans中的ETL过程(每个step)以行为单位处理,其中行的元数据信息RowMeta和数据信息统一保存在RowSet对象中。
在RowSet中RowMeta的成员的调试结果如下。可见rowMeta储存了每列数据的名称和类型。第一列列名flag,数据是长度为1的String;第二列列名id…

RowSet的数据信息在queArray队列中,调试结果如下:可以看出第一个数据元素是一个Object包含了3列,数据内容为(N,1,a…)
- 相关类和接口
- JobEntryTrans
实现了JobEntryInterface的execute()方法,被job执行。由JobEntryTrans实例化Trans,并执行。 - TransGraph
当点击trans面板的run时,由TransGraph实例化Trans,并执行。
Trans主要成员有:
- JobEntryTrans
private TransMeta transMeta;
private Repository repository;
private Job parentJob;
private Trans parentTrans;
private List rowsets;
private List steps
其中最重要的是rowsets、steps。rowsets保存了所有hop对应的行元数据和数据信息。List steps封装了一个step的主要内容。
- TransMeta
描述了整个Trans的元数据信息。 主要的属性成员有:
private List steps;
private List hops;
private String name;
private Result previousResult;上一个jobentry的执行结果。
private List resultRows;这次trans执行后的数据结果。
private List resultFiles;
resultRows成员将作为result比部分返回多行的元数据和数据(如果有的话)需要返回数据结果时。把resultRows加入Result结果的rows列表,并返回。
- StepMetaDataCombi
提取了一个step所需的主要信息,把插件的主要实现类全部存储在这个类中,方便集中调用。
public class StepMetaDataCombi
{
public StepMeta stepMeta;
public String stepname;
public int copy;
public StepInterface step;
public StepMetaInterface meta;
public StepDataInterface data;
}
- TransHopMeta
描述hop信息。 - StepMeta
描述step的公有基本信息(stepid,stepname),对于每一个具体的step,由成员变量StepMetaInterface step来描述。 - StepInterface
主要成员函数:
processRow()对一行的数据处理。
putRow()把处理后的数据放入下一个step的inputrowsets中。 - StepBase
实现了StepInterface是各step具体实现类的基类。完成了公用的处理函数,如putRow(),但是对于更具体的processRow()在StepBase的子类中。StepBase的主要成员有
public ArrayList inputRowSets,outputRowSets;
StepBase的子类每次从inputRowSets中取出一行数据,向outputRowSets中写入一行数据。 - StepDataInterface
与step相关的数据信息。比如行的元数据信息。StepMetaInterface的实现类是与具体step相关的元数据信息,与StepMeta配合使用,共同描述具体step的元数据信息。 - RowSet

RowSet类中包含源step,目标step和由源向目标发送的一个rowMeta和一组data。其中data数据是以行为单位的队列(queArray)。一个RowSet作为此源step的outputrowsets的一部分。同时作为目标step的inputRowsets一部分。源Step每次向队列中写一行数据,目标step每次从队列中读取一行数据。 - RowMetaAndData
public class RowMetaAndData implements Cloneable{
private RowMetaInterface rowMeta;//行的元数据,描述了每行的数据名字,数据类型。
private Object[] data;//数据
}
- StepInitThread类
Step初始化线程包装类,使用多线程,调用所有StepInterface实现类的Init函数。 - RunThread类
步骤处理线程包装类,这个类能够处理异常并将其记录到日志中。同时,也能够在异常发生或者执行结束后,记录相关内容、关闭相关资源。 - 菜单加载
有三种菜单:程序工具栏菜单、标签页上的菜单和右键菜单。- 程序菜单栏
这种菜单在界面初始化时就被生成并显示到程序的菜单栏上。
调用Spoon.init(TransMeta ti)实现菜单的初始化。
- 程序菜单栏
public void init(TransMeta ti) {
…
initFileMenu();
...
addMenu();
addTree();
// addCoreObjectsExpandBar();
addTabs();
…
}
Spoon.addMenu()函数
public void addMenu() {
…
try {
//从ui/menubar.xul文件中生成菜单栏
menuBar = XulHelper.createMenuBar(XUL_FILE_MENUBAR, shell, new XulMessages());
List ids = new ArrayList();
//菜单项
ids.add("trans-class");
…
this.menuMap = XulHelper.createPopupMenus(XUL_FILE_MENUS, shell, new XulMessages(), ids);// createMenuBarFromXul();
} catch (Throwable t) {…
}
//监听器
addMenuListeners();
//添加最近打开菜单项
addMenuLast();
}
XulHelper.createMenuBar(XUL_FILE_MENUBAR, shell, new XulMessages())函数代码如下:
public static MenuBar createMenuBar(String menuFile, Shell shell,Messages xulMessages) throws KettleException
{
// first get the XML document
try
{
URL xulFile = getAndValidate(menuFile);
Document doc = XMLHandler.loadXMLFile(xulFile);
//此处从xul文件中加载菜单项
MenuBar menuBar = MenuHelper.createMenuBarFromXul(doc, shell, xulMessages);
shell.setMenuBar((org.eclipse.swt.widgets.Menu) menuBar.getNativeObject());
return menuBar;
} catch (IOException e){
…
}
}
Xul文件格式如下(项目的在根目录ui/menubar.xul)
取其中的一个标签来说明:
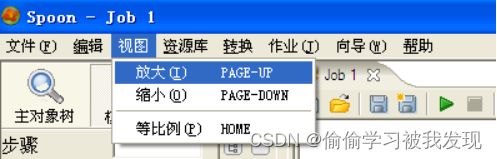
- 标签页上的菜单
因为一个JobGraph对象表示一个标签页,所以我们可以在JobGraph类中找到与菜单相关的成员变量:private XulToolbar toolbar;
它在下面函数中被初始化加载菜单项
private void addToolBar() {
try {
toolbar = XulHelper.createToolbar(XUL_FILE_JOB_TOOLBAR, JobGraph.this, JobGraph.this, new XulMessages());
…
}
}
XUL_FILE_JOB_TOOLBAR指明的文件是程序根目录下的ui.job-toolbar.xul,其内容如下:
- 右键菜单
工作区中的右键菜单由JobGraph.setMenu()函数构建,它的菜单文件在根目录的ui.menus.xul中
右击工作区中的组件
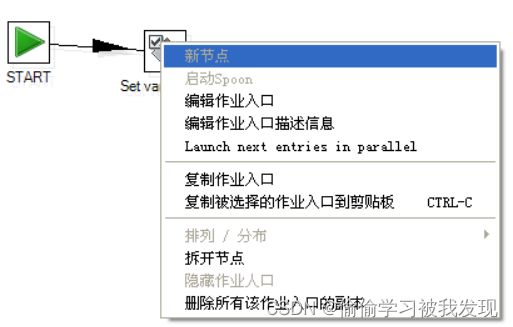
右击工作区的空白区域

Kettle资源文件及配置文件
- kettle.properties
一般存放在应用程序的工作主目录C:\Documents and Settings\Administrator.kettle下里面有几个文件,存放用户对于系统的喜好配置以及历史信息,这些信息会在启动时被读取。其中kettle.properties较为重要,它在程序启动环境初始化过程被读取;和.languageChoice文件,它指明了当前的语言设定。
格式如下:
#Language Choice
#Tue Apr 12 16:13:38 CST 2011
#这个是当前默认语言
LocaleDefault=zh_cn
#这个是第二语言
LocaleFailover=en_us - kettle-config.xml
在src.org.pentaho.di.core.config包中
整个文件分为5个部分(5个标签)提供程序初始化时加载组件的一些必要信息。5个部分包括对job类型组件的加载配置说明、step类型组件的加载配置说明和plugin类型组件的加载配置说明。
比如加载entry组件需要下面的信息
org.pentaho.di.core.config.DigesterConfigManager
标签指明处理加载entry的类;
标签标签中指明的xml文件中)。
- kettle-job.xml
在src包下
所有job组件都必须在此注册,每一个标签就是一个组件,提供加载一个组件的必要信息。
ognl:@org.pentaho.di.job.JobEntryType@WAIT_FOR_FILE
org.pentaho.di.job.entries.waitforfile.JobEntryWaitForFile
ognl:@org.pentaho.di.job.JobEntryCategory@FILE_MANAGEMENT.getName()
ognl:@org.pentaho.di.job.entry.Messages@getString("JobEntry.WaitForFile.Tooltip")
ui/images/WFF.png
…其他job
标签表示一个特定id的组件
标签表明了该组件的类型,这个类型必须出现在org.pentaho.di.job.JobEntryType枚举中。
标签指明该组件的实现类
标签指明当鼠标移动到组件图标上时出现的提示信息
标签指明该组件的图标文件。
-
Message文件
在你使用的类所在的包下,子包Message中。
格式为:名称 = 值
不同的语言我们创建不同的message文件。名称格式为Message_<语言简称>_<国家简称>.properties,例如中文中国:Message_zh_CN. Properties。 -
.kjb文件格式
.kjb是Job元数据文件的后缀。主要有三部分构成:job基本信息,job的entris组件信息和组件之间的链接hop信息。标签为job。 -
job标签

job的基本信息包括name,描述信息,创建和修改日期等。 -
entries标签
job的信息有两部分:
公有信息:每个entry都具有的信息。如name,description,jobentrytype等,由JobEntryBase保存。
私有信息:每个具体step继承了JobEntryBase并各自特有的信息,如开始entry的xml中其他信息,如下图所示。

每个标签内容对应界面层元素如下图

-
hops标签
Hops信息主要有:源和目标entry信息;链接的状态,是否开启;链接的类型:条件执行还是无条件执行等。如下图所示:
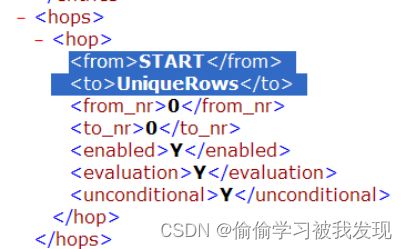
-
.ktr文件格式
一个UniqueRiws.ktr 文件的Transformation顶层有Transformation信息 , 信息。信息组成。

-
info标签

对应的界面层设置是:
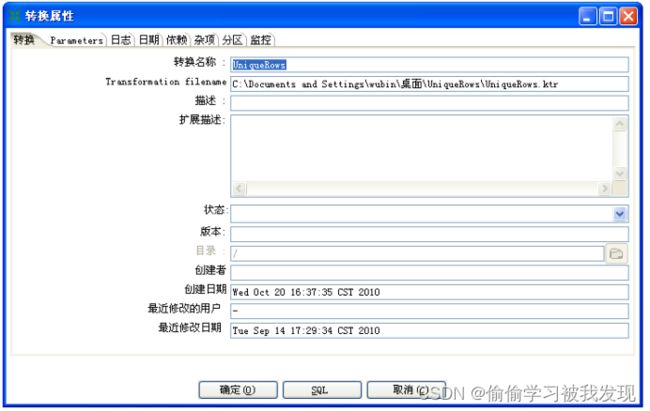
-
order标签

-
step标签
每个step都有的信息:如stepname,step类型信息,所在面板位置信息,
具体step特有的信息:如去重是否对重复的行计数,以及计数变量名。
文本输出的格式,分隔符,数据名和数据类型信息。
以下是去重step对应的内容。

对应的GUI设置为:

-
图标
- 图标位置
位于ui\images文件夹中。
位于ui.package-res.ui.images文件夹中。

- 配置文件
ui\下LAF.properties文件,内容如下:
splash_image=ui/images/kettle_splash.png
其中splash_image为程序中用到的property的key值,返回值为ui/images/kettle_splash.png。 - 代码说明
设置文件:
- 图标位置
package org.pentaho.di.laf;
public class OverlayPropertyHandler implements PropertyHandler {
protected static final String propFile = "ui/laf.properties";
……
}
使用:
final Image kettle_image = ImageUtil.getImageAsResource(display,
BasePropertyHandler.getProperty("splash_image"));
- 背景图片
找到ui.package-res.ui.images.kettle_splash.png,替换该图片 - 版本信息
找到e.gc.drawText(versionText, 290, 205, true); 改为e.gc.drawText(“Kettle V1.0”, 290, 205, true);
- 插件配置文件
plugin.xml的功能是告诉kettle插件的元数据类,插件的名称及描叙,还有需要加载的jar包。
