数据库(MySql 8.0)详细学习笔记
一,安装与卸载
二,特点与数据模型
1)关系型数据库:由多张建立在关系模型上、相互连接的存储数据的表组成的数据库。
2)数据模型:客户端通过DBMS连接数据库,借助SQL操作数据库
3)优点:
存储:表存储数据,格式统一、容易维护。
操作:使用统一的SQL语言操作。
三,SQL
规则与规范:
- SQL可以单行书写,也可多行,以分号结束。
- SQL可以使用空格增强可读性
- Windows下不区分大小写,关键字建议大写
- 注释:#(mysql独有)-- 注释内容(--后面有一个空格)多行注释:/*注释内容*/
分类:
DDL:数据定义语言
定义数据库/表/字段/索引等。
DML:数据操纵语言
管理数据库中的表记录:增删改
DQL:数据查询语言
查询数据库中的表记录
DCL:数据控制语言
管理用户访问,权限设置等。
DDL:数据定义语
1)对数据库:
1)查询所有数据库: show databases;
2)创建数据库:create database[if not exists]数据库名 [default charset 字符集名称(方括号括号内容可选)
3) 使用数据库:use 数据库名;
4)查询当前使用的数据库:select database();
5)删除数据库:drop database [if exists]数据库名称。
示例:
#查看所有数据库:初始有四个数据库
SHOW DATABASES;
#创建学生数据库:student
CREATE DATABASE IF NOT EXISTS student;
#使用学生数据库
USE student;
#查询当前使用的数据库
SELECT DATABASE();
#删除数据库
DROP DATABASE IF EXISTS student;
SHOW DATABASES;
2)对表
使用表相关操作前需要先指定数据库,即使用数据库。
1)查询所有表:show tables;
2)创建表:create table if not exists 表名(
字段1 字段类型 [comment 注释内容])[commnet 表注释];
3)查看表结构:desc 表名;
4)查看建表语句:show create table 表名;
5)添加字段:alter table 表名 add 字段名 类型[注释][约束];
6)修改字段:
1)修改字段类型:alter table 表名 modify 字段1 类型 ,字段2 类型 ...;
2)修改字段名和字段类型:alter table 表名 change 旧字段名 新名字 类型;
7)删除字段:alter table 表名 drop 字段名;
8)修改表名:alter table 表名 rename to 新名字;
9)删除表:
无论哪一种均会清空表的内容。
删除表:drop table [if exists] 表名;(销毁表)
删除指定表并建立新的空表:truncate table 表名;(相当于清空内容)
示例:
#查看所有数据库:初始有四个数据库
SHOW DATABASES;
#创建学生数据库:student
CREATE DATABASE IF NOT EXISTS student;
#使用学生数据库
USE student;
SHOW TABLES; #此时没有表
#创建表:score
CREATE TABLE IF NOT EXISTS score(
id VARCHAR(20) COMMENT '学号',
NAME VARCHAR(20)COMMENT '学生姓名',
score TINYINT UNSIGNED )COMMENT '分数表';
#查看表结构
DESC score;
#查看建表语句:
SHOW CREATE TABLE score;
#添加新字段性别:gender 类型为char(2)
ALTER TABLE score ADD gender CHAR(2);
DESC score;
#修改id类型为int
#修改score为grade 类型为char(10)
ALTER TABLE score MODIFY id INT;
ALTER TABLE score CHANGE score grade CHAR(10);
DESC score;
#删除字段gender
ALTER TABLE score DROP gender;
DESC score;
#修改表名为s_inso
ALTER TABLE score RENAME TO s_info;
SHOW TABLES;
#删除表
DROP TABLE s_info;
SHOW TABLES;
数据类型
只列举了常用的。
1) 数值类型

说明:
- 分为有符号和无符号数值singned和unsigned区分
- 精度指数字长度,标度指小数的位数
2)字符串类型

说明:
使用时可指定长度。如char(10),varchar(20)说明字符长度。区别为:char类型的每个字符无 论是否小于或等于指定长度,均以指定长度村存储,而varchar会计算真实的存储长度。
3)日期类型

DML:数据操纵语言
用于对表记录进行增删改等操作。
1)增加记录:insert into
创建号数据库和表以后相当于搭建好存放数据的容器,增加操作相当于往表中存储数据。
1)逐条添加:
指定字段:insert into 表名(字段1,2,3...)values(值1,2,3...);
全部字段:insert into 表名 values(值1,2,3....);
(字段顺序和值的顺序要保持一直。值应该是字段允许范围,全字段时注意数量相 同)
2)批量添加:
指定字段:insert into 表名 (字段1,2,3...)values(值1,2,3...),
字段1,2,3...)values(值1,2,3...),
字段1,2,3...)values(值1,2,3...);
全部字段:insert into 表名 values(值1,2,3...),
字段1,2,3...)values(值1,2,3...),
字段1,2,3...)values(值1,2,3...);
(注意事项:
1:字段顺序与值顺序要一致
2:字符串和日期类型数据要包含在引号中
3:插入的数据要符合字段规定范)
2)修改记录:update
语法:update 表名 set 字段1=值1,字段2=值2 ,…[where 条件]
where条件可有 可无,无条件时同一字段被修改为相同内容。
3)删除记录:delete
语法:delete from 表名 [where条件](无条件会删除整张表)
示例:
#使用student数据库
USE student;
SHOW TABLES;
#创建新表score
CREATE TABLE IF NOT EXISTS score(
id CHAR(10),
NAME VARCHAR(25),
score TINYINT UNSIGNED);
#往表中添加一条记录:id 1111 name 张三 score 85---采用指定字段添加
INSERT INTO score(id,NAME,score) VALUES('1111','张三',85);
#往表中添加一条记录:id 2222 name 李四 score 95---采用全字段添加
INSERT INTO score VALUES('2222','李四',95);
#批量增加以下数据
/*3333 王五 65
4444 赵六 80
5555 周七 87*/
INSERT INTO score VALUES
('3333','王五',65),
('4444','赵六',80),
('5555','周七',87);
#查看表数据
SELECT * FROM score;
#删除id=1111的记录
delete from score where id='1111';
select * from score;
#不带条件删除---此时会清空整个表中的所有记录
delete from score;
show tables;
select * from score;
练习:
练习1:
数据

要求:
1)创建数据库:qing
2)在数据库中创建表:emperor
格式:
姓名 varchar(40);
庙号 varchar(20);
谥号 varchar(20);
登基 date;
逝世 date;
在位时间 tinyint unsigned;
3)插入表中给出的除年号以外的数据数据
#清朝皇帝列表
#创建数据库:qing
CREATE DATABASE IF NOT EXISTS qing;
USE qing;
#创建emperor表
CREATE TABLE emperor(
NAME VARCHAR(30),
templename VARCHAR(20),
nickname VARCHAR(20),
enthroned DATE,
die DATE,
in_time TINYINT UNSIGNED
);
#查看表结构
DESC emperor;
#数据插入
INSERT INTO emperor VALUES
('努尔哈赤','清太祖','高皇帝','1616-01-01','1626-01-01',10),
('皇太极','清太宗','文皇帝','1626-01-01','1636-01-01',10),
('福临','清世祖','章皇帝','1644-01-01','1661-01-01',17),
('玄烨','清圣祖','仁皇帝','1661-01-01','1722-01-01',61),
('胤禛','清世宗','宪皇帝','1722-01-01','1735-01-01',13),
('弘历','清高宗','纯皇帝','1736-01-01','1796-01-01',60),
('顒琰','清仁宗','睿皇帝','1796-01-01','1820-01-01',24),
('旻宁','清宣宗','成皇帝','1820-01-01','1850-01-01',30),
('奕詝','清文宗','显皇帝','1851-01-01','1861-01-01',10),
('载淳','清穆宗','毅皇帝','1861-01-01','1874-01-01',13),
('载湉','清德宗','景皇帝','1874-01-01','1908-01-01',24);
SELECT *FROM emperor;
4)添加年号字段
ALTER TABLE emperor ADD yearname VARCHAR(10);
SELECT *FROM emperor;
5)将图片数据填入对应位置
练习二:
(19条消息) MySQL 部门员工工资表 综合练习_数据库工资表_帆哥的小弟的博客-CSDN博客 https://blog.csdn.net/qq_49290616/article/details/114519968
https://blog.csdn.net/qq_49290616/article/details/114519968
函数
定义:
一段可以直接被另一段程序调用的代码或者程序。
分类:
字符串函数
数值函数
日期函数
流程函数
1)字符串函数
常见字符串函数

示例:
#函数:一段可以直接被另一段程序调用的程序或代码
#字符串函数
#字符串拼接concat(s1,s2,s3,...sn)
SELECT CONCAT('你好','数据库','!');
#字符串转小写:lower(str)
SELECT LOWER('MYSQL');
#字符串转大写:upper(str)
SELECT UPPER('mysql');
#左填充:lpad(str,n,pad):用pad对str左边进行填充直到str长度达到n
SELECT LPAD('01',5,'-');#用-填充使长度达到5
#右填充:lpad(str,n,pad):用pad对str右边进行填充直到str长度达到n
SELECT RPAD('01',8,'*')
#trim(str):去除str头尾的空格
SELECT TRIM(' he llo ');
#substring(str,start,len):截取从start开始len个字符的字串
SELECT SUBSTRING('iloveyou',2,8);2)数值函数
常用数值函数:

示例:
#数值函数
#向上取整:ceil(x)
SELECT CEIL(3.14);
SELECT CEIL(3.9);
#向下取整:floor(x)
SELECT FLOOR(3.14);
SELECT CEIL(3.9);
#mod(x,y):返回x/y的模
SELECT MOD(5,3);
SELECT MOD(3,5);
#rand()返回0-1内的随机数
SELECT RAND();
#round(x,y):求x的四舍五入值,保留y位小数
SELECT ROUND(3.14159,2);
SELECT ROUND(3.14159,2);3)日期函数

示例:
#日期函数
#返回当前日期:curdate()
SELECT CURDATE();
#返回当前时间:curtime()
SELECT CURTIME();
#返回当前的时间和日期:now()
SELECT NOW();
#获取指定date的年份:year(date)
SELECT YEAR('2023-03-02');
#获取指定date的月份:month(date)
SELECT MONTH('2023-03-02');
#获取指定date的日期:day(date)
SELECT DAY('2023-03-02');
#返回一个日期/时间加上一个时间间隔expr后的日期/时间:date_add(date,interval expr type)
SELECT DATE_ADD(NOW(),INTERVAL 70 DAY);#interval固定。具体数字位时间差值,type表示时间单位:year(年) month(月) day(天)
#返回时间date1和date2之间的天数:datediff(date1,date2)(date1-date2)
SELECT DATEDIFF(NOW(),'1999-06-13');4)流程函数
#流程控制函数
#if(value,t,f):value位true返回t,否则返回f
SELECT IF(TRUE,'ok','error'); #逻辑真和非0均表示true
SELECT IF(3=4,'ok','error');
SELECT IF(3,'ok','error');
SELECT IF(0,'ok','error');
SELECT IF(-1,'ok','error');
#ifnull(value1,value2):如果value1不为空返回1,否则返回2
SELECT IFNULL('hello','value1为空我出现');
SELECT IFNULL('','value1为空我出现'); #空格不代表null
SELECT IFNULL(NULL,'value1为空我出现');
#case when [value1] then [res1]...else [default] end:如果val1位true返回res1...否则返回default默认值
#case[expr]when[value1] then[res1]...else[default] end:如果expr值等于val1,返回res1。。。否则返回default默认值约束
概念:
作用于表中字段上的规则,用于限制存储在表中的数据。
目的:
保证数据库数据的正确,有效和完整性。
分类:

约束说明:
1)一个字段允许多个约束
2)主键递增,未申请到的主键值依然保持递增(AUTO_INCREMENT )
示例:
要求:
SELECT DATABASE();
SHOW DATABASES;
USE student;
SHOW TABLES;
#创建用户表user
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10) NOT NULL UNIQUE,
age INT CHECK (age >=0 && age <=120),
STATUS CHAR(1) DEFAULT '1',
gender CHAR
);
DESC USER;
#数据插入:主键数据库会自动维护,不用插入
INSERT INTO USER(NAME,age,STATUS,gender) VALUES
('张三丰',100,'1','男'),
('郭襄',95,'0','女');
SELECT *FROM USER;
INSERT INTO USER(NAME,age,STATUS,gender) VALUES
('张三丰',100,'1','男'); #再次插入会报错,违反唯一性
#主键递增
INSERT INTO USER(NAME,age,STATUS,gender) VALUES
('张翠山',40,'0','男'),
('殷素素',35,'0','女'),
('张无忌',26,'1','男'),
('赵敏',23,'1','女');
外键约束:用于两张表的数据之间建立连接,从而保证数据的一致性和完整性。
具有外键的表称为子表,被关联的表称为父表。
示例:
SHOW DATABASES;
USE student;
SHOW TABLES;
#创建部门表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(30) NOT NULL);
#插入信息
INSERT INTO dept(NAME)VALUES
('研发部'),('市场部'),
('财务部'),('销售部'),('总经办');
SELECT *FROM dept;
#创建员工表
CREATE TABLE IF NOT EXISTS emp(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(30) NOT NULL,
age INT ,
job VARCHAR(30) COMMENT '岗位',
salary INT ,
entrydate DATE,
managerid INT COMMENT '直属领导id',
dept_id INT COMMENT '部门id');
#添加数据
INSERT INTO emp(NAME,age,job,salary,entrydate,managerid,dept_id) VALUES
('张三丰',70,'董事长',20000,'1999-01-01',NULL,5),
('宋远桥',45,'总经理',15000,'1999-01-01',1,5),
('张翠山',35,'项目经理',8000,'1999-01-01',2,1),
('宋青书',22,'保安队长',4000,'1999-01-01',NULL,2),
('周芷若',21,'销售顾问',6600,'1999-01-01',3,3),
('赵敏',21,'销售顾问',7000,'1999-01-01',3,4),
('张无忌',70,'董事长',20000,'1999-01-01',NULL,2),
('小昭',70,'财务',20000,'1999-01-01',NULL,1),
('殷素素',70,'销售经理',20000,'1999-01-01',NULL,2),
('杨逍',50,'网络安全',11000,'1999-01-01',NULL,3),
('韦一笑',55,'业务员',10000,'1999-01-01',NULL,4),
('殷天正',60,'执行董事',18000,'1999-01-01',NULL,5);
SELECT * FROM emp;
#如果删除1号部门,1号部门的员工应该也要被删除,但未设置物理外键,故无法完成此操作
DELETE FROM dept WHERE id = 1;
SELECT *FROM dept;
#要保证完整性和数据一致性,需要添加外键
#创建表时添加外键:
#create table 表名(
#[constraint [外键名称] foreign key (外键字段名) references 主表(主表列名 )])
#往创建好的表添加外键
#alter table emp add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名)
#补充号好 信息
INSERT INTO dept(id,NAME) VALUES(1,'研发部');
SELECT * FROM dept;
#添加外键
ALTER TABLE emp ADD CONSTRAINT fk_emp_dept_id FOREIGN KEY(dept_id) REFERENCES dept(id);
#再次山删除dept中1号部门
DELETE FROM dept WHERE id =1;#会报错,不能删除
#删除外键
#alter table 表名 drop foreign key 外键名;
#删除外键:
ALTER TABLE emp DROP FOREIGN KEY fk_emp_dept_id;
#外键的删除和更新行为
删除/更新行为:
含有外键约束的表中,在进行数据更新或删除时数据库做出的反应。

#外键的删除和更新行为
#添加之前的外键fk_emp_dept_id并指定删除或更新行为设置为级联
ALTER TABLE emp ADD CONSTRAINT fk_emp_dept_id FOREIGN KEY(dept_id) REFERENCES dept(id) ON UPDATE CASCADE ON DELETE CASCADE;
#删除dept中id为1的
DELETE FROM dept WHERE id =1;
SELECT * FROM emp; #此时id为1的员工会全部被删除
#把dept中id为2的id改为id为8
UPDATE dept SET id =8 WHERE id =2; #此时id为2的员工dept——id为2的全部会改为8
#修改删除和更新行为
ALTER TABLE emp ADD CONSTRAINT fk_emp_dept_id FOREIGN KEY(dept_id) REFERENCES dept(id) ON UPDATE SET NULL ON DELETE SET NULL;
多表查询
多表关系:进行数据库表结构设计时,会根据业务需求及模块之间的关系设计表结构,表之间存在各种联系:基本为 以下三种
一对多(多对一)
例如:员工与部门 学生与学校
此时在多的一方建立外键,指向少的一方的主键。
多对多
例如:学生选课(学生表和课程表)
此时需要建立一张中间表,中间表至少包含两个外键,分别关联学生表和课程表的主键。
HOW TABLES;
#创建学生表
CREATE TABLE student(
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(20),
NO VARCHAR(10)
);
#数据插入
INSERT INTO student VALUES
(NULL,'黛绮丝','1111'),
(NULL,'殷天正','2222'),
(NULL,'谢逊','3333'),
(NULL,'韦一笑','4444');
SELECT * FROM student;
#创建课程表
CREATE TABLE course(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(15));
#插入数据
INSERT INTO course VALUES
(NULL,'乾坤大挪移'),
(NULL,'九阳神功'),
(NULL,'太极拳'),
(NULL,'九阴白骨爪'),
(NULL,'降龙十八掌');
SELECT * FROM course;
#创建中间表s_c:
CREATE TABLE s_c(
id INT AUTO_INCREMENT PRIMARY KEY,
s_id INT NOT NULL,
c_id INT NOT NULL,
CONSTRAINT fk_sid FOREIGN KEY (s_id) REFERENCES student(id),
CONSTRAINT fk_cid FOREIGN KEY (c_id) REFERENCES course(id)
);
#插入数据
INSERT INTO s_c VALUES
(NULL,1,1),
(NULL,1,2),
(NULL,2,1),
(NULL,2,3),
(NULL,3,1),
(NULL,4,2);
SELECT *FROM s_c;
一对一
例如:用户与用户信息。常用于单表拆分,将一张表的基础字段存放在一张表中,其他详情 字段存在另一张表中。
此时可以在任意一方添加一个外键关联另一方的主键,并且设置外键唯一(unique)
CREATE TABLE info_user(
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(10),
age INT ,
gender CHAR(1) COMMENT '1:男,2:女',
tel CHAR(11)
);
#创建用户教育信息表
CREATE TABLE user_edu(
id INT AUTO_INCREMENT PRIMARY KEY,
degree VARCHAR(10),
major VARCHAR(15),
midschool VARCHAR(15),
univer VARCHAR(15),
userid INT UNIQUE,
CONSTRAINT fk_u_info FOREIGN KEY (userid) REFERENCES info_user(id)
);
#插入数据
INSERT INTO info_user(id,NAME,age,gender,tel) VALUES
(NULL,'张无忌',22,'1',1111),
(NULL,'张三丰',72,'1',2222),
(NULL,'灭绝师太',50,'2',3333),
(NULL,'黄衫女',25,'2',4444);
SELECT * FROM info_user;
INSERT INTO user_edu(id,degree,major,midschool,univer,userid) VALUES
(NULL,'硕士','九阳神功','武当','明教',1),
(NULL,'教授','太极拳','武当','武当',2),
(NULL,'博士','灭绝剑法','峨眉','峨眉',3),
(NULL,'副教授','九阴白骨爪','古墓','古墓',4);
SELECT * FROM user_edu;
SHOW TABLES;多表查询
指从多张表中进行数据查找。
笛卡尔积:是指数学中不同集合相互组合的结果。多表查询时需要去除无效的笛卡尔积。
分类
连接查询
内连接:相当于查询AB交集部分
外连接
左外连接:查询左表所有数据以及两张表的交集数据
右外连接:查询右表所有数据以及两张表的交集数据
自连接:当前表与自身的连接查询,自连接必须使用别名
子查询
结果不同:
标量子查询(查询结果为单个值)
列子查询(查询结果为一列)
行子查询(查询结果为一行)
表子查询(查询结果为表)
位置不同
where以后
from之后
select以后
内连接
查询返回两张表的交集数据。
隐式内连接
select 字段列表 from 表1,表2 where 条件;
显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件;
外连接
左外连接
查询左表所有数据和两张表交集数据
select 字段列表 from 表1 left [outer] join 表2 on 条件;
右外连接
查询右表表所有数据和两张表交集数据
select 字段列表 fron 表2right [outer] join 表2 on 条件;
自连接
把同一张表看作两张表,起两个不同的别名。
select 字段列表 from 表a 别名a join 表a 别名b on 条件
可以是内连接也可为外连接。
联合查询
union查询。就是把多次查询的结果合并起来,形成一个新的查询结果集。
select 字段列表 from 表1 ......
union[all]
selcet 字段列表 from 表2......
(注意事项:
1,all去掉时会对合并结果去重
2,查询的表列数必须相同)
子查询
SQL语句中嵌套select语句,称为嵌套查询,有称为子查询。
标量子查询
事务
事物是一组操作的集合,他是一个不可分割的工作单位,事物会把所有的操作作为一个整体一起向系统提交或撤销操作请求。这些操作要么同时成功,要么同时失败。例如转账过程:检查账户余额--满足--余额减去转账 金额--到达账户账户金额增加。
执行事务前开启事务--过程出现异常--回滚事务--正常--事务提交。
mysql事务默认是自动提交的,即执行一条SQL语句,mysql会立即隐式提交事务。
示例:张三向李四转账1000元
数据准备:
USE qing;
CREATE TABLE account(
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(10),
money INT);
#数据添加
INSERT INTO account VALUES
(NULL,'张三',2000),(NULL,'李四',1000);
SELECT *FROM account;
查询张三余额:
SELECT *FROM account WHERE NAME='张三';满足条件后余额-1000
update account set money =money-1000 where name ='张三';李四余额+1000
update account set money =money+1000 where name ='李四';转账成功。
模拟异常
#假设余额满足条件
#张三账户-1000
update account set money=money-1000 where name='张三' ;
程序异常!
#李四账户+1000元
update account set money=money+1000 where name ='李四';此时因为语法错误,张三-1000,但李四+1000无法执行,造成错误!为避免类似的错误,我们需要控制事务。
事务操作
1)查看/设置事物的提交方式
mysql默认自动提交!
查看提交方式:select @@autocommit;
设置提交方式:set @@autocommit=0;(0表示手动,1表示自动)
设置为手动后,编辑好SQL语句后,键入commit后mysql才会真正提交事务。
事务开启
start transcation;
事务回滚
将事务提交方式设置为手动后。如果在执行过程中出现异常,需要事务回滚!
rollback;
#假设余额满足条件
#张三账户-1000
update account set money=money-1000 where name='张三' ;
程序异常!
#李四账户+1000元
update account set money=money+1000 where name ='李四';
rollback;#账户余额仍为各自2000元事务提交
commit;
流程:开启事务---------出现异常--------回滚事务------一切正常------提交事务
总结:事务控制有两种方式
方式1:修改mysql的提交方式为手动:set @@autocommit=0;
执行sql语句,一切正常提交事务:commit出现异常回滚事务:rollback;
(键入commit后数据库中的数据才会真正执行相应操作)
# 事务控制演示 #方式1 #1)修改提交方式为手动 SET @@autocommit=0; SELECT @@autocommit; #数据准备 USE qing; CREATE TABLE account( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10), money INT); INSERT INTO account VALUES (NULL,'张三',2000), (NULL,'李四',2000); SELECT * FROM account; UPDATE account SET money=2000; #修改张三余额-1000.李四+1000 UPDATE account SET money=money-1000 WHERE NAME='张三'; UPDATE account SET money=money+1000 WHERE NAME='李四'; COMMIT #出现错误 UPDATE account SET money=money-1000 WHERE NAME='张三'; 出现异常 UPDATE account SET money=money+1000 WHERE NAME='李四'; ROLLBACK;#回滚以后会正确执行sql语句
方式2:开启事务:start transaction 或者 begin
执行sql
一切正常:commit
出现异常:rollback
#设置成默认的提交方式
SET autocommit=1;
#恢复初始金额
UPDATE account SET money=2000;
SELECT * FROM account;
#开启事务
BEGIN;
#余额更新
UPDATE account SET money=money-1000 WHERE NAME='张三';
UPDATE account SET money=money+1000 WHERE NAME='李四';
#正常执行时会正确提交
#出现异常时
#恢复初始金额
UPDATE account SET money=2000;
SELECT * FROM account;
BEGIN;
#余额更新
UPDATE account SET money=money-1000 WHERE NAME='张三';
出现异常
UPDATE account SET money=money+1000 WHERE NAME='李四';
#此时出现错误,需要回滚,数据恢复初始状态
ROLLBACK;
SELECT * FROM account;
事务的特性(ACID)
共有四个特性:
原子性:事务是不可分割的操作单元,这些操作要么同时成功,要么同时失败。
一致性:事务完成时,必须使所有数据都保持一致状态
隔离性:依赖数据库隔离机制,事务之间相互独立,不受其他的事务影响
持久性:事务一旦提交或者回滚,对数据库中的数据影响是永久的。
并发事务问题:
多个并发事务运行时可能出现的问题。
脏读
一个事务读取到另一个事务还未提交的数据。
不可重复读
一个事务先后读取同一记录,但两次读取的速度不同。
幻读
一个事务按照条件查询数据时,没有对应的数据,但在插入数据时,这行数据又存在, 好像出现了幻影。
事务隔离级别:
为了解决并发事务问题。
分类:
read uncommitted
Oracle默认的隔离级别.。读未提交。脏读,幻读,不可重复读三种问题均可能出现。
read committed
可重复度。解决了脏读问题。
repeatable read
mysql默认隔离级别。解决了脏读和不可重复读。
serializable
串行化,三种问题均可以解决。(性能低,安全级别高)
1,查看事务隔离级别:
select @@transaction——isolation
2,设置隔离级别
set [session| global] transaction level{read uncommitted|read committed|repeatable read | seralizable}
(session表示只在当前会话生效,global表示所有地方可生效)
演示:
查看和设置隔离级别
#查看隔离级别
SELECT @@transaction_isolation;
#设置隔离级别为读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT @@transaction_isolation;
#设置为默认值
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;隔离级别演示:
1)脏读
account表:初始数据均为两千。
只可能在隔离级别为read unconmmitted时出现读脏数据。
1)打开两个命令行窗口分别登录mysql

2)将左边隔离级别修改为read uncommitted

3)在右边开启事务,并修改acoount表账户余额:张三-1000元
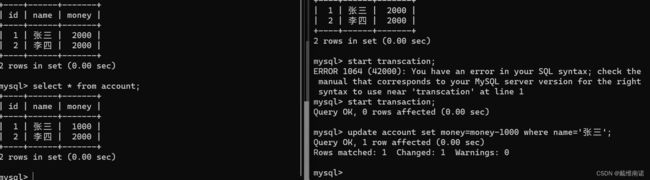 可以看到,此时右边还未提交事务,但此时左边的客户端却能读取到数据。
可以看到,此时右边还未提交事务,但此时左边的客户端却能读取到数据。
再次验证:
隔离级别为:read committed可以解决读脏数据问题:
1)恢复accout表数据均为初始2000元
2)再次打开两个命令行窗口

2)设置左边的隔离级别为read committed。在右边开启事务,并执行余额修改张三-1000
 可以看到,右边未提交前访问不到数据。
可以看到,右边未提交前访问不到数据。
3)右边键入提交
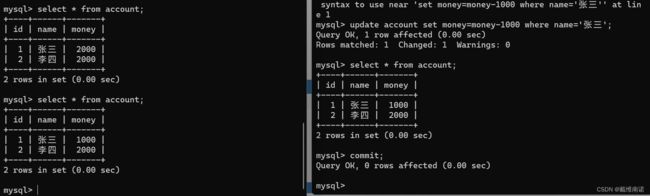
验证成功!
进阶篇
存储引擎
mysql体系结构

连接层
负责客户端与数据库连接,包含密码校验,授权认证和等。
服务层
核心功能层,SQL接口,缓存查询,SQL分析和优化等,部分内置函数的执行。
引擎层
真正负责没有MySQL中的数据存储和提取,服务器通过API与存储引擎通信
存储层
负责与存储引擎交互和将 数据存储于磁盘
存储引擎简介
存储数据,建立索引,更新,查询数据等技术的实现方式。存储引擎是基于表的。mysql5.5以后默认为innoDB引擎。存储引擎 也称 为表的类型
查看引擎类型:

查看引擎类型和支持类型:
show engines;

创建表时可以指定存储引擎:
存储引擎特点
1)innoDB:
高可靠和高性能。5.5以后系统默认的存储类型
DML操作遵循ACID模型,支持事务
行级锁,提高并发访问性能
支持外键
磁盘文件:每一个innoDB的表都对应一个.ibd文件。用于存储该表的结构(frm,sdi)数据和索引等。(8以后存在sdi中,sdi融入在 idb中)
参数innoDB_file_per_table:决定每一张表是对应一个idb文件还是公用一个表空间。当前mysql默认参数是打开的。
查看磁盘文件:

查看ibd文件
打开cmd窗口:ibdsdi 具体的ibd文件

存储引擎选择
索引
Sql优化
视图/存储过程/触发器
锁
innoDB引擎
mysql管理