python和selenium爬虫,网页表格下载自动化脚本
一、selenium是啥
- 框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
- 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
- 使用简单,可使用Java,Python等多种语言编写用例脚本。
二、selenium的安装
1、在python中安装selenium 命令:pip install selenium
![]()
安装成功:
2、使用谷歌浏览器,在谷歌浏览器的设置中查询自己的谷歌浏览器的版本:设置→关于

3、下载谷歌浏览器驱动
下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver/
找到符合版本号的驱动文件夹
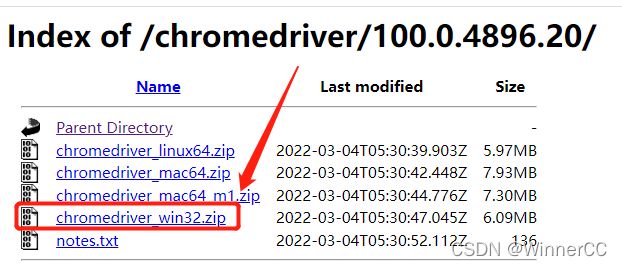
选择适合你电脑的驱动版本,window下载win32的就好了
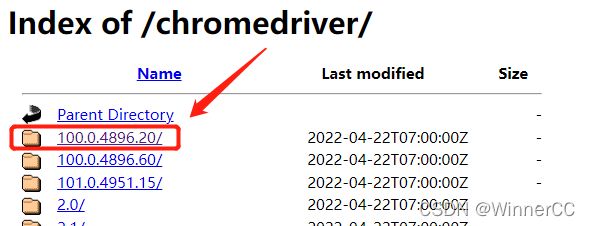
下载之后,将解压的文件放在python的目录中

三、使用selenium写自动化网页操作脚本
1、import要用到的包
import time
import os
import shutil
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
咱也分不清这些包具体哪个是干嘛的,但是在程序里都用上了
2、selenium使用
思路:由于selenium自动化脚本是模拟人的操作,所以程序就按照你对这个网站进行操作的顺序写
2.1打开谷歌浏览器、窗口最大化
driver = webdriver.Chrome()
driver.maximize_window()
2.2输入网址
driver.get("你要让程序进入的网址")
2.3selenium的定位
selenium的定位到某一个网页上的元素(输入框、按钮等)的方法共有八种,具体是哪八种可以百度,这里只介绍我用到最方便的一种(XPATH定位)。举个例子。
在网页中按F12,显示网页源码。点击定位器

再在网页上点击这个元素,源码中就会标出,比如我点击百度的输入框,这个输入框的代码的就会被标蓝色


右键标蓝代码→Copy→Copy XPath

这个时候你就复制了这个元素的xpath了,可以在程序中使用
比如:我要在登录页面输入账号和密码,然后点击登录按钮
driver.find_element(by=By.XPATH, value="你复制的账号输入框的XPath").send_keys("你的账号")
driver.find_element(by=By.XPATH, value="你复制的密码输入框的XPath").send_keys("你的密码")
driver.find_element(by=By.XPATH, value="你复制的登录按钮的XPath").click()
2.4selenium获取某一元素的文本,比如标签或者按钮上的文字
这个可以用于下载的数据表格文件的命名,否则下载的文件很可能是乱命名的,不便于我们的使用。
my_text = driver.find_element(by=By.XPATH, value="该元素的XPath").text
2.5selenium回到页面顶部或者拉到页面底部
我在程序中遇到某一页面滚动条被滑到底部之后,脚本中点击页面顶部的某个按钮就报错了,所以我思考需要将页面先滑回到顶部。(按钮点击无效有很多种情况,比如也可能是按钮被某些弹窗覆盖导致定位不到,百度多几种方法试试应该能解决)
#滑到底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
#滑到顶部
driver.execute_script("var q=document.documentElement.scrollTop=0")
2.6selenium的等待页面加载
selenium的等待有三种,①傻瓜等待,sleep(3),这样就可以等待3秒。②隐式等待,设置一个时间上限,在这个时间内,当整个页面加载完成的时候或者达到时间上限的时候,退出等待(具体想了解的话可以百度)③显式等待(显示等待),我们往往不需要等到整个页面加载完,加载出我们所需要的数据就可以了
以下代码表示:时间上限1000s,在这个时间中,每0.5秒检查一次tag1的这个元素有没有加载出来,我的程序中定位的是数据表格底部的页码按钮,因为这按钮出来了就表示我要的表格中的数据都加载出来了,当这个元素被加载出来或者是到达1000s上限的时候,就停止等待了。
tag1 = (By.XPATH, "加载出的元素的xpath") #当这个元素加载出来的时候,就停止等待了
try:
WebDriverWait(driver, 1000, 0.5).until(EC.presence_of_element_located(tag1))
except:
print("量表字段加载失败")
break
3、判断文件是否下载完成、整理下载的文件
-
这里使用查看文件夹中文件列表的方法判断文件是否下载完成,我爬的就是csv文件,所以这样做是没问题的。如果是其他的有可能遇到文件夹中出现系统文件或者临时文件,要通过限定文件后缀之类的方法排除。
-
这里是设置了20s内每0.5秒检查一次,如果发现文件夹中文件已经存在,就停止等待和检查。
-
将下载的文件**重命名并整理(复制)**到新的文件夹中,我的命名是在网页中通过.text获得的信息(往上看2.4中)
-
文件整理到新的文件夹中之后,删除os.remove下载文件夹中的这一个文件,以免跟下一个下载的文件混淆
def find_file(path, all_files,liangbiao):
file_list = os.listdir(path)
seconds = 0
dl_wait = True
while dl_wait and seconds < 20:
if file_list == []:
time.sleep(0.5)
seconds += 0.5
file_list = os.listdir(path)
else:
dl_wait = False
for file in file_list:
full_path = os.path.join(path, file)
file_name = os.path.basename(full_path)
new_dir = sort_path + liangbiao
new_path = new_dir + '//' + liangbiao + '.csv'
if os.path.exists(new_path):
print("该文件夹已存在,无法创建!")
else:
print("下载路径:{}".format(full_path))
print("整理路径:{}".format(new_path))
os.mkdir(new_dir)
shutil.copyfile(full_path, new_path)
os.remove(full_path)
4、完整代码
import time
import os
import shutil
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
folder_path = "C://Users//Winner//Downloads"
sort_path = "D://Desktop//update//"
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("我的数据网站登录页面网址")
print(driver.current_url)
print(driver.title)
driver.find_element(by=By.NAME, value="username").send_keys("我的账号")
driver.find_element(by=By.NAME, value="password").send_keys("我的密码")
driver.find_element(by=By.NAME, value="login").click()
def find_file(path, all_files,liangbiao):
file_list = os.listdir(path)
seconds = 0
dl_wait = True
while dl_wait and seconds < 20:
if file_list == []:
time.sleep(0.5)
seconds += 0.5
file_list = os.listdir(path)
else:
dl_wait = False
for file in file_list:
full_path = os.path.join(path, file)
file_name = os.path.basename(full_path)
new_dir = sort_path + liangbiao
new_path = new_dir + '//' + liangbiao + '.csv'
if os.path.exists(new_path):
print("该文件夹已存在,无法创建!")
else:
print("下载路径:{}".format(full_path))
print("整理路径:{}".format(new_path))
os.mkdir(new_dir)
shutil.copyfile(full_path, new_path)
os.remove(full_path)
for i in range(16, 150):
num = i+1
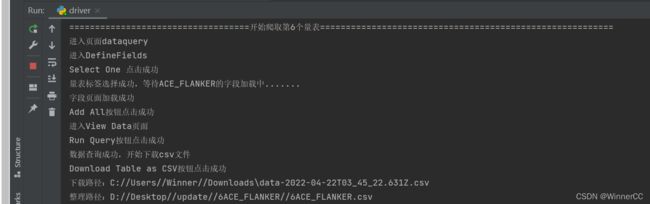
print("===================================开始爬取第%s个量表=========================================================" % i)
xpath1 = ("//*[@id='DefineFields']/div/div[3]/div[1]/div/div/ul/li[%s]/div/label" % num)
driver.get("https://data.healthybrainnetwork.org/dataquery/")
print("进入页面dataquery")
driver.find_element(by=By.XPATH, value="//*[@id='reactTest']/div/div[2]/nav/ul[1]/li[2]").click()
print("进入DefineFields")
driver.find_element(by=By.XPATH, value="//*[@id='DefineFields']/div/div[3]/div[1]/div/div/button").click()
print("Select One 点击成功")
liangbiao = driver.find_element(by=By.XPATH, value=xpath1).text
liangbiao_i = str(i) + liangbiao
driver.find_element(by=By.XPATH, value=xpath1).click()
print("量表标签选择成功,等待{}的字段加载中.......".format(liangbiao))
tag1 = (By.XPATH, "//*[@id='DefineFields']/div/div[4]/div/ul")
try:
WebDriverWait(driver, 1000, 0.5).until(EC.presence_of_element_located(tag1))
except:
print("量表字段加载失败")
break
print("字段页面加载成功")
try:
driver.execute_script("var q=document.documentElement.scrollTop=0")
except:
print("滚动到页面顶部失败")
driver.find_element(by=By.XPATH, value="//*[@id='DefineFields']/div/div[2]/div/button[1]").click()
print("Add All按钮点击成功")
driver.find_element(by=By.XPATH, value="/html/body/div[1]/div/div/div[2]/div/div/div/div[2]/nav/ul[1]/li[4]").click()
print("进入View Data页面")
driver.find_element(by=By.XPATH, value="//*[@id='ViewData']/div[1]/div[1]/button").click()
print("Run Query按钮点击成功")
tag = (By.XPATH, "//*[@id='ViewData']/div[3]/div[3]/div/div/div[2]/button")
try:
WebDriverWait(driver, 1000, 0.5).until(EC.presence_of_element_located(tag))
except:
print("数据查询失败")
break
print("数据查询成功,开始下载csv文件")
driver.find_element(by=By.XPATH, value="//*[@id='ViewData']/div[3]/div[3]/div/div/div[2]/button").click()
print("Download Table as CSV按钮点击成功")
#对下载的文件进行整理归档
contents_list = find_file(path=folder_path, all_files=[],liangbiao = liangbiao_i)