机器学习模型部署PMML
PMML 简介
预测模型标记语言PMML(Predictive Model Markup Language)是一套与平台和环境无关的模型表示语言,是目前表示机器学习模型的实际标准。从2001年发布的PMML1.1,到2019年最新4.4,PMML标准已经由最初的6个模型扩展到了17个模型,并且提供了挖掘模型(Mining Model)来组合多模型。
PMML 标准介绍
PMML是一套基于XML的标准,通过 XML Schema 定义了使用的元素和属性,主要由以下核心部分组成:
- 数据字典(Data Dictionary),描述输入数据。
- 数据转换(Transformation Dictionary和Local Transformations),应用在输入数据字段上生成新的派生字段。
- 模型定义 (Model),每种模型类型有自己的定义。
- 输出(Output),指定模型输出结果。
PMML预测过程符合数据挖掘分析流程:
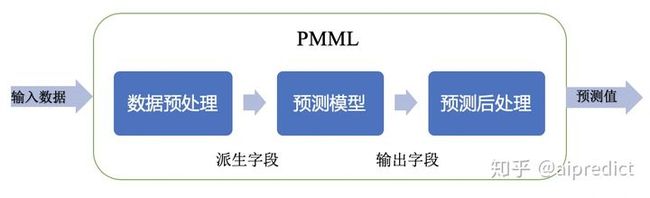
PMML 优点
- 平台无关性。PMML可以让模型部署环境脱离开发环境,实现跨平台部署,是PMML区别于其他模型部署方法最大的优点。比如使用Python建立的模型,导出PMML后可以部署在Java生产环境中。
- 互操作性。这就是标准协议的最大优势,实现了兼容PMML的预测程序可以读取其他应用导出的标准PMML模型。
- 广泛支持性。已取得30余家厂商和开源项目的支持,通过已有的多个开源库,很多重量级流行的开源数据挖掘模型都可以转换成PMML。
- 可读性。PMML模型是一个基于XML的文本文件,使用任意的文本编辑器就可以打开并查看文件内容,比二进制序列化文件更安全可靠。
PMML开源类库
模型转换库,生成PMML:
*Python模型:*
- Nyoka,支持Scikit-Learn,LightGBM,XGBoost,Statsmodels和Keras。nyoka-pmml/nyoka
- JPMML系列,比如JPMML-SkLearn、JPMML-XGBoost、JPMML-LightGBM等,提供命令行程序导出模型到PMML。Java PMML API
- sklearn2pmml ,用于将Scikit学习管道转换为PMML的Python库。这个库是JPMML-SkLearn命令行应用程序的一个瘦包装。有关支持的评估器和转换器类型的列表
*R模型:*
- R pmml包:CRAN - Package pmml
- r2pmml:jpmml/r2pmml
- JPMML-R:提供命令行程序导出R模型到PMML。jpmml/jpmml-r
*Spark:*
- Spark mllib,但是只是模型本身,不支持Pipelines,不推荐使用。
- JPMML-SparkML,支持Spark ML pipleines。jpmml/jpmml-sparkml
使用案例
把机器学习模型转换成PMML格式进行存储和部署
方式一使用Nyoka,把Pipeline导出PMML:
from nyoka import xgboost_to_pmml
xgboost_to_pmml(pipeline, features, target, "xgb-iris.pmml")
- Nyoka 库没有装成功,该方法没有尝试
方法二: 使用sklearn2pmml
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
from xgboost import XGBClassifier
import sklearn2pmml
seed = 123456
iris = datasets.load_iris()
target = 'Species'
features = iris.feature_names
iris_df = pd.DataFrame(iris.data, columns=features)
iris_df[target] = iris.target
X, y = iris_df[features], iris_df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=seed)
pipeline = Pipeline([
('scaling', StandardScaler()),
('xgb', XGBClassifier(n_estimators=5, seed=seed))
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
y_pred_proba = pipeline.predict_proba(X_test)
# 2. 使用sklearn2pmml,把Pipeline导出PMML:
sklearn2pmml(pipeline,"xgb-iris.pmml")
#xgboost_to_pmml(pipeline, features, target, "xgb-iris.pmml")
# 3. 使用PyPMML来验证PMML预测值是否和原生Python模型一致:
from pypmml import Model
model = Model.load("xgb-iris.pmml")
model.predict(X_test)
报错:

调整:
将pipeline 环节中sklearn中的pipeline 使用sklearn2pmml 的PMMLPipeline
https://cloud.tencent.com/developer/article/1693633
from sklearn import datasets
from sklearn.model_selection import train_test_split
#from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
from xgboost import XGBClassifier
from sklearn2pmml import sklearn2pmml, PMMLPipeline
import warnings
seed = 123456
iris = datasets.load_iris()
target = 'Species'
features = iris.feature_names
iris_df = pd.DataFrame(iris.data, columns=features)
iris_df[target] = iris.target
X, y = iris_df[features], iris_df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=seed)
pipeline = PMMLPipeline([
('scaling', StandardScaler()),
('xgb', XGBClassifier(n_estimators=5, seed=seed))
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
y_pred_proba = pipeline.predict_proba(X_test)
# 2. 使用sklearn2pmml,把Pipeline导出PMML:
sklearn2pmml(pipeline,"xgb-iris.pmml")
#xgboost_to_pmml(pipeline, features, target, "xgb-iris.pmml")
# 3. 使用PyPMML来验证PMML预测值是否和原生Python模型一致:
from pypmml import Model
model = Model.load("xgb-iris.pmml")
model.predict(X_test)
PMML 深度解析
pmml是XML 格式,PMML 文件的结构遵从了用于构建预测解决方案的常用步骤,包括:
数据词典,这是一种数据分析阶段的产品,可以识别和定义哪些输入数据字段对于解决眼前的问题是最有用的。这可以包括数值、顺序和分类字段。
挖掘架构,定义了处理缺少值和离群值的策略。这非常有用,因为通常情况,当将模型应用于实践时,所需的输入数据字段可能为空或者被误呈现。
数据转换,定义了将原始输入数据预处理至派生字段所需的计算。派生字段(有时也称为特征检测器)对输入字段进行合并或修改,以获取更多相关信息。例如,为了预测停车所需的制动压力,一个预测模型可能将室外温度和水的存在(是否在下雨?)作为原始数据。派生字段可能会将这两个字段结合起来,以探测路上是否结冰。然后结冰字段被作为模型的直接输入来预测停车所需的制动压力。
**模型定义,**定义了用于构建模型的结构和参数。PMML 涵盖了多种统计技术。例如,为了呈现一个神经网络,它定义了所有的神经层和神经元之间的连接权重。对于一个决策树来说,它定义了所有树节点及简单和复合谓语。
输出定义了预期模型输出。对于一个分类任务来说,输出可以包括预测类及与所有可能类相关的概率。
目标,定义了应用于模型输出的后处理步骤。对于一个回归任务来说,此步骤支持将输出转变为人们很容易就可以理解的分数(预测结果)。
模型解释,定义了将测试数据传递至模型时获得的性能度量标准(与训练数据相对)。这些度量标准包括字段相关性、混淆矩阵、增益图及接收者操作特征(ROC)曲线图。
**模型验证,**定义了一个包含输入数据记录和预期模型输出的示例集。这是非常重要的一个步骤,因为在应用程序之间移动模型时,该模型需要通过匹配测试。这样就可以确保,在呈现相同的输入时,新系统可以生成与旧系统同样的输出。如果实际情况是这样的话,一个模型将被认为经过了验证,且随时可用于实践。
参考
- 来源: 知乎 https://zhuanlan.zhihu.com/p/82451594
- [Python之sklearn2pmml:sklearn2pmml库函数的简介、安装、使用方法之详细攻略daiding-云社区-华为云 (huaweicloud.com)]
- [机器学习模型部署—PMML - 云+社区 - 腾讯云 (tencent.com)]
- https://blog.csdn.net/taoy86/article/details/89955901 PMML讲解及使用
将将,一只努力进步的程序媛!
日积跬步,不远千里!