论文阅读 - A Large-Scale Longitudinal Multimodal Dataset of State-Backed Information Operations on Twitt
Proceedings of the Sixteenth International AAAI Conference on Web and Social Media (ICWSM 2022) CCF-B
目录
引言
Data Access
Data Collection
State-Backed Data (Positive Set)
Background Data (Negative Set)
Filtering Tweets
Data Exploration
Structure of User and Tweet Data
Tweet-Level and User-Level Analysis
Limitations
Data Bias
Primary Data Errors
Recommendations for Usage
Conclusion
本文提出了一个由 28 个子数据集组成的大规模综合数据集,其中包括国家支持的推文和与 14 个不同国家有关的账户,时间跨度超过 3 年(从 2015 年到 2018 年),以及相应的 "负面 "数据集,其中包括同一时期类似主题的背景推文。据我们所知,这是第一个同时包含国家支持的宣传推文和精心收集的相应负面推文数据集的数据集,涉及如此多的国家,时间跨度如此之长。
引言
宣传是一种传播形式,它试图通过有选择地陈述事实来鼓励特定的综合或感知,或使用客观语言来唤起受众的感性而非理性反应,从而达到推进宣传者预期意图的效果(乔维特和奥唐纳,2018 年)。国家支持的宣传是危害最大的网络宣传类型之一。这是因为考虑到国家支持的宣传者拥有大量资源,国家可以通过在社交媒体上发布信息来左右公众舆论(费舍尔,2020 年)。
为了检测社交媒体上国家资助的宣传并尽量减少其有害影响,过去几年进行了大量研究,例如分析宣传的传播(Zannettou 等人,2019b;Badawy 等人,2019)、分析用户特征国家支持的巨魔(Zannettou 等,2019a;Badawy、Lerman 和 Ferrara,2019;Volkova 等,2017)并识别国家支持的宣传巨魔(Luceri、Giordano 和 Ferrara,2020;Miao、Last 和 Litvak,2020; Orlov 和 Litvak 2018)或社交媒体上的内容(Guo 和 Vosoughi 2020)。
虽然这些作品解决了各种引人注目的研究问题,但它们都需要带有注释的推文或 Twitter 用户数据集作为输入。不幸的是,覆盖多个国家的正类(国家资助)和负类(非国家资助)数据的高质量注释数据集是一种稀有商品,尽管对于改进和可靠地衡量模型性能至关重要。
我们创建了两个有关国家在社交媒体上进行宣传的数据集,并公开提供给研究人员使用。这些数据集一个由 Twitter 数据2 组成,另一个由 Reddit 数据3 组成,涵盖不同国家和主题。不过,这两个数据集都只包括国家支持的账户,而没有 "正常"(非国家支持)账户的负类数据集。没有负类数据集意味着这些数据集只能用于分析来自不同组织的帖子之间的差异,而不能用于识别国家赞助的帖子。为了解决这个问题,其他作品在用户或帖子层面建立了自己的负类数据集。
有些人通过将用户与特定因素(如平均每天发布的推文数量的分布(Zannettou 等人,2019a)以及语言和地点的组合(Alhazbi,2020))联系起来,建立了用户层面的基线数据。Badawy 等人(Badawy, Lerman, and Ferrara 2019)使用与 2016 年美国大选各主要总统候选人相关的特定标签和关键词来筛选用户。然而,所有这些研究都忽略了用户的话题偏好,这可能会导致分析或预测建模出现偏差,因为话题信息会出现信息泄露。其他研究人员(Broniatowski 等人,2020 年;Guo 和 Vosoughi,2020 年;Volkova 等人,2017 年;Chang 等人,2021 年;Orlov 和 Litvak,2018 年)通过在帖子级别建立基线数据,确保负类和正类推文都包含相似的标签和关键词,从而克服了这一问题。虽然这些研究部分解决了话题分布的问题,但它们只关注有限的话题或国家,这限制了这些数据集的使用。
因此,我们提出了一个原创的、大规模的综合数据集,重点关注 Twitter 上国家支持的宣传。与之前的工作相比,我们的数据集由于数据采样的偏差较小、主题相似性、正类和负类推文的时间一致性,以及涵盖多个国家(14 个)和多种语言的事实,确保了使用该数据集的模型和分析具有更强的鲁棒性和通用性。负类推文数据集包含 67 种不同的语言,使用频率最高的前 3 种语言分别是英语(33.73%)、阿拉伯语(29.14%)和西班牙语(6.94%)。正类推文数据集包括 61 种不同语言,使用频率最高的前 3 种语言分别是阿拉伯语(30.16%)、西班牙语(16.19%)和英语(12.82%)。 该数据集的主要特点如下
覆盖 14 个国家的 28 个不同子数据集。
22,850 个国家支持的账户和 667,803 个 "正常 "账户的 ID 和元数据。
10,189,437 条纯文字正面(即宣传)推文和 2,575,521 条带图片正类推文的 ID 和元数据。
1,144,614 条纯文字负类(即非宣传性)推文和 202,732 条带图片负类推文的 ID 和元数据
Data Access
Our dataset is hosted by Harvard Dataverse with the following link: https://doi.org/10.7910/DVN/NO3I34.
Data Collection
我们的数据集由正类数据和负类数据组成,正类数据是指与国家支持的组织有关联的账户发布的推文(以及相应的账户信息),负类数据是指背景用户发布的推文(以及相应的账户信息)。我们利用标签来筛选推文,以确保正类和负类推文的主题相似。
State-Backed Data (Positive Set)
正类数据来自 Twitter 有关信息操作的透明度报告4 。Twitter 的原始数据包括推文信息、用户信息和来源国。在我们的数据集中,我们将来自同一国家不同时期的档案视为不同的子数据集,因为它们是由 Twitter 分别识别的。28 个子数据集的详情见表 1。
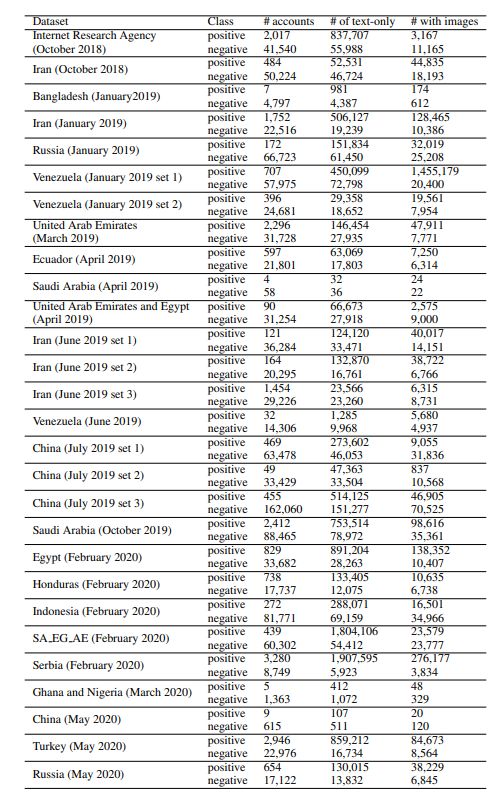
(表 1: 数据集的详细信息,包括每个子数据集的正类和负类数据的账户数(账户数 #)、纯文字推文数(纯文字推文数 #)和带图片推文数(带图片推文数 #)。 数据集的日期与发布时间一致。SA EG AE(2020 年 2 月)包括来自 Twitter 三个中东国家(沙特阿拉伯、埃及和阿拉伯联合酋长国)的推文。)
Background Data (Negative Set)
背景数据来自 Internet Archive 的 Twitter Stream Grab,这是一个从 Twitter 主流中抓取推文的简单集合。Twitter Stream Grab 利用 Twitter 提供的流 API 随机抽取 1%的实时推文。由于我们的工作数据集主要涉及国家支持的宣传内容与背景推文的差异,因此背景数据中任何包含与国家支持的宣传相同的文字或图片的推文都会被删除。
Filtering Tweets
对于正向和负向数据,我们只保留 2015 年 3 月至 2018 年 12 月期间的推文(2017 年 12 月除外,因为互联网档案馆没有 2017 年 12 月的数据可用于负向集)。仅包含 URL、转推标记('RT')或提及标记('@')(无其他内容)的推文将被删除。 为确保每个子数据集中每个月的正面推文和负面推文的主题相似,我们按月根据重要标签对推文进行筛选。每条推文的每个标签的重要性为 1 除以该条推文的标签数。然后,我们将一个月内所有推文的每个标签的重要性相加,计算出标签的月重要性,并生成当月最重要的 15 个标签(有时由于当月缺乏活动,数量会少于 15 个)。在提取出 15 个最重要的标签后,我们会从正负集中删除当月所有不包含这些标签的推文。这样可以确保正反两方面的推文一般都是关于同一主题的(就标签捕捉主题而言)。
为了确保负面推文不同于正面推文,我们依靠文本和图片来筛选负类推文。为了比较文本内容,我们对推文文本进行了处理,将文本中的 URL 替换为 "URL",删除了转推标记("RT")和提及信息(提及标记、"@"和提及的用户)。为了比较图片,我们使用了 dHash(侧重于图片梯度的方法6)为每张图片生成哈希值。 对于每条负类推文,如果其处理过的文本或图片的哈希值与任何正面推文相同,就会被删除。这样可以确保负面集和正面集的内容不完全相同,这对于训练基于内容的宣传检测模型非常重要。
我们还检查了负类用户集中被暂停或删除的用户数量。负面账户中的用户总数为 667,803 个,其中 92,649 个被 Twitter 暂停,75,125 个被删除。 需要注意的是,这些用户并未被推特认定为国家支持的宣传者账户,可能是由于其他原因被删除的。
Data Exploration
在本节中,我们将首先介绍数据集的结构和规模。然后,我们进行推文级和用户级分析,初步探讨正类数据和负类数据之间的差异。
Structure of User and Tweet Data
我们的数据集包括推文和与推文相对应的用户。所有数据均为 JSON 格式,为方便起见,我们在此以表格形式呈现。 表 2 显示了数据集中的一条推文示例。我们的数据集包括推文 ID(推文 ID)、用户 ID(用户 ID)、推文所属子数据集(子数据集)、数据类别(类别)、用户显示名称(名称)、推文发布时间(推文时间)、用户当时的首选语言(账户语言)、 推文语言(tweet lang)、引用赞数(# of likes)、转发数(# of retweets)、标签列表(hashtags)、被提及用户列表(mentions)、URL 列表(urls)、图片名称列表(images)和图片哈希值列表(image hashes)。对于正类推文,用户 ID 和显示名称由 Twitter 进行哈希处理。

表 3 显示了我们数据集中的一个用户示例。 我们的数据集包括用户 ID(id)、网名(name)、用户所属子数据集(sub-dataset)、用户类别(class)、报告地点列表(location)、用户创建日期(creation date)、用户偏好语言列表(lang)、 时间段内的关注者数量范围(最小关注者数量和最大关注者数量)、时间段内的好友数量范围(最小好友数量和最大好友数量)、超过时间的简介描述列表(简介)以及从 2018 年 12 月 31 日开始倒推计算的用户年龄(年龄(天数))。负面用户的id是真实的,而正面用户的id则由 Twitter 哈希。对于位置、语言和简介描述数据,使用列表格式来表示时间段内的所有数据。由于关注者和好友的数量在时间段内可能会发生变化,我们使用 "min "和 "max "来表示关注者和好友的最小数量和最大数量。

Tweet-Level and User-Level Analysis
我们对所有数据进行了逻辑回归分析,初步分析了推文级特征在区分国家支持和背景推文方面的重要性。我们分析的因变量是一条推文是国家支持还是背景的二元指标。 模型中的自变量是以下推文特征: "子数据集"、"#提及"、"#标签"、"长度"、"有图片"、"有 URL "和 "语言相同"("推文语言 "和 "账户语言 "是否相同)。请注意,由于 "子数据集 "是分类变量,因此用 28 个二元虚拟变量来表示。. 我们不包括 "点赞数 "和 "转发数",因为它们会导致 "奇异矩阵 "误差,因为绝大多数推文的点赞数和转发数都为 0。
表 4 显示了逻辑回归中每个特征的效果(系数)和统计意义。 逻辑回归的伪 R 方为 0.2151。 我们可以发现,所有这些特征都能在一定程度上预测一条推文是否由国家支持(如表 4 所示,所有特征都具有统计意义)。请注意,这只是初步分析,没有考虑可能的混杂变量。要更好地理解每个特征的效果,还需要更详细的分析。为简洁起见,我们没有在表中显示 28 个 "子数据集 "虚拟变量。
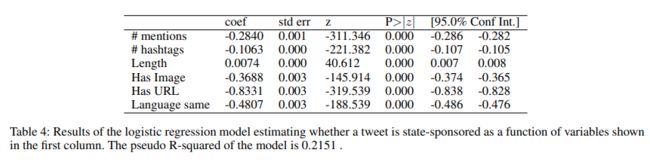
(表4:第一列所示变量对推文是否为国家赞助的logistic回归模型的函数估计结果。模型的伪r平方为0.2151。)
对国家资助账户和背景账户之间的用户层面差异进行的相同分析表明,用户账户年龄是唯一重要的特征。 用户账户年龄的计算方法是账户创建日期与 2018 年 12 月 31 日(即我们数据集的结束日期)之间的天数。就大多数子数据集而言,我们观察到,除了中国(2019 年 7 月第 2 组)、中国(2019 年 7 月第 3 组)、厄瓜多尔(2019 年 4 月)和俄罗斯(2020 年 5 月)之外,负类数据集中用户的平均年龄大于正面数据集中用户的平均年龄。我们还观察到,在大多数子数据集中,正类数据集中用户的平均年龄不到 4 岁。综合来看,这两个现象表明,正类数据集中的大多数用户账户都相对年轻,而且似乎是为特定目的(即推动某个议程)而创建的。 图 1 显示了正类和负类账户的年龄分布。我们可以发现,正类账户的年龄平均低于负类账户。这是很直观的,因为正类数据集中的账户通常是根据传播宣传的需要而创建的。

Limitations
Data Bias
我们的数据集规模庞大、主题多样、模式多元,而且涵盖了多个国家和多种语言的推文,因此是研究推特上国家支持的宣传的绝佳资源。不过,由于我们的数据集侧重于某些主题(即标签),所选推文中所代表的行为和个人特征可能无法全面代表用户。因此,要进行用户层面的分析,研究人员应从用户时间线中收集更多的推文,以减少这 种潜在的偏差。对于正面数据集中的用户,可从 Twitter 提供的档案中收集完整数据;对于负面数据集中的用户,可根据提供的用户 ID 通过 Twitter API 收集时间线。 此外,由于我们的抽样过程,我们的数据集不应应用于研究国家支持推文以外的任何领域。这是因为存在以下潜在偏差: 首先,正类数据集中的所有用户都是国家支持的用户,并不代表 Twitter 的普通用户。其次,负类数据集中的所有用户都在推特上谈论某些话题,这可能无法代表整个推特用户。第三,虽然只有约 10% 的正常推文与政治话题有关(Colleoni、Rozza 和 Arvidsson,2014 年),但我们数据集中的大部分推文都是政治性的。根据研究人员的需要,他们可能会受益于不同的采样策略。在这种情况下,我们建议研究人员使用公开可用的数据来创建最符合其需求的样本。
Primary Data Errors
由于我们的数据都不是通过 Twitter 的应用程序接口直接从 Twitter 收集的,因此原始数据(即原始数据)中的错误很难纠正,因为原始的正类推文已不再对公众开放,只能通过 Twitter 提供的档案获取。 我们在原始数据中遇到的最常见错误是某些数值特征存在负值,而这些数值特征不可能是负值。例如,转发量 # 应该总是大于 0,但我们发现有些推文的转发量 # 被错误地设置为小于 0。
Recommendations for Usage
考虑到上述分析和局限性,我们在下文中提出了两个可以利用我们的数据集进行研究的关键领域。
识别国家支持的宣传 在社交媒体上检测国家支持的宣传是一项重要而及时的研究课题,有可能产生巨大的影响。要训练出用于检测国家支持的宣传的稳健、可泛化的机器学习模型,需要跨越不同时期、主题和组织的大型标注数据集。我们的数据集满足了这些要求,是训练此类模型的理想选择。 此外,识别国家支持的宣传背后的来源(即国家)也是一个有趣的研究问题。我们的数据集提供了来自不同国家的标签数据,从而简化了多类预测模型的训练。
分析国家支持的宣传 除了识别,分析国家支持的宣传也非常重要。对这些数据的分析可以加强我们对各国在社交媒体上进行宣传的机制的了解。这有助于制定政策来削弱此类宣传的影响力。 由于我们的数据集包含了有关宣传活动的用户和内容信息(以及相应的背景数据),因此非常适合分析不同国家支持的宣传机构所使用的技术。例如,我们的数据集可用于研究不同组织在讨论类似话题和观点时使用的不同策略。
此外,我们的数据集还可用于研究某些国家正在支持或攻击的问题,以揭示这些国家的地缘政治立场和目标。 最后,鉴于我们的数据集在时间、主题和组织方面的多样性,它可用于更深入地了解宣传信息,同时考虑到组织、主题和时间特征。
Conclusion
在这项工作中,我们引入了一个大规模、纵向和多样化的数据集,用于研究推特上国家支持的信息操作,涵盖 14 个国家和超过 3 年的时间(2015-2018 年)。我们的数据集包括内容和用户信息,其独特之处在于正面宣传数据集与拓扑和时间上一致的负类背景数据集进行了匹配。 我们对国家赞助账户和背景账户的推文级和用户级特征进行了初步分析。结果显示,两类数据在某些特征上存在显著的统计学差异。这些结果可能有助于在今后的工作中识别和分析国家赞助的宣传活动。