面试题-JVM(一)
参考文章:
(Java实习生)每日10道面试题打卡——JVM篇_兴趣使然的草帽路飞的博客-CSDN博客
狂神说——JVM笔记_小小酒馆的掌柜的博客-CSDN博客_狂神说jvm
1、请你简述一下 Java 内存结构(运行时数据区)
如图所示:
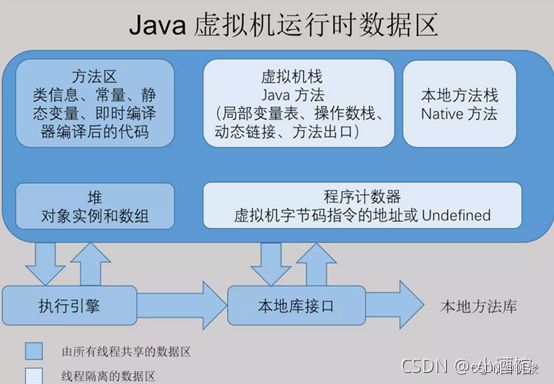
① 程序计数器
- 程序计数器:线程私有。一块较小的内存空间,程序计数器用于保存 JVM 中下一条所要执行的字节码指令的地址!如果正在执行的是 Native 方法,则这个计数器值则为空。程序计数器在硬件层面是通过 寄存器 实现的!
Java指令执行流程:
.java代码源文件经过编译为.class二进制字节码文件。.class文件中的每一条二进制字节码指令(JVM指令) 通过 解释器 转换成 机器码 然后就可以被 CPU 执行了!- 当 解释器 将一条 jvm 指令转换成 机器码 后,同时会向程序计数器 递交下一条 jvm 指令的执行地址!
② 虚拟机栈
-
虚拟机栈:线程私有,它的生命周期与线程相同。虚拟机栈是Java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
-
每个栈由多个栈帧(Frame) 组成,对应着每个方法运行时所占用的内存。
-
每个线程只能有一个活动栈帧,对应着当前正在执行的方法,当方法执行时压入栈,方法执行完毕后弹出栈。
-
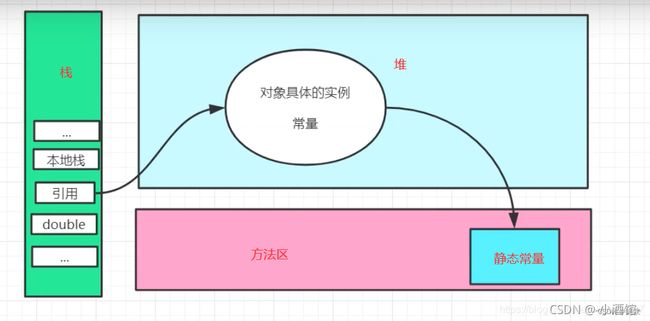
存放的东西:八大基本类型+new出来的对象引用地址+实例方法的引用地址。
③ 本地方法栈
- 本地方法栈:线程私有。本地方法栈与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
一些带有native 关键字修饰的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法!
④ 堆
- 堆:线程共享。Java堆是Java虚拟机所管理的内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建。Java堆的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
- 通过
new关键字创建的对象都会被放在堆内存。 - 方法体中的引用变量和基本类型的变量都在栈上,其他都在堆上。
- 是垃圾收集器管理的主要区域,Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”(Garbage)。
-Xmx -Xms:JVM初始分配的堆内存由-Xms指定,默认是物理内存的1/64。
- 通过
⑤ 方法区
-
方法区:线程共享。方法区存储虚拟机加载的类信息,常量,静态变量方法区用于存储已被虚拟机加载的 *类信息(构造方法、接口定义)、常量、静态变量、即时编译器编译后的代码(字节码)*等数据。
- 方法区在 JVM 启动的时候被创建,并且它的实际的物理内存空间和 Java堆一样都可以是不连续的, 关闭 Jvm 就会释放这个区域的内存。
- 方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误:
(java.lang.OutOfMemoryError:PermGen space、java.lang.OutOfMemoryError:Metaspace)。
-
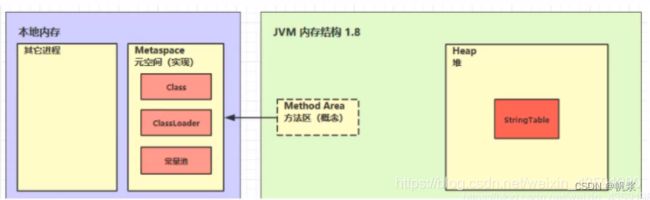
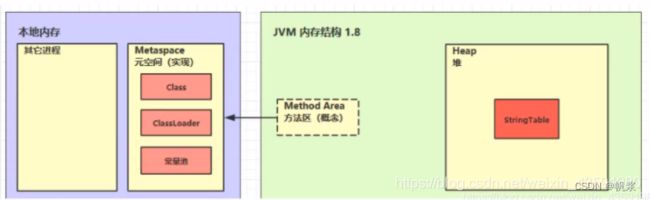
注意:方法区是一种规范,而永久代和元空间是它的2种实现方式。
方法区的演进:
- JDK1.6 版本方法区是由 永久代 实现(使用堆内存的一部分作为方法区),且由JVM 管理。由Class、ClassLoader、常量池(包括StringTable) 组成。
- JDK1.7 版本仍有永久代,但已经逐步 " 去永久代 ",StringTable、静态变量从永久代移除,保存在堆中。
- JDK1.8 版本后,方法区交给本地内存管理,而脱离了JVM,由元空间实现(元空间不再使用堆的内存,而是使用本地内存,即操作系统的内存),由Class、ClassLoader、常量池(StringTable 被移到了堆中管理) 组成。
⑥ 运行时常量池(存在于方法区内)
- 常量池:可以看做是一张表,虚拟机指令根据这张常量表找到要执行的 类名,方法名,参数类型、字面量 等信息。
- 常量池是
*.class文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实内存地址。
- 常量池是
- 运行时常量池:是方法区的一部分。
String str = new String("hello");
上面的语句中变量 str 放在栈上,用 new 创建出来的字符串对象放在堆上,而hello这个字面量是放在堆中。
Native、本地方法栈(面试加分项)
Native
-
native :凡是带了native关键字的,说明java的作用范围达不到了,会去调用底层c语言的库!(java是用C语言编写的,又名C+±-)
-
会进入本地方法栈,然后通过本地接口 (JNI),调用本地方法库
-
JNI作用:开拓Java的使用,融合不同的编程语言为Java所用,Java诞生的时候C、C++横行,想要立足,必须要有调用C、C++的程序
-
它在内存区域中专门开辟了一块标记区域: Native Method Stack,登记native方法
-
在最终执行的时候,通过本地接口 (JNI),加载本地方法库中的方法
-
如 String 类中的 **private native void start0();**就是调用了本地方法库方法
本地方法栈(Native Method Stack)
它的具体做法是Native Method Stack中登记native方法,在执行引擎执行的时候通过本地接口 (JNI),加载本地方法库(Native Libraies)。
本地接口(Native Interface)JNI
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序, Java在诞生的时候是C/C++横行的时候,想要立足,必须有调用C、C++的程序,于是就在内存中专门开辟了块区域处理标记为native的代码,它的具体做法是在Native Method Stack 中登记native方法,在( Execution Engine )执行引擎执行的时候加载Native Libraies。
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍!
栈、堆、方法区
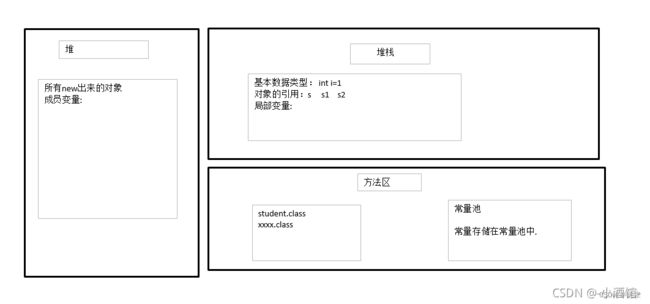
PC寄存器 (程序计数器: Program Counter Register)
每个线程都有一个程序计数器,是线程私有的,就是一个指针, 指向方法区中的方法字节码(用来存储指向像一条指令的地址, 也即将要执行的指令代码),在执行引擎读取下一条指令, 是一个非常小的内存空间,几乎可以忽略不计
方法区Method Area
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间;
静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池存在方法区中,但是实例变量和数组的内容存在堆内存中,和方法区无关
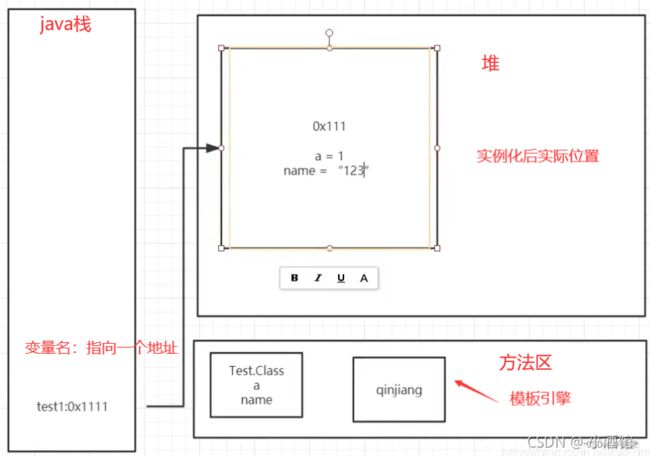
栈 stack
栈:栈内存,主管程序的运行,生命周期和线程同步;
线程结束,栈内存也就是释放,对于栈来说,不存在垃圾回收问题
一旦线程结束,栈就Over!
堆 Heap
一个JVM仅有一个堆内存,堆内存大小可以调节
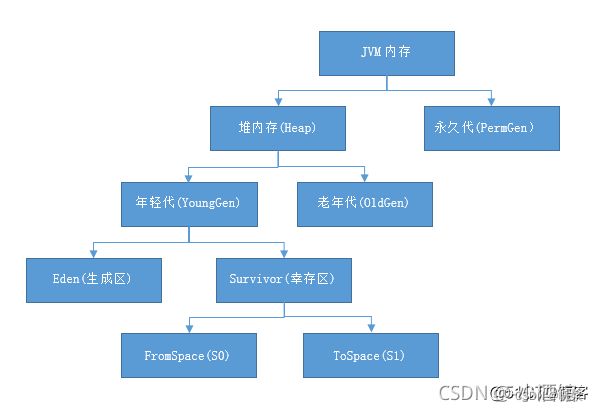
- JVM内存划分为堆内存和非堆内存(在本地内存上),堆内存分为年轻代(Young Generation)、老年代(Old Generation),非堆内存就一个永久代(Permanent Generation)。
- 年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1。Eden满了就触发轻GC,经过轻GC存活下来的就到了幸存者区,幸存者区满之后意味着新生区也满了,则触发重GC,经过重GC之后存活下来的就到了老年代。
- 堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
- 老年代:在新生代中经历了多次(具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年代中。老年代中的对象生命周期较长,存活率比较高,在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢。
- 在新生代中经历了多次(具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年代中。老年代中的对象生命周期较长,存活率比较高,在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢。
- 非堆内存用途:永久代,也叫方法区存储类信息、常量、静态变量、即时编译器编译后的代码等数据,对这一区域而言,Java虚拟机规范指出可以不进行垃圾收集,一般而言不会进行垃圾回收。
分代概念
1、新生成的对象首先放到年轻代Eden区,当Eden空间满了,触发Minor GC,存活下来的对象移动到Survivor0区,Survivor0区满后触发执行Minor GC,Survivor0区存活对象移动到Suvivor1区,这样保证了一段时间内总有一个survivor区为空。经过多次Minor GC仍然存活的对象移动到老年代。
2、老年代存储长期存活的对象,占满时会触发Major GC=Full GC,GC期间会停止所有线程等待GC完成,所以对响应要求高的应用尽量减少发生Major GC,避免响应超时。
Minor GC : 清理年轻代
Major GC : 清理老年代
Full GC : 清理整个堆空间,包括年轻代和永久代
所有GC都会停止应用所有线程。
元空间
在JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是:元空间并不在JVM中,而是使用本地内存。
元空间有注意有两个参数:
- MetaspaceSize :初始化元空间大小,控制发生GC阈值
- MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
移除永久代原因:
为融合HotSpot JVM与JRockit VM(新JVM技术)而做出的改变,因为JRockit没有永久代。有了元空间就不再会出现永久代OOM问题了!
2.类加载的过程是什么?
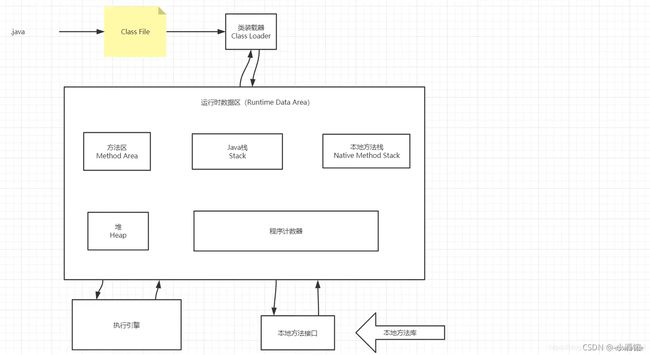
1、如上图所示,Java源代码文件会被Java编译器编译为字节码文件(.class后缀)然后由JVM中的类加载器加载各个类的字节码文件,加载完毕之后,交由JVM执行引擎执行。
2、百分之99的JVM调优都是在堆中调优,Java栈、本地方法栈、程序计数器是不会有垃圾存在的。
3、请问jvm垃圾回收是否涉及栈内存?
- 不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
4、虚拟机栈内存的分配越大越好吗?
- 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
来看一张图:
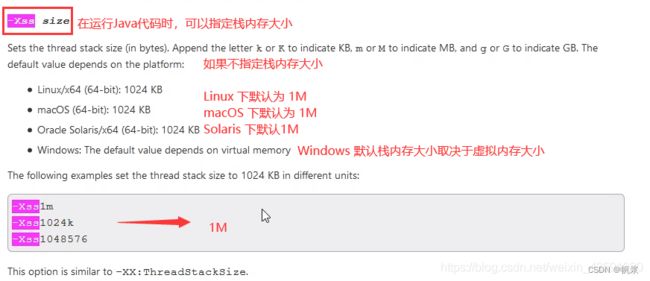
- 举例:如果物理内存是500M(假设),如果一个线程所能分配的栈内存为2M的话,那么可以有250个线程。而如果一个线程分配栈内存占5M的话,那么最多只能有100 个线程同时执行!
5、什么是类加载器?
作用:加载.class文件。
新建的对象放入堆里面,引用(地址)放到栈,其中引用指向堆里面对应的对象。
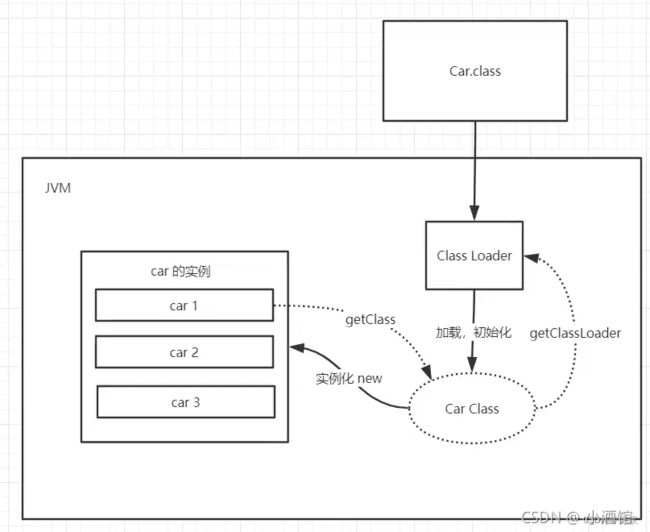
1)启动类(根)加载器 Bootstrap ClassLoader
2)扩展类加载器 Extension ClassLoader
3)应用程序(系统类)加载器 Application ClassLoader
1-启动类加载器,负责加载jre\lib目录下的rt.jar包
2-扩展类加载器:负责加载jre\lib\ext目录下的所有jar包
3-应用程序类加载器:负责加载用户类路径上所指定的类库,如果应用程序中没有自定义加载器,那么次加载器就为默认加载器。
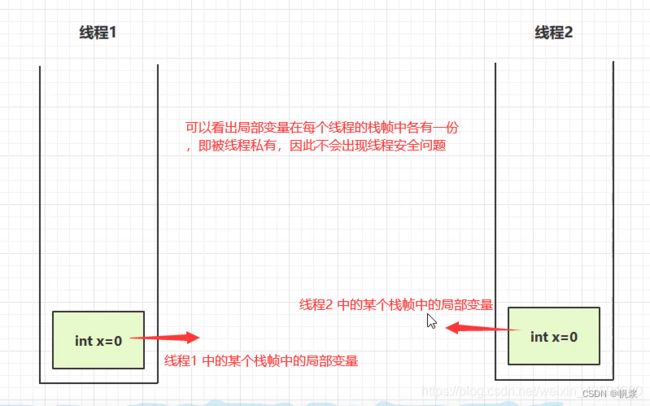
6、从JVM的角度分析,方法内的局部变量是否是线程安全的?
我们通过两张图去分析一下:
- 情况一:
- 情况二:
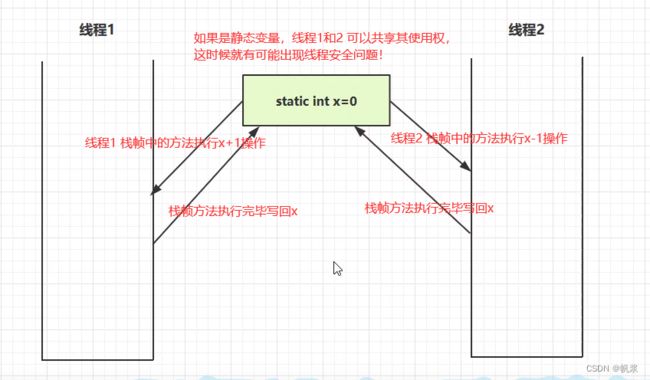
从图中得出:局部变量如果是静态的可以被多个线程共享,那么就存在线程安全问题。如果是非静态的只存在于某个方法作用范围内,被线程私有,那么就是线程安全的!
所以,该面试题答案是:
- 如果方法内局部变量没有逃离方法的作用范围,则是线程安全的。
- 如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题。
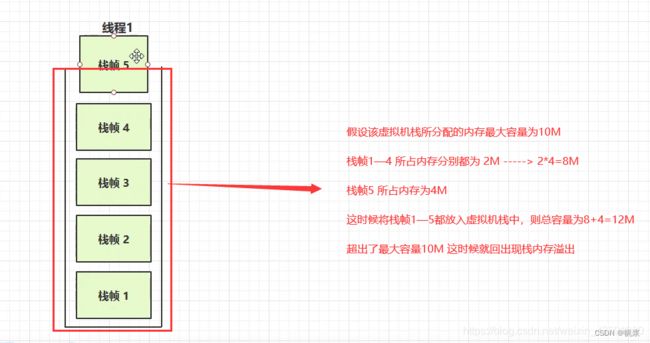
7、虚拟机栈内存溢出的情况有哪些?
- 1.虚拟机栈中,栈帧过多(方法无限递归)导致栈内存溢出,这种情况比较常见!
- 2.每个栈帧所占用内存过大(某个/某几个栈帧内存直接超过虚拟机栈最大内存),这种情况比较少见!
如图所示,就是栈中栈帧过多的情况:
8、请你说一下JVM运行时数据区方法区的演进?
- JDK1.6 版本方法区是由 永久代 实现(使用堆内存的一部分作为方法区),且由JVM 管理。由Class、ClassLoader、常量池(包括StringTable) 组成。
- JDK1.7 版本仍有永久代,但已经逐步 " 去永久代 ",StringTable、静态变量从永久代移除,保存在堆中。
- JDK1.8 版本后,方法区交给本地内存管理,而脱离了JVM,由元空间实现(元空间不再使用堆的内存,而是使用本地内存,即操作系统的内存),由Class、ClassLoader、常量池(StringTable 被移到了堆中管理) 组成。
为什么要用元空间取代永久代?
因为永久代有以下几个弊端:
- ① 字符串常量池存在于永久代中,在大量使用字符串的情况下,非常容易出现OOM的异常。
- ② JVM加载的class的总数,方法的大小等都很难确定,因此对永久代大小的指定难以确定。太小的永久代容易导致永久代内存溢出,太大的永久代则容易导致虚拟机内存紧张,空间浪费。
- ③ 永久代进行调优很困难:方法区的垃圾收集主要回收两部分,常量池中废弃的常量和不再使用的类。而不再使用的类或类的加载器回收比较复杂,FULL GC 的时间长。
9、请问Java虚拟机中有哪些类加载器?
以 JDK 8 为例:
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader(启动类加载器) | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader(扩展类加载器) | JAVA_HOME/jre/lib/ext | 上级为 Bootstrap,显示为 null |
| Application ClassLoader(应用程序类加载器) | classpath | 上级为 Extension |
| 自定义类加载器 | 自定义 | 上级为 Application |
类加载器的优先级(由高到低):启动类加载器 -> 扩展类加载器 -> 应用程序类加载器 -> 自定义类加载器。
10、请你说一下类的加载的过程?
类加载的过程包括:加载、验证、准备、解析、初始化。其中验证、准备、解析统称为连接。
-
加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的
java.lang.Class对象。 -
验证:确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
-
准备:为静态变量分配内存并设置静态变量初始值,这里所说的初始值“通常情况”下是数据类型的零值。
-
解析:将常量池内的符号引用替换为直接引用。
-
初始化:到了初始化阶段,才真正开始执行类中定义的 Java 初始化程序代码。主要是静态变量赋值动作和静态语句块(
static{})中的语句。
11、请你说一下什么是双亲委派模型?
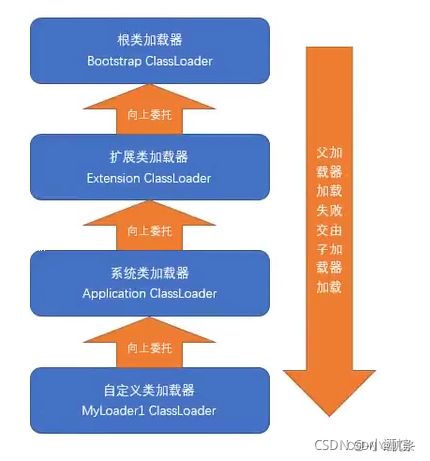
双亲委派机制的工作过程:
- 类加载器收到类加载的请求;
- 把这个请求委托给父加载器去完成,一直向上委托,直到启动类(根)加载器;
- 启动类加载器检查能不能加载(使用findClass()方法),能加载就结束;否则抛出异常,通知子加载器进行加载;
- 重复步骤三.
举个例子
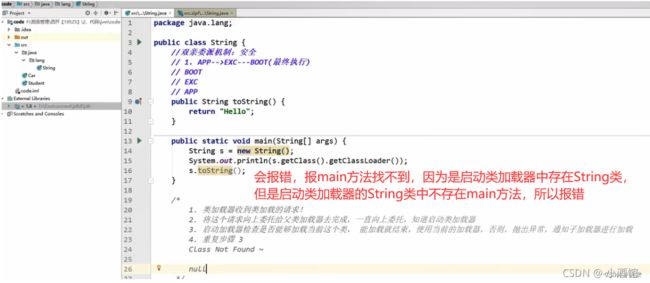
大家所熟知的String类,String默认情况下是启动类加载器进行加载的。假设我也自定义一个String,并且制定加载器为自定义加载器。现在你会发现自定义的String可以正常编译,但是永远无法被加载运行。
因为申请自定义String加载时,总是启动类加载器加载,而不是自定义加载器,也不会是其他的加载器。
什么是双亲委派模型?
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
为什么要使用双亲委派模型呢?(好处)
避免重复加载 + 避免核心类篡改
- 采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父加载器已经加载了该类时,就没有必要子加载器再加载一次。
- 其次是考虑到安全因素,java 核心 api 中定义类型不会被随意替换,假设通过网络传递一个名为
java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
12、说一下虚拟机栈和堆的区别?
① 物理地址方面的区别:
- 堆 的物理地址分配对对象是不连续的。因此性能慢些。
- 虚拟机栈 使用的是数据结构中的栈,先进后出的原则,物理地址分配是连续的。所以性能快。
② 内存分配方面的区别:
- 堆 因为是不连续的,所以分配的内存是在
运行期确认的,因此大小不固定。一般堆大小远远大于虚拟机栈。 - 虚拟机栈 是连续的,所以分配的内存大小要在
编译期就确认,大小是固定的。
③ 存放的内容方面的区别:
- 堆 存放的是对象的实例和数组。因此该区更关注的是数据的存储。
- 虚拟机栈 存放的是局部变量,操作数栈,返回结果。该区更关注的是程序方法的执行。
注:静态变量放在方法区,而静态的对象还是放在堆。
④ 线程共享方面的区别:
- 堆 对于整个应用程序都是共享、可见的。
则,物理地址分配是连续的。所以性能快。