Pandas& NumPy Simple Practice Usage
(This blog merely for self-reading, self-review and every programming lover's share under no commercial circumstance.)
Recently a friend of mine has asked me desperately for helping. It was his homework, which has to be accomplished by Pandas and NumPy (Two Python Library). They are frequently used in data cleansing and data aggregation. The following could be separated into a brief tutorial of pandas and the practice operation for help working on the explicit data.
First and foremost, it is compelled to introduce the basic glossaries and common structure in pandas.
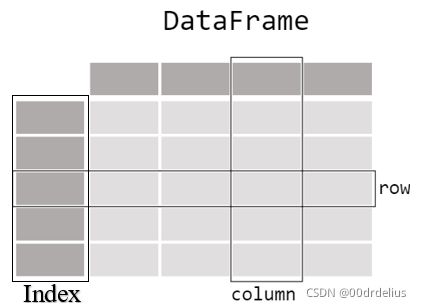
This is a DataFrame, which is a 2-dimensional labelled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table, or a dict of Series objects. It is generally the most commonly used pandas object. And by the way, each column in a DataFrame is a Series.
It is sincerely powerful. The figure beneath has shown you how many file format pandas could import. And almost every function you conceive can be used in pandas.

Then follows the practice operation.
In this practice, I should aggregate a 172282-rows x 9-columns table. My friend gave me the csv file to contain the data. It is supposed to import them into the command or some similar IDLE (Integrated Development and Learning Environment):
But firstly, we should check the path is where:
>>>import os
>>>os.chdir(‘C://Users/p1907831/desktop’) #I fancy operating in Desktop.
>>>os.getcwd() #To check if the path has changed to the proper place.
>>>import pandas as pd
>>>import numpy as np
>>>a=pd.read_csv(‘data.csv’) #The csv file has been uploaded to Desktop, so get it >>>directly.
>>>a #Obviously you want to see the DataFrame first.
Then it should be like this:
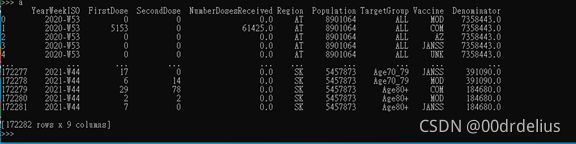
This is a sample of DataFrame in Windows cmd. It will be really complex if you aggregate these immense data in Excel. Hence, we don’t operate in Excel but in cmd by pandas.
>>>b=pd.read_csv('data.csv',usecols=['FirstDose'])
>>>c=pd.read_csv('data.csv',usecols=['SecondDose'])
>>>b
>>>c
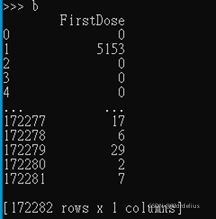
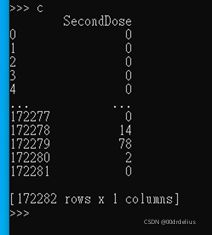
Because we should add FirstDose and SecondDose, so, we need to extract them to the separate arguments: ’b’ and ‘c’. Then convert them into array in NumPy.
>>>d=b.to_numpy()
>>>e=c.to_numpy()
>>>d
>>>e

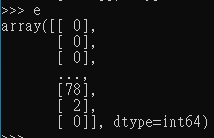
They are the structure of arrays now, nor DataFrame. Then add d+e:
>>>f=d+e
>>>f
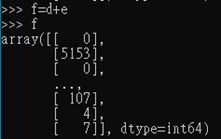
The Total has been calculated. Now change the structure again and rename the colcumn:
>>>g= pd.DataFrame(f) #pd.DataFrame function supports to convert array structure to DataFrame.
>>>g
>>>h=g.rename(columns={0:'TotalDose'}) #Rename multipule columns:DF.rename(columns={0:'TotalDose',’str’:’str,int:’str’})
>>>h

But it is not supposed to be so hurried because we could insert the column nor ‘h’ DataFrame to the original DataFrame. However, we should change ‘h’ to the list structure:
>>>h.values.tolist() #This operation converts every value into a single list and covered all in a whole list.
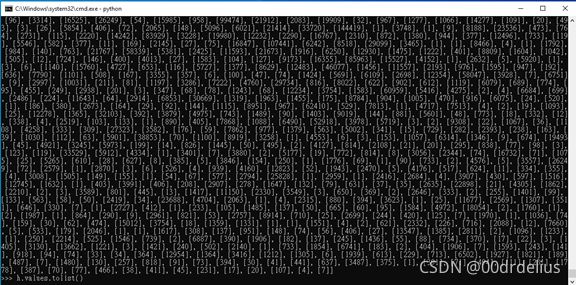
Apparently, if we import it into the csv file, there will be every square bracket around every value in every cell. Hence, we should input this:
>>>i = h.stack().tolist()

Then insert the list to the original DataFrame:
>>>a[‘TotalDose’] = i
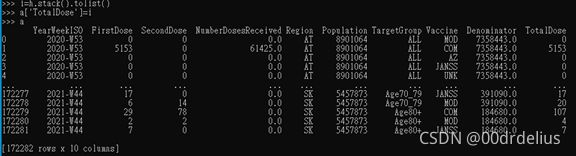
Goddamn hell. The insertion supports to insert array too!!
>>>a[‘TotalDose’] =array
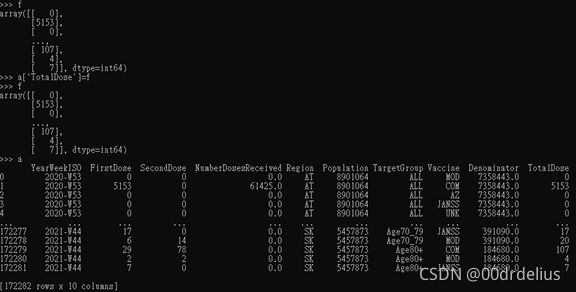
Never mind. Let’s keep on.
We need the current utter DataFrame, so let’s input it into csv first:
>>>a.to_csv(‘utter.csv’) #If you haven’t created the csv file, this function will help you create one in the path.
Then we also need a csv file covered the whole sum of all integer data according to the respective regions. In consequence:
>>>k=a.groupby(‘Region’).sum() #case sensitive(大小写) warning!!
>>>k
"""
The index here has changed to the Region and every integer data has been sum up and the other data structures have been automatically deleted. Then input it into a csv file.
We also need a csv file covered the whole sum of all integer data grouped by the respective regions and every vaccine brands’ purchases in every region:
"""
>>>l=a.groupby([‘Region’,’Vaccine’]).sum() #case sensitive(大小写) warning!!Then input it into csv file.
Over.
"""replenishment"""
"""To use one single column or with any other of a csv file or a excel file"""
pd.read_csv('abaaba.csv',usecols=['abaaba','abaaba'])
pd.read_excel(""" abaabaaba """)
"""To use one single column or with any other in an already-existed DataFrame"""
a=pd.DataFrame({
'apple':['a','b','c'],
'banana':[1,2,3],
'carrot':['I','II','III']})
apple banana carrot
0 a 1 I
1 b 2 II
2 c 3 III
a.loc[:,'apple'] # : (colon) stands for index
'''or'''
a.iloc[:,0] # 0 stands for the sequence of the columns
0 a
1 b
2 c
Name: apple, dtype: object
'''To access multiple columns in a DataFrame'''
a.loc[:,['apple','banana']]
'''or'''
a.iloc[:,[0,1]]
apple banana
0 a 1
1 b 2
2 c 3
'''To change the exact value in one cell.'''
b=a.iloc[0,0]
print(b)
>>>a
a.iloc[0,0]= aaaaa
print(a.iloc[0,0])
>>> aaaaa
print(a)
>>>
apple banana
0 aaaaa 1
1 b 2
2 c 3
PS more:
'''To rename the columns name and change the order.'''
''' to find out the particular rows in columns'''
print(a)
>>>
YearWeekISO FirstDose SecondDose NumberDosesReceived country Population TargetGroup Vaccine Denominator
0 2020-W53 0 0 0.0 AT 8901064 ALL MOD 7358443.0
1 2020-W53 5153 0 61425.0 AT 8901064 ALL COM 7358443.0
2 2020-W53 0 0 0.0 AT 8901064 ALL AZ 7358443.0
3 2020-W53 0 0 0.0 AT 8901064 ALL JANSS 7358443.0
4 2020-W53 0 0 0.0 AT 8901064 ALL UNK 7358443.0
... ... ... ... ... ... ... ... ... ...
172277 2021-W44 17 0 0.0 SK 5457873 Age70_79 JANSS 391090.0
172278 2021-W44 6 14 0.0 SK 5457873 Age70_79 MOD 391090.0
172279 2021-W44 29 78 0.0 SK 5457873 Age80+ COM 184680.0
172280 2021-W44 2 2 0.0 SK 5457873 Age80+ MOD 184680.0
172281 2021-W44 7 0 0.0 SK 5457873 Age80+ JANSS 184680.0
[172282 rows x 9 columns]
c=list(a.columns)
print(c)
>>>['YearWeekISO', 'FirstDose', 'SecondDose', 'NumberDosesReceived', 'country', 'Population', 'TargetGroup', 'Vaccine', 'Denominator']
'''To change the name in list c then get ⬇'''
d=['YearWeekISO', 'FirstDose', 'SecondDose', 'NumberDosesReceived', 'nation', 'Population', 'TargetGroup', 'Vaccine', 'Denominator']
a.columns=d
print(a)
>>>
YearWeekISO FirstDose SecondDose NumberDosesReceived nation Population TargetGroup Vaccine Denominator
0 2020-W53 0 0 0.0 AT 8901064 ALL MOD 7358443.0
1 2020-W53 5153 0 61425.0 AT 8901064 ALL COM 7358443.0
2 2020-W53 0 0 0.0 AT 8901064 ALL AZ 7358443.0
3 2020-W53 0 0 0.0 AT 8901064 ALL JANSS 7358443.0
4 2020-W53 0 0 0.0 AT 8901064 ALL UNK 7358443.0
... ... ... ... ... ... ... ... ... ...
172277 2021-W44 17 0 0.0 SK 5457873 Age70_79 JANSS 391090.0
172278 2021-W44 6 14 0.0 SK 5457873 Age70_79 MOD 391090.0
172279 2021-W44 29 78 0.0 SK 5457873 Age80+ COM 184680.0
172280 2021-W44 2 2 0.0 SK 5457873 Age80+ MOD 184680.0
172281 2021-W44 7 0 0.0 SK 5457873 Age80+ JANSS 184680.0
[172282 rows x 9 columns]
'''Then change the order of Dataframe's columns,
which should you give a list include the current name but order changed.'''
new_order=['YearWeekISO','Vaccine', 'FirstDose', 'SecondDose', 'NumberDosesReceived', 'nation', 'Population', 'TargetGroup', 'Denominator']
a=a[new_order] #list in the list which comprises the columns' name in DataFrame.
print(a)
>>>
YearWeekISO Vaccine FirstDose SecondDose NumberDosesReceived nation Population TargetGroup Denominator
0 2020-W53 MOD 0 0 0.0 AT 8901064 ALL 7358443.0
1 2020-W53 COM 5153 0 61425.0 AT 8901064 ALL 7358443.0
2 2020-W53 AZ 0 0 0.0 AT 8901064 ALL 7358443.0
3 2020-W53 JANSS 0 0 0.0 AT 8901064 ALL 7358443.0
4 2020-W53 UNK 0 0 0.0 AT 8901064 ALL 7358443.0
... ... ... ... ... ... ... ... ... ...
172277 2021-W44 JANSS 17 0 0.0 SK 5457873 Age70_79 391090.0
172278 2021-W44 MOD 6 14 0.0 SK 5457873 Age70_79 391090.0
172279 2021-W44 COM 29 78 0.0 SK 5457873 Age80+ 184680.0
172280 2021-W44 MOD 2 2 0.0 SK 5457873 Age80+ 184680.0
172281 2021-W44 JANSS 7 0 0.0 SK 5457873 Age80+ 184680.0
[172282 rows x 9 columns]
'''Then find out all nations abbrivations starts only with two letters'''
'''To use DF[DF['column name'].str.contains('string')].
You might need to utilise regular expression to scour.'''
b=a[a['nation'].str.contains(r'^\w\w$')]
pritn(b)
>>>
YearWeekISO Vaccine FirstDose SecondDose NumberDosesReceived nation Population TargetGroup Denominator
0 2020-W53 MOD 0 0 0.0 AT 8901064 ALL 7358443.0
1 2020-W53 COM 5153 0 61425.0 AT 8901064 ALL 7358443.0
2 2020-W53 AZ 0 0 0.0 AT 8901064 ALL 7358443.0
3 2020-W53 JANSS 0 0 0.0 AT 8901064 ALL 7358443.0
4 2020-W53 UNK 0 0 0.0 AT 8901064 ALL 7358443.0
... ... ... ... ... ... ... ... ... ...
172277 2021-W44 JANSS 17 0 0.0 SK 5457873 Age70_79 391090.0
172278 2021-W44 MOD 6 14 0.0 SK 5457873 Age70_79 391090.0
172279 2021-W44 COM 29 78 0.0 SK 5457873 Age80+ 184680.0
172280 2021-W44 MOD 2 2 0.0 SK 5457873 Age80+ 184680.0
172281 2021-W44 JANSS 7 0 0.0 SK 5457873 Age80+ 184680.0
[50084 rows x 9 columns]