hive笔记
Hive 介绍:1.sql 2.udf
官网:hive.apache.org
由Facebook提出的 开源=》去解决海量结构化数据的数据统计问题
构建在hadoop之上的数据仓库
hdfs: hive的数据是存储在hdfs之上的,存储空间不够时,可以通过hdfs动态扩展
yarn:hive的作业是可以跑在yarn之上的
mapreduce:hive的作业可以以MR的方式去运行
如何使用?
1.定义了一种类sql的语言 =》 类似sql 又不完全相同
2.适用于离线/批处理
3.开发就是sql =》 mr作业=》yarn上去运行
4.hive 存储数据 也支持 压缩、存储格式
Hive底层引擎
MR :把hive sql转变为MR作业去运行 默认
Tez: 把hive sql 转变为Tez作业去运行
Spark: 把hive sql 转变为Spark作业去运行
生产上用 sparksql 去处理hive里面的数据
hive on spark =》 hive的引擎是spark 生产上用的不多
spark on hive =》 sparksql 查询hive的里面表
版本
HDFS 、腾讯cos、阿里oss、亚马逊aws都可以使用hive sql进行处理
版本介绍: x.y.z
x 大版本
y 小版本
z 小版本的bug修复
hive优点
1.简单易用
2.扩展性好 :
1.sql 功能角度(函数):如果sql功能不满足,用户可以自定义udf函数
2.数据存储 和 计算角度 :hive是基于hadoop构建的数据仓库,数据存在hadoop上,如果表中数据存不下,可以对hadoop进行扩展,增加几个节点
计算也是一样的,hive作业提交到yarn上去运行,如果内存不足的话,container不足也可以进行扩展的
注意:hive仅仅就是个客户端而已,不存在集群的概念,构建在hadoop之上的,相当于在hadoop之上做了一个客户端完成数据分析
3.Metastore 【Hive的元数据管理】
sparksql presto impala 只要能够访问hive 的Metastore元数据 ,就可以访问 Hive里面表的数据,hive和其他框架可以共享元数据【可以共享Metastore】,相当于后面的计算框架只需要负责计算就可以,不需要负责存储,存储的功能交给hive,因为hive既要负责存储也要负责计算,如果觉得hive计算慢就用之后的计算框架,直接查询hive里面的元数据,就可以访问hive表里面的数据,进而进行数据的分析计算
hive架构
2.hive 的架构 rdbms
元数据:描述数据的数据 schema 表的名字、字段的名字、字段的类型、谁创建的、数据存储在哪 。。。
derby作为我们的元数据库的弊端: derby 仅支持单会话
在hive中有三种方式连接客户端
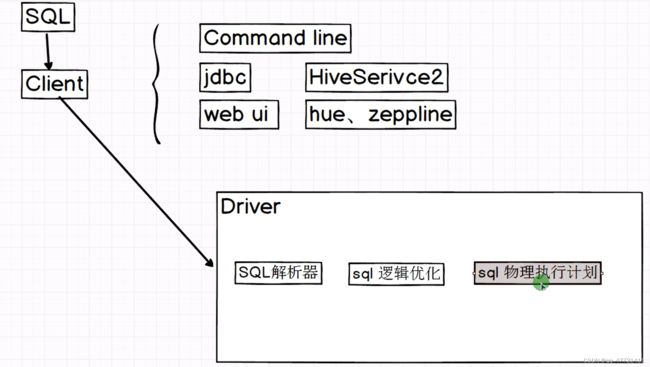
hive客户端主要是用来接收sql,把用户写的sql提交到客户端
sql解析器:检查用户提交的sql有没有语法问题
如果没有语法问题,就对sql进行逻辑优化
逻辑优化之后,执行之前,sql会做一个物理执行计划优化,比如加一些udf和字段解析等
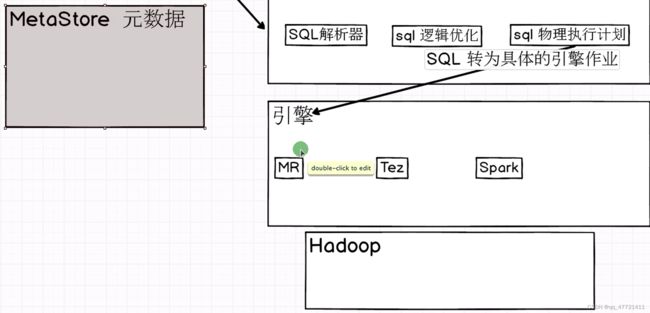
物理执行计划之后,把sql转为具体的引擎作业去运行,运行时要把作业提交给hadoop
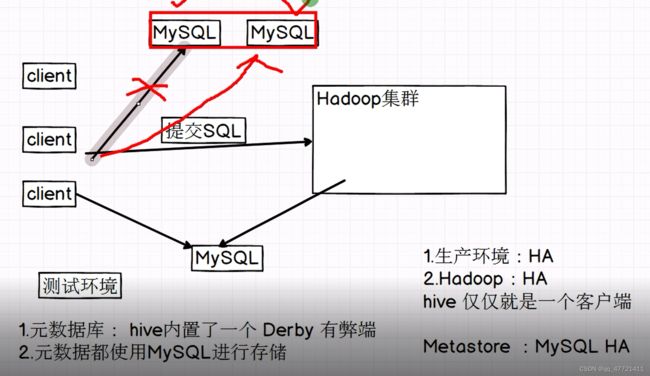
hive和RDBMS关系型数据库(关系型数据库首选mysql)的区别【面试】
1.共同点:都可以使用sql
2.延时性(处理数据快慢):hive适用于离线计算,处理数据慢,千万不要拿hive和mysql的执行性能对比,数据量都很小时,mysql处理性能高些,数据量上来之后mysql执行性能要比hive低
3.事务(一次操作要么成功要么失败):都支持,但hive不关心事务,mysql可能会用到事务
4. update delete这两个语句hive和mysql都有,但hive不会更新某个表的某条数据,hive里面基本不用, 因为性能太差,我们不是通过这种方式更新数据的
5.分布式 都支持
6.成本:hive部署机器比较廉价,对机器要求不高,mysql对机器要求高,成本高
7.数据体量: hive操作数据量很大,mysql存TB级别的数据处理就很慢
入门
1.mysql => hive数据库 => version表里面记录了hive的版本
mysql> select * from version;
±-------±---------------±---------------------------+
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
±-------±---------------±---------------------------+
| 1 | 3.1.0 | Hive release version 3.1.0 |
±-------±---------------±---------------------------+
2.创建一张表
hive> create table test(name string);
hive> insert into test values (‘tom’);
表中的数据存在哪里?
hive 数据有两种:
1.元数据 =》 MySQL
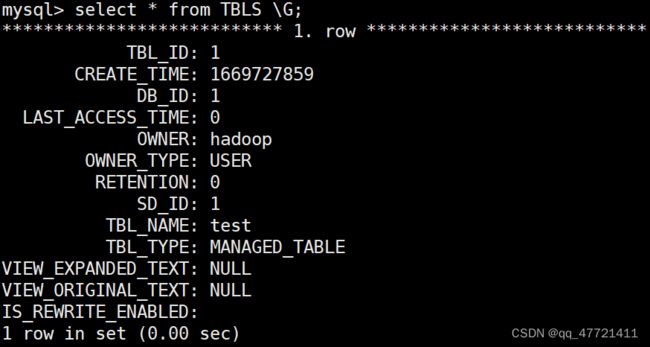
TBLS 存的是Hive里面表的信息
mysql> select * from TBLS;

DBS 存的是Hive 数据库相关的信息
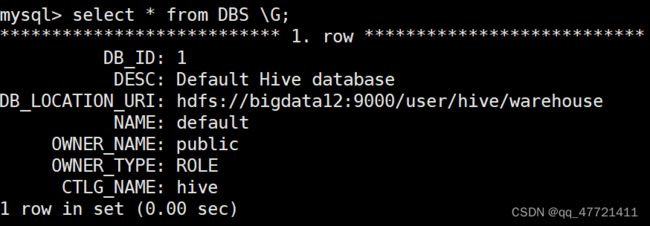
COLUMNS_V2 存的是Hive table里面的字段信息 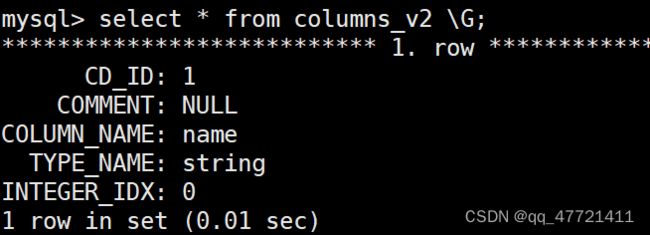
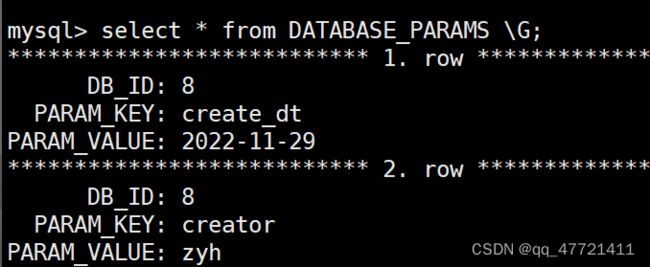
DATABASE_PARAMS 存的是Hive 数据库相关的信息
2.table 数据 =》 存在hdfs
hdfs://bigdata32:9000/user/hive/warehouse

表中的字段 存在哪里?
一个hive表 会被拆分成N个表在mysql里面进行存储
hive 运行的日志在什么地方?
/tmp/hadoop/hive.log
[hadoop@bigdata12 conf]$ cp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
![]()
日志在临时文件里需要修改日志地址

修改日志地址,在/home/hadoop/app/hive/下创建个logs
![]()
配置Hive参数
1.Command Line Interface 【命令行显示相关参数】
hive.cli.print.header 改为true
hive.cli.print.current.db 改为true
hive.metastore.warehouse.dir 【了解 default数据库默认存储位置】
2.如何查看参数默认值?
set key; 查看参数默认值
set key=value; 设置参数的值
3.参数配置优先级:
1.session 设置参数 【仅仅是当前session有效】
2.hive-site.xml 【全局生效的】
vim hive-site.xml
hive.cli.print.header
true
hive.cli.print.current.db
true
3.[hadoop@bigdata12 ~]$ hive --hiveconf hive.cli.print.current.db=false; => 【当前session有效】
-e SQL from command line 直接写sql
-f SQL from files 在文件里写sql
-H,–help Print help information
–hiveconf
–hivevar
commands. e.g. --hivevar A=B
-i Initialization SQL file
hive -help : -e sql 语句
-f sql文件
[hadoop@bigdata12 ~]$ hive -e “select * from test”;
[hadoop@bigdata12 ~]$ vim test.sql
select * from test;
[hadoop@bigdata12 ~]$ hive -f ./test.sql
数仓: 需求任务 每天定时调度的 10:00 触发一次任务
shell: hive -e “select * from test”
调度平台:crontab 、azkanban、xxl
hive语法
DDL:Data Definition Language
DML:

数据库相关操作
1.创建数据库
CREATE [REMOTE] (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
[] 可有可无
(|) 选择其中一个即可
create database bigdata_hive;
思考: 这个数据库在hdfs什么地方?
database 在hdfs上的路径:
默认数据库路径:/user/hive/warehouse
非默认数据库路径:/user/hive/warehouse/bigdata_hive(dbname).db
create database if not exists bigdata_hive;
create database bigdata_hive2 LOCATION ‘/data/bigdata_hive2’;默认走hdfs,如果向放在别的分布式存储上在前面加uri即可
create database bigdata_hive3 WITH DBPROPERTIES (‘creator’=‘doublehappy’, ‘create_dt’=“2099-11-29”);
create database if not exists bigdata_hive4 COMMENT “这是一个数据库4”;
2.查看数据库
show databases;
show databases like "bigdata_hive*"可以进行模糊查询
desc database bigdata_hive3;comment中文不显示
desc database EXTENDED bigdata_hive3;扩展信息
3.更改数据库
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, …);
alter database bigdata_hive3 set dbproperties (‘create_dt’=“2022-11-29”);
4.删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
drop database bigdata_hive4;
drop database bigdata_hive2 cascade;库里面有表时删除
表相关操作
1.创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], … [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …) [SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY ‘storage.handler.class.name’ [WITH SERDEPROPERTIES (…)]
]
create table test(
id string comment ‘用户id’,
name string,
age bigint
) comment ‘test table’
row format delimited fields terminated by ‘,’ 建表时要指定每列的分隔符!!
stored as textfile;
分割符:
1.hdfs 每行 有分割符 \n
2.hdfs 一行数据内容 每个列之间也要指定分割符
2.查看表
DESCRIBE [EXTENDED|FORMATTED] table_name
desc extended test;
desc formatted test;
常用的数据类型:
数值:
整型 :
int
bigint
小数 :float double decimal
字符串 : string
时间:
日期 DATE YYYY-MM-DD
时间戳 TIMESTAMP YYYY-MM-DD HH:MM:SS
3.导入数据
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
local: 从本地磁盘 往hivetable 中导入数据
不加local : 从hdfs 往hive table 中导入数据
load data local inpath ‘/home/hadoop/test.txt’ into table test;
练习创建 emp 表 并导入数据
create table emp (
empno decimal(4,0) ,
ename string ,
job string ,
mgr decimal(4,0) ,
hiredate string ,
sal decimal(7,2) ,
comm decimal(7,2) ,
deptno decimal(2,0)
)
row format delimited fields terminated by ‘,’
stored as textfile;
load data local inpath ‘/home/hadoop/tmp/emp.txt’ into table emp;
创建hive 表:
1.普通的建表语句
2.create table emp2 like emp; => 仅仅获取的 表结构
3.create table emp3 as select * from emp; 表结构+数据
CTAS : 使用场景 临时查询 =》 放入结果表中
load 加载数据
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
1.加载本地数据
load data local inpath ‘/home/hadoop/emp.txt’ into table emp;
2.加载hdfs数据
load data inpath ‘/data/emp.txt’ into table emp;
覆盖表中数据
load data local inpath ‘/home/hadoop/emp.txt’ overwrite into table emp;
insert
1.Inserting data into Hive Tables from queries
insert into(追加数据)|overwrite(覆盖数据) table tablename selectQury
insert into table emp2 select * from emp;
insert overwrite table emp2 select * from emp where deptno=10;
2.Inserting values into tables from SQL 【不推荐使用】
insert into table tablename values values_row [, values_row …]
insert into table test values(5,‘wangwu’,77);
每导入一条数据 就会触发一次 mapreduce job 效率太低
update delete => hive 不要用 效率低 =》insert overwrite
清空表中数据
TRUNCATE [TABLE] table_name
truncate table emp2;
select
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
1.where 过滤条件
where_condition
<
>
=
<> !=
and
or
in
not in
between and
is
is not
select *
from emp
where deptno=20 or deptno =10;
select *
from emp
where deptno in (10,20);
select *
from emp
where deptno <> 20;
select *
from emp
where deptno != 20;
2.order by 排序语法
1.默认asc 升序
2.降序 desc
select sal
from emp
order by sal desc;
3.like 语法 模糊匹配
1._ 占位符
2.% 模糊
rlike regexp
4.合并表
1.union 去重
2.union all 不去重
create table a(id int ,name string) row format delimited fields terminated by ‘,’ ;
create table b(id int ,name string) row format delimited fields terminated by ‘,’ ;
load data local inpath “/home/hadoop/a.txt” into table a;
load data local inpath “/home/hadoop/b.txt” into table b;
select name from a tom marry tom jack
union all
select name from b;
select name from a jack marry tom
union
select name from b;
select name from a tom marry tom jack lisi
union all
select name from b
union all
select "lisi" as name ;
select name,"1" as pk from a tom 2 marry 2 tom 1 jack 1 lisi 3
union all
select name,"2" as pk from b
union all
select "lisi" as name,"3" as id ;
union和union all 字段个数和字段类型相同即可
null 处理
5.null 处理
1. 过滤
where xxx is not null
select * from emp where comm is not null;
is null 作用一样 <=>
select * from emp where comm is null;
select * from emp where comm <=> null;
2. etl 转换
ifnull => hive里没有
coalesce =》 select coalesce(null,null,1);
nvl =》select nvl(null,1);
select empno,ename,job,mgr,hiredate,sal,
nvl(comm,0) as comm_alias,deptno
from emp;
查看hive支持的function
SHOW FUNCTIONS [LIKE ""];
show functions like nvl; => 判断 function hive 是否存在
desc function nvl; =》 查看某个函数具体使用
分组 聚合函数
1.group by
1.和聚合函数一起使用
2. 一个 或者多个 column 进行分组
3.分组字段 select 出现 和 group by 出现 要一致
having : 条件过滤
只能在group by 后面使用
where在group by之前使用
where和order by不能使用别名
order by在group by之后使用
2.聚合函数
聚合函数:多行数据按照一定规则 进行聚合为 一行
理论上 聚合后的行数 <=聚合前的行数
sum max min avg count
select job,
sum(sal) as sal_sum,
max(sal) as sal_max,
min(sal) as sal_min,
avg(sal) as sal_avg,
count(*) as cnt
from emp
group by job
having sal_sum > 6000;
子查询:
select
job,
sal_avg,
sal_max,
sal_min,
sal_sum,
cnt
from(
select
job,
sum(sal) as sal_sum,
max(sal) as sal_max,
min(sal) as sal_min,
avg(sal) as sal_avg,
count(*) as cnt
from emp
group by job
) as a
where sal_sum > 6000;
join
select
from(
) as a left join (
) as b
on a.id=b.id
1.inner join [join] 内连接 交集共有的数据
select
a.*,
b.*
from(
select *
from a
) as a inner join (
select *
from b
) as b
on a.name=b.name;
a.id a.name b.id b.name
1 tom 1 tom
2.left join 左连接 左表数据是全的
select
a.*,
b.*
from(
select *
from a
) as a left join (
select *
from b
) as b
on a.name=b.name;
a.id a.name b.id b.name
1 tom 1 tom
2 jack NULL NULL
3.right join 右连接 右表数据是全的
select
a.*,
b.*
from(
select *
from a
) as a right join (
select *
from b
) as b
on a.name=b.name;
a.id a.name b.id b.name
1 tom 1 tom
NULL NULL 2 marry
4.full join 全连接 左右表数据是全的
select
a.*,
b.*
from(
select *
from a
) as a full join (
select *
from b
) as b
on a.name=b.name
a.id a.name b.id b.name
2 jack NULL NULL
NULL NULL 2 marry
1 tom 1 tom
table:
维度:group by
指标:聚合函数、 普普通通列
where:
练习
1.各个部门每年入职的人数
table:emp select 部门,每年,人数
维度:部门 每年 from emp
指标:人数 group by 部门 每年;
where: no
select
deptno,
date_format(hiredate,'YYYY') as year,
count(*) as cnt
from emp
group by deptno,date_format(hiredate,'yyyy');
2.整个公司每年每月的入职人数
select
date_format(hiredate,'yyyy-MM') as yM,
count(*) as cnt
from emp
group by date_format(hiredate,'yyyy-MM');
开窗函数/窗口函数 窗口 + 函数 累计问题
需求:既要显示聚合前的数据,又要显示聚合后的数据?
窗口: 函数 运行时 计算的数据集的范围
函数: 运行时函数
语法结构:
函数 over([partition by xxx,…] [order by xxx,…])
over: 以谁进行开窗 table、
parition by : 以谁进行分组 table columns
order by : 以谁进行排序 table columns
函数:开窗函数、聚合函数
单单一个基本查询,开窗函数和group by 不能一起使用
举例:
每个用户每月累计点外卖次数
create table user_mt (
name string,
dt string,
cnt int
)
row format delimited fields terminated by ',' ;
load data local inpath '/home/hadoop/tmp/mt.txt' (overwrite) into table user_mt;
select
name ,
dt ,
cnt ,
sum(cnt) over(partition by name order by dt ) as sum_cnt
from user_mt;
开启hiveserver2,beeline连接,使用dbeaver查看
beeline shell 底层走的是jdbc-开启 hiveServer2 服务 底层是thift协议
jps -m
[hadoop@bigdata12 bin]$ jps -m
3681 SecondaryNameNode
3313 NameNode
4050 NodeManager
4578 RunJar /home/hadoop/app/hive/lib/hive-cli-3.1.2.jar org.apache.hadoop.hive.cli.CliDriver
3447 DataNode
3930 ResourceManager
4954 Jps -m
开启hiveServer2 服务:[hadoop@bigdata12 bin]$ ./hiveserver2
beeline => 连接 hive =》 hdfs
对hdfs 做一个设置 代理设置:
vim core-site.xml:
hadoop.proxyuser.hadoop.hosts
hadoop.proxyuser.hadoop.groups
!connect jdbc:hive2://localhost:10000 hadoop
1.开启服务常用操作
1.shell命令 去开启 某个服务
1.在当前会话直接使用脚本 =》 仅仅是测试时候使用
弊端:关闭session 那么服务就停止了
2.建议:
启动服务在后台运行
[hadoop@bigdata32 ~]$ nohup hiveserver2 &
会显示[hadoop@bigdata32 ~]$ nohup: ignoring input and appending output to ‘nohup.out’
此时 hiveserver2 就在当前session 后台运行
运行日志 在这存储nohup.out
进一步优化:
nohup hiveserver2 > ~/log/hiveserver2.log 2>&1 &
启动hiveserver2服务在后台运行,日志输出在~/log/hiveserver2.log
2>&1 => 服务日志标准输出
内部表和外部表的区别【面试】
hive/beeline:desc formatted emp;查看表相关信息
mysql:select * from TBLS \G;查看表相关信息
hive和beeline用ctrl+c来退出
内部表(MANAGED_TABLE) [受hive管控的表] 建表时默认内部表
外部表:EXTERNAL
创建一个内部表:create table emp_manager as select * from emp;
删除一个内部表:drop table emp_manager;
创建一个外部表:
create external table emp_external (
empno decimal(4,0) ,
ename string ,
job string ,
mgr decimal(4,0) ,
hiredate string ,
sal decimal(7,2) ,
comm decimal(7,2) ,
deptno decimal(2,0)
)
row format delimited fields terminated by ‘,’
stored as textfile;
create时已经将元数据和hdfs上的数据连接上了
hadoop fs -put ./emp.txt hdfs://bigdata32:9000/user/hive/warehouse/
bigdata_hive.db/emp_external
只是将数据上传到hdfs上对应存储该表数据的地方
load不仅是上传数据,还会将hdfs上数据和元数据进行关联
区别:
删除一个内部表时,表中的数据(hdfs)和元数据(mysql)都会被删除
删除一个外部表时,表中数据(hdfs)不会被删除,元数据(mysql)会被删除
重新创建create一下外部表,就可以恢复误删的外部表了
内部表和外部表的转变
alter table :
alter table table_name set tblproperties table_properties;
alter table emp_external set tblproperties (“EXTERNAL”=“false”);
alter table emp_external set tblproperties (“EXTERNAL”=“true”);
alter table emp_external set tblproperties (“external”=“false”); =》 小写不行
复杂数据类型
用的不多【中小企业,用的很多】
要求:
1.create table
2.select column
1.arrays: ARRAY
create table hive_array(
name string,
locations array<string>
)
row format delimited fields terminated by '\t' 每个字段之间以\t进行分隔
collection items terminated by ','; 集合间的元素以,进行分隔
load data local inpath ‘/home/hadoop/tmp/hive_array.txt’ into table hive_array;
1.查询每个用户第一个工作地点?A[n] 取出数组的第几位
select name,locations[0] as first_loc_work from hive_array;
2.查询每个人工作地点的数量int size(Array) =》普通函数 计算数组的长度
select name,size(locations) as cnt from hive_array;
3.查询在shanghai 工作的有哪些人? boolean array_contains
select * from hive_array where array_contains(locations,'shanghai');
select * from hive_array where array_contains(locations,'dalian');
4.解析locations 所有值
行转列
name locations
zhangsan beijing
zhangsan shanghai
zhangsan dalian
zhangsan shenyang
Lateral View 侧写视图:
lateral view udtf(expression) tableAlias as columnAlias
udtf =》传一个返回多个 =》 一进多出
from baseTable (lateralView)*
遍历输出数组
select
name,location
from hive_array lateral view explode(locations) loc_table as location;
2. maps: MAP
create table hive_map(
id int comment '用户id',
name string comment '用户名字',
relation map<string,string> comment '家庭成员',
age int comment '年龄'
)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';
load data local inpath’/home/hadoop/tmp/hive_map.txt’ into table hive_map;
1.查询表中每个人的father的名字 M[key]通过key取value
select id,name,age,relation['father'] as father from hive_map;
2.查询表中 每个人的家庭成员 keys array map_keys(Map
select id,name,age,map_keys(relation) as members from hive_map;
3.查询表中 每个人的家庭成员的名字 values 取出value
select id,name,age,map_values(relation) as members from hive_map;
4.查询表中 有brother的人以及brother的名字
select id,name,age,relation['brother'] as brother
from hive_map
where relation['brother'] is not null;
或者
select id,name,age,relation['brother'] as brother
from hive_map
where array_contains(map_keys(relation),'brother');
3.structs:STRUCT
create table hive_struct(
ip string,
userinfo struct<name:string,age:int>
)
row format delimited fields terminated by '#'
collection items terminated by ':';
load data local inpath’/home/hadoop/tmp/hive_struct.txt’ into table hive_struct;
取出结构体中的对应属性----S.x
select ip,userinfo.name as name,userinfo.age as age
from hive_struct;
分区表
表分为内部表和外部表或者普通表和分区表
内部表和外部表里面含有普通表和分区表
普通表和分区表里面含有内部表和外部表
create table order_info(
order_id string,
order_time string
)partitioned by (dt string)
row format delimited fields terminated by '\t';
导入数据
load data local inpath ‘/home/hadoop/tmp/data/order.txt’ into table order_info; 不行=》data 导入到默认分区
load data local inpath'/home/hadoop/tmp/order.txt' into table order_info partition(dt='20211014');
查看表中分区
show partitions order_info;
删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, …]
alter table order_info drop partition(dt='__HIVE_DEFAULT_PARTITION__');
hdfs上数据和mysql上的元数据都会被删除
练习操作分区
创建分区
create table emp_p(
empno decimal(4,0) ,
ename string ,
job string ,
mgr decimal(4,0) ,
hiredate string ,
sal decimal(7,2) ,
comm decimal(7,2)
)
partitioned by(deptno decimal(2,0))
row format delimited fields terminated by '\t'
stored as textfile;
导入数据 load和insert
load data local inpath “/home/hadoop/tmp/data/emp_p.txt” (overwrite) into table emp_p partition(deptno=20);
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 …)
[IF NOT EXISTS]] select_statement1 FROM from_statement;
insert into/overwrite table emp_p partition(deptno=20)
select
empno,
ename,
job ,
mgr ,
hiredate,
sal ,
comm
from emp where deptno=20;
动态导入数据
设置动态导入数据模式为非严格
set hive.exec.dynamic.partition.mode=nonstrict;
动态加载数据
insert overwrite table emp_p partition(deptno)
select
empno,
ename,
job ,
mgr ,
hiredate,
sal ,
comm ,
deptno
from emp;
静态分区和动态分区 插入数据
1.静态分区
insert overwrite table emp_p paritition(deptno=xxx)
select
xx
from emp where deptno=xxxx
2.动态分区:开启一个开关,正确的数据落到正确的分区
insert overwrite table emp_p partition(deptno)括号里面没有=的就是动态分区
select
empno,
ename,
job ,
mgr ,
hiredate,
sal ,
comm ,
20 as deptno/deptno
from emp where deptno=20;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table emp_p paritition(deptno)
select
xx
from emp;
一般生产上,离线业务:业务周期性 T+1 今天处理昨天的数据 此时静态分区和动态分区就差不多
动态:
insert overwrite table emp_p paritition(deptno)
select
xx
from emp
where dt= yestoday;
静态 :
insert overwrite table emp_p paritition(deptno='yestoday')
select
xx
from emp
where dt= yestoday;
开窗函数
指定窗口大小
select
name ,
dt ,
cnt ,
sum(cnt) over(partition by name order by dt ) as sum_cnt,
sum(cnt) over(partition by name order by dt rows between unbounded preceding and current row ) as sum_cnt2,
sum(cnt) over(partition by name order by dt ROWS BETWEEN 3 PRECEDING AND CURRENT ROW ) as sum_cnt3,
sum(cnt) over(partition by name order by dt ROWS BETWEEN CURRENT ROW AND 1 following ) as sum_cnt4
from user_mt;
还可以不指定分区----------只要不加partition by 就是作用整张表
select
name ,
dt ,
cnt ,
sum(cnt) over(partition by name order by dt ) as sum_cnt,
sum(cnt) over( order by dt ) as sum_cnt1
from user_mt;
需求: 使用sql 统计出每个用户每个月的累计访问次数
1.求出每个用户每个月的 访问次数
select
userid,
date_format(replace(dt,'/','-'),'YYYY-MM') as moth,
sum(cnt) cnt_sum
from user_log
group by
userid,date_format(replace(dt,'/','-'),'YYYY-MM');
2.基于result 进一步求 累计访问次数
select
userid,
moth,
cnt_sum,
sum(cnt_sum) over(parition by userid order by moth ) as cnt_all
from
(
select
userid,
date_format(replace(dt,'/','-'),'YYYY-MM') as moth,
sum(cnt) as cnt_sum
from user_log
group by
userid,date_format(replace(dt,'/','-'),'YYYY-MM')
) as a ;
开窗函数
函数:
1.开窗函数自带的
1.排序相关的
2.串行
2.聚合函数
rank() over(partition by xx order by xxx) as rk
row_number() over(partition by xx order by xxx) as rn
dense_rank() over(partition by xx order by xxx) as dk
select
name,
dt,
cnt,
rank() over(partition by name order by dt) as rk,
row_number() over(partition by name order by dt) as rn,
dense_rank() over(partition by name order by dt) as dk
from user_mt
rank() 从1开始 按照顺序 生产分组内记录的编号,排序相同会重复 在名次中留下空位
row_number(): 从1开始 按照顺序 生产分组内记录的编号,排序相同不会重复
dense_rank():从1开始 按照顺序 生产分组内记录的编号,排序相同会重复 在名次中不会留下空位
练习
一般思路:
1.数据清洗 etl :
1.取出需要的字段
2.取出的字段column做数据转换或者数据清洗etl
3.去重
2.数据计算
维度
指标
模板:
select
from(
select
from
) as
pv =》 页面浏览量 3个用户 每个人 访问了 10次页面 30
uv =》 访客次数 3个用户 每个人 访问了 10次页面 3
create table user_shop(
user_id string,
shop string
)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/tmp/user_shop.txt' into table user_shop;
需求: 1.每个店铺的uv
按商店分组,按用户去重
select shop,
count(distinct user_id) as cnt
from user_shop
group by shop;
或者
select
shop,
count(user_id) as uv
from(
select
shop,
user_id
from user_shop
group by shop,user_id
) as a
group by shop;
2..1每个店铺访问次数top3 的用户记录 输出: 店铺名称 访客id 访问次数
1.每个店铺访问次数
select
shop,
cnt
from(
select
shop,
count(*) as cnt
from user_shop
)as a
2.访问次数排名
select
shop,
cnt,
rank() over(order by cnt desc) as rk
from(
select
shop,
count(*) as cnt
from user_shop
)as a
3.top3 店铺名字 访问次数 排名
select
shop,
cnt,
rk
from(
select
shop,
cnt,
rank() over(order by cnt desc) as rk
from(
select
shop,
count(*) as cnt
from user_shop
group by shop
)as a
) as a
where rk < 4;
2.2店铺名称 访客id 访问次数 top3
1.每个店铺每个访客id访问次数
select
shop,
user_id,
cnt
from(
select
shop,
user_id,
count(*) as cnt
from user_shop
group by shop,user_id
) as a
2.访问次数排名
select
shop,
user_id,
cnt,
rank() over(partition by shop order by cnt desc) as rk
from(
select
shop,
user_id,
count(*) as cnt
from user_shop
group by shop,user_id
) as a
3.top3 店铺名称 访客id 访问次数
select
shop,
user_id,
cnt,
rk
from(
select
shop,
user_id,
cnt,
rank() over(partition by shop order by cnt desc) as rk
from(
select
shop,
user_id,
count(*) as cnt
from user_shop
group by shop,user_id
) as a
) as a
where rk < 4;
维度组合分析 sql 关键字 grouping sets
四个字段能排除2^4个分组=16,其中有一个为空
创建表
create table user_shop_log(
user_id string,
shop string,
channle string,
os string
)
row format delimited fields terminated by ',';
导入数据
load data local inpath'/home/hadoop/tmp/user_log.txt' into table user_shop_log;
select
shop,
user_id,
channle,
os
from user_shop_log
group by
shop,
user_id,
channle,
os
grouping sets(
(shop),
(shop,user_id),
(shop,channle),
(shop,os),
(shop,user_id,channle),
(shop,user_id,os),
(shop,channle,os),
(shop,user_id,channle,os),
(user_id),
(user_id,channle),
(user_id,os),
(user_id,channle,os),
(channle),
(channle,os),
(os)
);
列转行和行专列
create table t1(
name string,
interesting string
)
row format delimited fields terminated by ',';
load data local inpath'/home/hadoop/tmp/t1.txt' into table t1;
行转列:
select name,location
from hive_array lateral view explode(locations) loc_table as location;
列传行:
聚合函数:array collect_set(col) 集合里的数据不可重复
聚合函数:array collect_list(col) 集合里的数据可重复
select
name,
collect_list(interesting) as interestings
from t1
group by name;
// zuan ["王者荣耀","吃饭","rap","唱歌"]
更改数组元素的分隔符
拼接:
1.string concat =》 字符串拼接
select concat("tom","|","jack","|","marry");
// tom|jack|marry
2.string concat_ws(string SEP, string A, string B…(可变参数)) =》 字符串拼接
select concat_ws("|","tom","jack","marry");
// tom|jack|marry
可变参数 =》 array【String】
select split(“a,a,a”,‘,’);返回一个数组 [“a”,“a”,“a”]
select concat_ws(“|”,split(“a,a,a”,‘,’)); a|a|a
select
name,
collect_list(interesting) as interestings,
concat_ws("|",collect_list(interesting)) as interestings_blk
from t1
group by name;
zuan ["王者荣耀","吃饭","rap","唱歌"](数组) 王者荣耀|吃饭|rap|唱歌(字符串)
字段类型转换
任何数据类型都可以转化为string类型 字符串函数最多
如果是数值类型但是用string存的,四则运算是可以的,hive底层进行了优化
select “1”+“2”;=》3,但是会影响排序
举例:1000 1500 100 900 9000
数值降序排序:9000 1500 1000 900 100
字符串排序: 按照字典序进行排序的 a-z
9000 900 1500 1000 100
解决思路:(1)修改表结构
(2)类型转换
cast(expr as )
create table t2(
sql string
);
load data local inpath'/home/hadoop/tmp/t2.txt' into table t2;
select
cast(sql as bigint) as sql_alias
from t2
order by sql_alias;
// 100 900 1000 1500 9000
四大by–order by,sort by,cluster by,distribute by
order by 全局排序 reduce只有一个,reduce阶段仅仅有一个task进行处理,性能不高(不影响用)
安全模式防止一些危险查询(生产上一般需要关闭)
当安全模式开启时,order by需要加上limit使用
partition分区需要加上where使用
select * from emp order by empno;
set hive.mapred.mode;
set hive.mapred.mode=strict;
select * from emp order by empno;(order by直接查询失败)
select * from emp order by empno limit 10;
set hive.mapred.mode=nonstrict;
select * from emp order by empno;
select * from emp_p;(分区表直接查询失败)
select * from emp_p where deptno=20;
sort by 分区排序 reduce task个数按照reduce有多少个进行排序的 不能保证全局有序
hive里面reduce task个数默认为-1,会自动改变,hadoop里reduce task默认是1
set mapred.reduce.tasks=2;
insert overwrite local directory ‘/home/hadoop/tmp/sortby’
select * from emp sort by empno;会输出2份,每份内都是排好序的
[hadoop@bigdata12 sortby]$ ll
总用量 8
-rw-r–r–. 1 hadoop hadoop 654 12月 3 16:48 000000_0
-rw-r–r–. 1 hadoop hadoop 350 12月 3 16:48 000001_0
在reduce task分区内进行排序的
reduce task个数决定了输出个数
如果 你的reduce task 个数是1 order by 和sort by 效果是一样的
Distribute By 数据分发
Distribute By意思是把我的数据发送到哪个分区,按照分区发送到哪个reduce task上,发送完之后按照sort by进行分区排序
select col1,col2 from t1 distribute by col1
select col1,col2
from t1
distribute by col1 sort by col1 asc,col2 desc;
map阶段到reduce阶段默认是按照hash,为了防止数据倾斜(一个map或者reduce处理很多,另一个map或者reduce处理很少),我们可以指定分发
create table hive_distribute(
year string,
earing string
)
row format delimited fields terminated by ',';
load data local inpath'/home/hadoop/tmp/distribute.txt' into table hive_distribute;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/hadoop/tmp/distribute'
select * from hive_distribute distribute by year sort by earing;
//-rw-r--r--. 1 hadoop hadoop 36 12月 3 17:13 000000_0
//-rw-r--r--. 1 hadoop hadoop 34 12月 3 17:13 000001_0
//-rw-r--r--. 1 hadoop hadoop 37 12月 3 17:13 000002_0
Cluster By是distribute by和sort by的简写
distribute by year sort by year 《=》 Cluster By year 正确
当distribute by xxx和sort by xxx后面指定相同时,就等同于cluster by xxx
分桶表
普通表 路径
分区表 路径
分桶表: hdfs上的文件基于分区表或者普通表
create table hive_bucket(
id int,
name string
)
clustered by (id) into 4 buckets
row format delimited fields terminated by ',';
set mapred.reduce.tasks=-1;
load data local inpath'/home/hadoop/tmp/bucket.txt' into table hive_bucket;
mapreduce: hash之后 % 余上reducetask个数
文件存储格式 (和压缩要区分开)
1.行式存储:
1.一行内容所有的列都在一个 block里面
2.里面的列 掺杂很多数据类型
2.列式存储
按照列进行存储

行式存储:
1.行式存储加载所 是把所有的列都查询出来 再过滤出 用户需要的列
2.如果用户 仅仅查几个字段 =》 磁盘io 开销比较大
常见行式存储有哪些:
1.text file 文本文件
2.SequenceFile 文本文件(生产上基本不用,占存储空间)
SequenceFile 性能比text file性能好一丢丢,如果底层存储是使用 SequenceFile实际存储文件会比text file文件要多一点点,因为它要查询做过滤加一些额外的东西提升性能
列式存储:
1.RCFile =》 行 =》 列 (初期行式存储往列式存储转变,现在基本不用)
2.ORC Files + Parquet
适用场景: 查询几个列 比行式存储节省了IO的开销
弊端: 加载表中所有字段
create table hive_distribute_col(
year string,
earing string
)
row format delimited fields terminated by ','
stored as orc;
insert into table hive_distribute_col
select *
from hive_distribute;
列式存储文件 数据量 比 行式存储的数据量少 【前提 都采用压缩】
数据类型相同时,压缩会更节省空间
Function:
1.内置function
2.udf
1.内置function
show functions like upper; => hive内置函数是否有 upper
desc function extended upper; =》 查看uppper 函数详细使用
1.1时间相关函数
yyyy-MM-dd HH:mm:ss
1.current_date => 打印当前时间 select current_date; 2022-12-28 yyyy-MM-dd
2.current_timestamp => 打印当前时间戳 select current_timestamp; 2022-12-28 18:47:41.23
3.unix_timestamp => 日期转成 秒值【1970】
1.打印当前时间的时间戳 select unix_timestamp(); 1672224550 秒值 long
2.传入一个date =》 秒值
select unix_timestamp(‘2022-12-28 00:00:00’);
select unix_timestamp(‘2022-12-28’,‘yyyy-MM-dd’);
4.from_unixtime => 秒值 =》 日期格式
select from_unixtime(1,‘yyyy-MM-dd HH:mm:ss’); 1970-01-01 00:00:01
select from_unixtime(1672224790,‘yyyy-MM-dd HH:mm:ss’); 2022-12-28 10:53:10
5.to_date => 年月日 select to_date(‘2022-12-28 19:23:59’); 2022-12-28
6.year select year(‘2022-12-28’); 2022
quarter(季度) select quarter(‘2022-12-28’); 4
month select month(‘2022-12-28’); 12
day select day(‘2022-12-28’); 28
hour select hour(‘2022-12-28 19:37:30’); 19
minute select minute(‘2022-12-28 19:38:30’); 38
7.months_between select months_between(‘2022-12-28’,‘2022-10-28’); 2.0 查看日期相差几个月
add_months select add_months(‘2022-12-28 19:52:30’,-2); 2022-10-28 添加月份
select add_months(‘2022-12-28 19:54:30’,1,‘yyyy-MM-dd HH:mm’); 2023-01-28 19:54
datediff select datediff(‘2022-12-28’,‘2021-12-20’); 373 查看日期相差的天数
8.date_add select date_add(‘2022-12-28’,3); 2022-12-31
date_sub select date_sub(‘2022-12-28’,5); 2022-12-23
last_day select last_day(‘2022-12-28’); 2022-12-31 返回这个月的最后一天 注意日期格式
9.date_format 日期格式 select date_format(‘2022-12-28 20:19:20’,‘yyyy-MM-dd HH’); 2022-12-28 20
1.2算术相关函数
1.round 四舍五入:select round(3.8769123,3); 3.877
2.ceil 向上取整 >= select ceil(4.56);5 select ceil(-7.6);-7 select ceil(5);5
3.floor 向下取整 <= select floor(5);5 select floor(3.14);3 select floor(-3.14);-4
4.rand() (0,1)
select rand(); 0.45868403341590114
select 10rand(); 7.314893834590635
select round(10rand()); 6.0
1.3字符串相关函数
upper select upper(‘abc’); ABC
lower select lower(‘ABC’); abc
length select length(‘dl2262’); 6
trim 去掉前后的空格,不能去掉中间的空格 select trim(’ ab c d e ‘); ab c d e
lpad 左边补全 select lpad(‘hi’,6,’?'); ??_hi select lpad(‘hi’,1,‘>?’);h
rpad 右边补齐 select rpad(‘hi’,8,‘<>'); hi<><*>
replace/ regexp_replace
select replace(‘hi and hello’,‘h’,‘H’); Hi and Hello
select regexp_replace(‘dl2262’,’[0-9]‘,‘num’); dlnumnumnumnum
select regexp_replace(‘dl2262’,’[0-9 || a-z]‘,‘num’); numnumnumnumnumnum
substr 字符串截取 select substr(‘Facebook’,5,4); book select substr(‘Facebook’,-5);ebook
concat 字符串拼接 select concat(‘a’,’,‘,‘b’,’,‘,‘c’); a,b,c
concat_ws 字符串拼接 select concat_ws(’,‘,array(‘a’,‘b’,‘c’)); a,b,c
split 字符串分割 select split(‘oneAtwoBthreeC’, ‘[ABC]’); [“one”,“two”,“three”,“”]
select split(‘192.168.41.110’,’\.'); [“192”,“168”,“41”,“110”]
1.4json数据处理
1.get_json_object ok
2.json_tuple 首选
3.udf函数
create table move_json(
json string
);
load data local inpath "/home/hadoop/data/rating.json" into table move_json;
select
json_tuple(json,'movie','rate','time','userid') as (movie,rate,`time`,userid)
from move_json limit 10;
select
get_json_object(json,'$.movie') as movie
from move_json limit 10
select
get_json_object(json,'$.store.fruit.weight') as weight
from json02
select
get_json_object(json,'$.store.bicycle.color') as color
from json02
1.普通的json
2.嵌套json:
1.数组 :
多个元素+struct
2.struct:
kv
3.不规则json : udf
2.parse_url_tuple => 解析url会用到
https://cwiki.apache.org/course?a=b&c=d
select parse_url_tuple('https://cwiki.apache.org/course?a=b&c=d',"HOST","PATH","QUERY");
1.5判断类function
1.case when
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
When a = true, returns b; when c = true, returns d; else returns e
2.if()
需求:每个部门 男女生各有多少人?
select
dept,
sum(case when gender='男' then 1 else 0 end) as male_cnt,
sum(case when gender='女' then 1 else 0 end) as female_cnt
from emp_info
group by dept;
select
dept,
sum(if(gender='男',1,0)) as male_cnt,
sum(if(gender='女',1,0)) as female_cnt
from emp_info
group by dept;
udf
hive、sparksql
内置函数:不能够解决某些业务场景
udf 一进一出 upper lower :
1.extends UDF
2.实现 evaluate
udaf 多进一出 sum max
udtf 一进多出 explode
public class UDFHello extends UDF {
public String evaluate(String input){//object
return "hello:"+input;
}
// 测试
public static void main(String[] args) {
UDFHello udfHello = new UDFHello();
System.out.println(udfHello.evaluate("xxx"));
}
3.使用:
1.打包上传服务器
1.临时函数 【推荐】
add jar /home/hadoop/lib/dl2262-hive-udf-1.0.jar;
create temporary function hello_udf as 'com.dl2262.UDFHello';
show functions like hello_udf;
select hello_udf(name) as etl_name from emp_info;
注意:
仅仅是当前session有效
另外一种使用方式;
1.把自己开发jar =》 hive目录下 auxlib下面
add jar =》 可以省略 直接创建临时函数即可使用
HIVE_AUX_JARS_PATH
create temporary function hello_udf as 'com.dl2262.UDFHello';
show functions like hello_udf;
select hello_udf(name) as etl_name from emp_info;
2.永久函数【不建议使用】
create function [db_name.]function_name as class_name
[using jar|file|archive 'file_uri' [, jar|file|archive 'file_uri'] ];
create function hello_udf02 as 'com.dl2262.UDFHello' using jar 'hdfs://bigdata12:9000/udf-lib/dl2262-hive-udf-1.0.jar';
drop function [if exists] hello_udf02;
如何使用:
1.hive -e “sql”
hive -f xx.sql [推荐]
2.hive -i xx.sql [hive session 初始化用的] 【推荐】
hive -i -f
vim init.sql
add jar /home/hadoop/lib/dl2262-hive-udf-1.0.jar;
create temporary function hello_udf as 'com.dl2262.UDFHello';
hive -i ./init.sql
select hello_udf('abc');
hive调优【面试】
问题:谈谈你再工作中针对SQL(hive、sparksql…)的优化 ,做的好的3个点?
1.结合场景 + 数据量:
调优前 vs 调优后 的对比情况
2.常见的调优点: groupby join count(distinct ) =》 shuffle =》 数据倾斜
shuffle:根据 map输出的key进行数据分发 各自的reducer上去的
数据倾斜 =》 倾斜在key上
3.没有一劳永逸的调优
1.fetch抓取策略
符合抓取策略 =》 不走mr
hive.fetch.task.conversion
Default Value: minimal in Hive 0.10.0 through 0.13.1, more in Hive 0.14.0 and later
none: Disable hive.fetch.task.conversion (value added in Hive 0.14.0 with HIVE-8389)
minimal: SELECT *, FILTER on partition columns (WHERE and HAVING clauses), LIMIT only
more: SELECT, FILTER, LIMIT only (including TABLESAMPLE, virtual columns)
2.本地化执行
决策 =》hive引擎自己去判断
hive.exec.mode.local.auto =》 开关
hive.exec.mode.local.auto.inputbytes.max =》 按照加载的数据量
hive.exec.mode.local.auto.tasks.max =》按照task
hive.exec.mode.local.auto.input.files.max =》按照文件加载的个数
3.模式限制
hive.mapred.mode严格模式strict和非严格模式nonstrict
In strict mode,full table scans are prevented 分区表(需要加过滤条件)and ORDER BY (只有一个reduce task)requires a LIMIT clause.
4.推测式执行
1.假设 node1 node2 node3 机器上运行我们的task
2.假设node3机器负载比较高
场景1:
某个时刻、某个节点 负载比较高: cpu使用率比较高、mem被别的作业占用比较多
思考:
task1 和task2 很快运行完成了 ,但由于 node3负载高 ,task3运行比较慢
=》 “木桶效应/短板效应 ” “桶中能装多少水是由最短的这块板来决定的 ”
大数据里:一个job跑完需要耗费多长时间 由最慢的一个task来决定的
hadoop{mR} hive spark…
内部都有一个机制:推测式执行 去解决这个问题
推测式:
1.node3节点上task 跑了 “一定时间”时
会在另外一个节点上页启动一个相同的task 【node5】
这个task3 同时运行在node3节点 node5上 ,谁先跑完 就采用谁的结果 同时kill掉另外一个task
mapreduce:
mapreduce.map.speculative
mapreduce.reduce.speculative
hive:
hive.mapred.reduce.tasks.speculative.execution
5.裁剪 【了解】
hive.optimize.cp =》 是否开启列裁剪
hive.optimize.ppd 谓词下压
eg: table:emp ,columns: a,b,c,d,e
select a,b,c from emp ; 查询只需要3个字段
- 行式存储 文件无法进行列裁剪 一定是加载全部表中字段
- 列式存储 : orc、parquet 列式存储的文件 可以进行列裁剪的 节省 网络io和磁盘io
hive.optimize.ppd 谓词下压 =》 节省 网络io和磁盘io 【减少首次加载的数据量】
谓词: 条件相关的东西 where on
下压:取数据从数据源头取数 先过滤会减少数据量的加载
要求:table : 列式存储,直接where某个字段,会直接定位到该位置
6.设置 map task数量 和 reduce task 数量
1.设置 map task 数量
map task 个数 取决于 切片的个数
mapreduce.input.fileinputformat.split.minsize
mapreduce.input.fileinputformat.split.maxsize
map task数量越多越好吗 ? 越多可能有什么问题?
mapreduce作业:进程级别 task,一个task对应一个jvm启动运行销毁的,task越多代表jvm开启越多,是比较耗费资源的
2.设置reduce task个数 reduce 个数 决定了 最终文件的个数
set hive.exec.reducers.bytes.per.reducer=<number>
set hive.exec.reducers.max=<number>
set mapreduce.job.reduces=<number>
1.用户指定 :
set mapreduce.job.reduces =》 reduce task个数
2.用户设置参数 hive引擎自己去算
set hive.exec.reducers.bytes.per.reducer =》 每个reduce 处理的数据量
set hive.exec.reducers.max =》 reduce task最多有多少个
reduce数据设置? 按照你的作业复杂度 最终输出文件大小来确定 => 如果设置不合理会出现小文件问题
hive 小文件合并问题?
Q1: 为什么说hdfs 不适合处理/存储小文件?
1.从存储角度来说,如果hdfs存储过多小文件,每个小文件都是有自己的元数据的,会增加namenode的压力
2.处理角度:一个小文件对应一个task进行处理
Q2: 如何合并小文件 ?
1. hdfs api 来完成 =》 行式存储
github.com
2.hive 里面支持 DDL
Alter Table/Partition Concatenate =》 合并小文件命令
前提:table 存储 orc存储 =》 列式存储
3.减少reduce task个数 set参数
4.spark api coalsce repartition
5.spark sql hint语法 coalsce
alter table stu_info_orc concatenate;
每隔几天做个小文件合并
7.并行执行
mr: 可以以 任务链chain方式去运行 job,一个作业可以拆分成很多个阶段
mr1=》mr2 => mr3 [explain查看执行计划的功能,查看一个job究竟走了多少map reduce以及map reduce之间有没有依赖关系]
hive : sql =>mr
sql的复杂度 不一样 =》 翻译成 mr的个数 以及依赖 都不一样的
EXPLAIN: 查看sql 执行计划
1.The Abstract Syntax Tree for the query 【sql的语法树 现在不显示了】
2.The dependencies between the different stages of the plan 【一个job 分为多个stage】
3.The description of each of the stages 【每个stage详细信息】
explain
select
a.*,
b.*
from user_click as a left join product_info as b
on a.product_id=b.product_id;
一个sql 可以转换成多个mr job
1.可能是串行执行
2.也可能是并行执行
假如sql =》 4个job
1 2 3 job是没有任何依赖关系的
前提:资源够 并行跑 一般性能会好一些的
1.并行执行的参数【一般不开启】
hive.exec.parallel =》 false 开关
hive.exec.parallel.thread.number =》 运行并行跑的job数
8.数据倾斜
1.什么是数据倾斜?
RT2和RT3 处理的数据的时间会很短
RT1 待处理的数据量过多【数据倾斜】,可能会导致什么问题?
1.处理速度慢 能跑完
2.由于数据倾斜 跑不完 【99%】
数据倾斜?
就是由于某个或者某几个 key对应的数据量过大 从而导致对应的task处理非常慢 或者运行报错
导致的原因?
只有shuffle才有可能导致数据倾斜
join(没有reduce的join不会导致数据倾斜的)、groupby 、count(distinct)
解决:
1.group by
map端输出的某些key 数据量过大 =》 skew 【数据倾斜 】
解决思想: “先打散,再聚合”
hive:
1.参数来解决
hive.groupby.skewindata => sql处于数据倾斜是 会优化 groupby
hive.map.aggr => map端开启一个聚合
2.不通过参数,用户自己定义的 udf函数
1.一个mr作业:
两个mr作业 解决数据倾斜的问题
udf:
add_suffix
pre_suffix
select
pre_suffix(n_deptno) as pre_deptno,
sum(cnt) as cnt_sum
from
(
select
add_suffix(deptno) as n_deptno,
count(1) as cnt
from emp
group by add_suffix(deptno)
) as a
group by pre_suffix(n_deptno);
2.count(distinct)
distinct => job只有一个 task ,只有一个reduce task来完成 =》 必然导致数据倾斜问题
设置reduce 个数 是没有用的
解决: group by
3.join
1.shuffle join/ mapreduce join 普通join
2.map join =》不走reduce 不会导致数据倾斜
a 表 b 表 得有一个表是小表
1.map join:
1.参数设置
set hive.auto.convert.join=true;
select
a.*,
b.*
from user_click as a left join product_info as b
on a.product_id=b.product_id limit 2;
2.hints写法: sparksql 也有这种写法 好用的
set hive.auto.convert.join=true;
select /*+ MAPJOIN(product_info) */
a.*,
b.*
from user_click as a left join product_info as b
on a.product_id=b.product_id
limit 2;
1.普通join 导致数据倾斜 如何解决? 工作遇到了 可能low怎么解决
2. 直接抽取 skew数据
sql:
2个sql :
1sql =》 skew key join
2sql =》 no skew key join
加前缀
@Description(name = "add_prefix",
value = "_FUNC_(input, random_limit) - "
+ "Returns add random num prefix string",
extended = "Example:\n > SELECT _FUNC_('abc', 5) FROM src LIMIT 1;\n" + "3_abc"
+ "\n > SELECT _FUNC_('abc', 5) LIMIT 1;\n"
+ "1_abc.\n")
public class UDFAddRandomPrefix extends UDF {
public String evaluate(Object input,Integer limit){//object
int num = new Random().nextInt(limit) + 1;
return num+"_"+input;
}
public static void main(String[] args) {
UDFAddRandomPrefix udfAddRandomPrefix = new UDFAddRandomPrefix();
System.out.println(udfAddRandomPrefix.evaluate("abc", 10));
}
}
add jar /home/hadoop/lib/dl2262-hive-udf-1.0.jar.1;
create temporary function add_prefix as 'com.dl2262.UDFAddRandomPrefix';
减前缀
@Description(name = "remove_prefix",
value = "_FUNC_(input) - "
+ "Returns remove random num prefix string",
extended = "Example:\n > SELECT _FUNC_('123_abc') FROM src LIMIT 1;\n" + "abc"
+ "\n > SELECT _FUNC_('abc_123') LIMIT 1;\n"
+ "123\n")
public class UDFRemovePrefix extends UDF {
public String evaluate(String input){//object
return input.split("_")[1];
}
public static void main(String[] args) {
UDFRemovePrefix udfRemovePrefix = new UDFRemovePrefix();
System.out.println(udfRemovePrefix.evaluate("123_abc"));
}
}
add jar /home/hadoop/lib/dl2262-hive-udf-1.0.jar.0;
create temporary function remove_prefix as 'com.dl2262.UDFRemovePrefix';