Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Hanzhe Hu1, Shuai Bai2, Aoxue Li1, Jinshi Cui1, Liwei Wang1
1Key Laboratory of Machine Perception (MOE), School of EECS, Peking University 北京大学 机器感知重点实验室 2Beijing University of Posts and Telecommunications 北京邮电大学
published on cvpr2021
问题提出
-
深度cnn的成功很大程度上依赖于ImageNet等大规模数据集,这些数据集能够训练深度模型。当标记的数据变得稀少时,cnn会严重的过拟合和不能泛化。
-
在小样本检测中,如果出现遮挡或者外观变化等问题,如果没有足够的特征支持,模型将无法学习类别信息和边界框预测的关键特征。 导致误分类和漏检
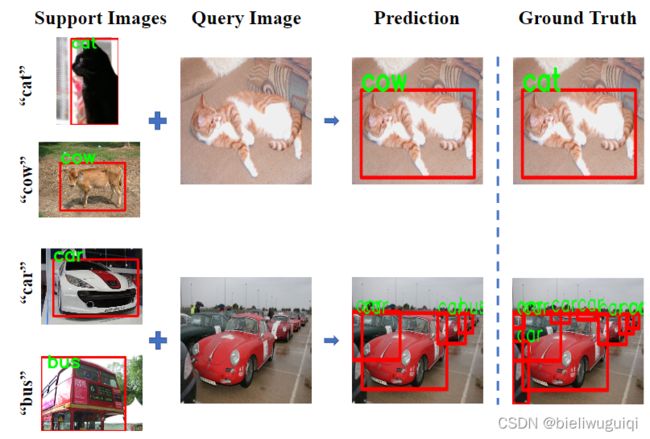
解决方法
-
使用稠密关系蒸馏模块用于检测问题,其目标是充分利用支持信息来辅助检测过程。
-
自适应上下文感知特征聚合模块,更好地捕捉全局和局部特征,缓解尺度变化问题,提高小样本检测性能。
DCNet
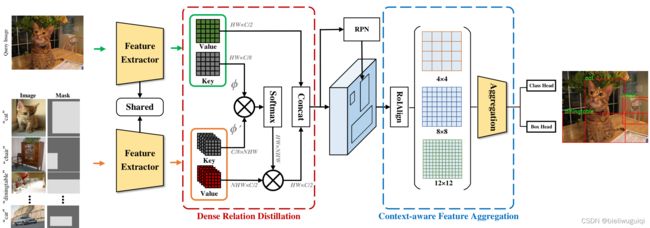
-
查询编码器和支持编码器采用相同的结构,但不共享参数
Dense Relation Distillation Module(DRD)
稠密关系蒸馏模块
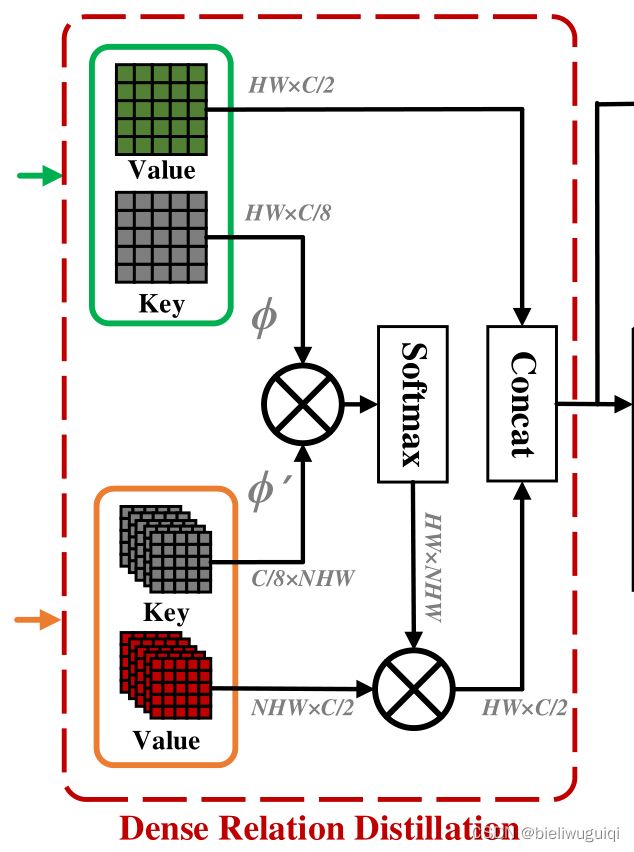
-
编码器以一个或多个特征作为输入,为每个输入特征输出两个特征映射:key和value;
-
使用两个并行的3×3卷积层,以降低输入特征的维数,节省计算成本;
-
key用于度量查询特征和支持特征之间的相似性,这有助于确定在哪里检索相关的支持特征。
-
学习key以编码视觉语义以进行匹配,并学习value以存储详细信息以供识别。
![]()
![]()
Context-aware Feature Aggregation Module (CFA)
自适应上下文感知特征聚合模块

RoI Align模块以RPN和特征为输入,进行特征提取,进行最终的类预测和边界盒回归。
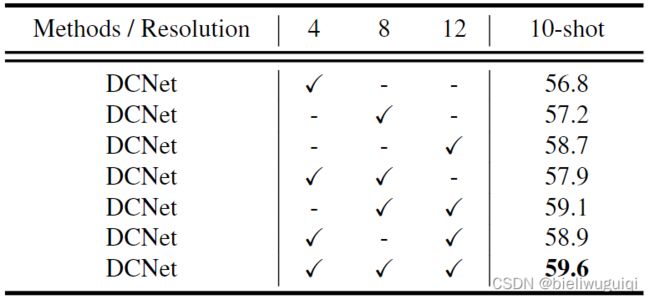
作者认为,通常,在研究中,RoI Align是用8*8来进行池化的,这很可能会在训练过程中造成信息丢失。对于一般的目标检测,这种信息丢失可以通过大量的训练数据来弥补,而在训练数据很少的情况下,这一问题就变得更加严重,容易引起检测结果的误导。(此外,由于小样本的性质,尺度变化被放大,模型往往失去了对新类的泛化能力,对不同尺度的适应能力较强。)为此,作者提出上下文感知的特性聚合(CFA)模块。不使用固定的分辨率8,而是选择4、8和12三个分辨率,进行并行池化操作,以获得更全面的特征表示。
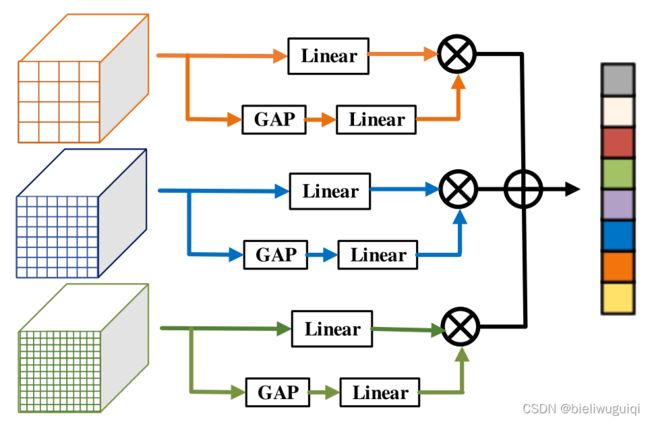
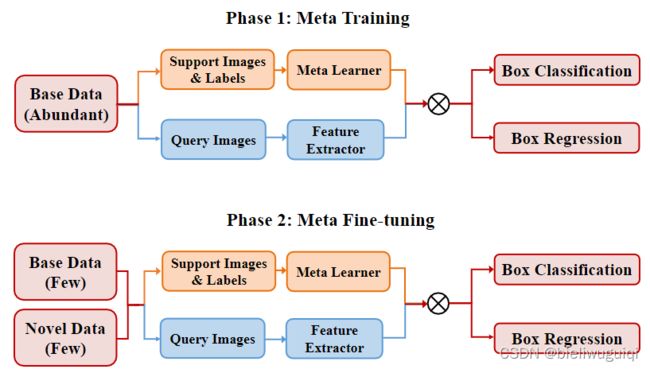
在meta-training阶段,提供了丰富的base data。对特征提取器、稠密关系提取模块、上下文感知特征聚合模块等检测模型的基本组件进行了联合训练。
在meta fine-tuning阶段,我们对模型进行了base data和novel data的训练。由于只有k个标记的bounding-boxes 可用于novel data,为了平衡来自base data和novel data的样本,我们还为每个base data包含了k个bounding-boxes。训练过程与meta-training阶段相同,但模型收敛的迭代次数较少。
PASCAL VOC dataset (20 classes)
novel classes for four splits:
{“bird”, “bus”, “cow”, “motorbike” (“mbike”),“sofa”},
{“aeroplane”(“aero”), “bottle”, “cow”, “horse”,“sofa”},
{“boat”, “cat”, “motorbike”, “sheep”, “sofa”}
k is set as 1/3/5/10
MS COCO dataset (80 classes)
novel classes:
20 classes in PASCAL VOC dataset
k is set as 10/30
Comparisons with State-of-the-art Method
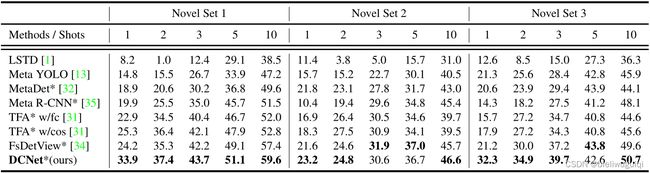
-
mAP with IoU threshold0.5 (AP50)
-
PASCAL VOC dataset
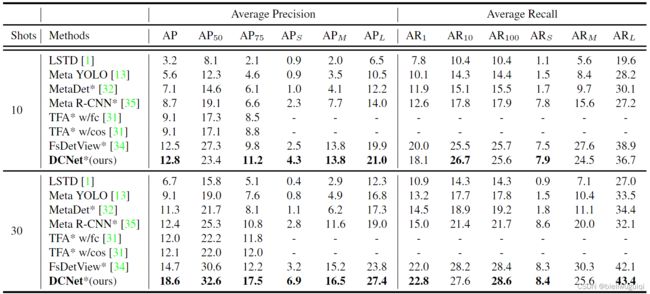
-
COCO dataset
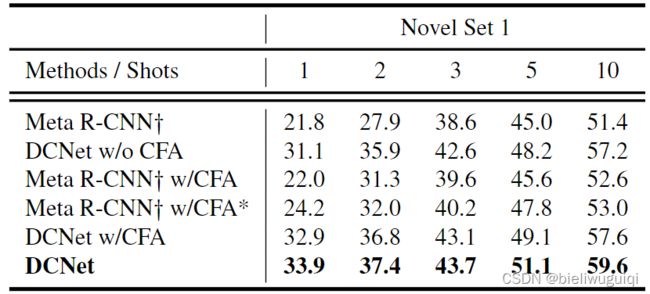
Ablation Study
Qualitative Results