黑马程序员2023新版JavaWeb企业开发全流程学习笔记(涵盖Spring+MyBatis+SpringMVC+SpringBoot等)
目录
- 零、Web开发
- 一、HTML-CSS
-
- 初识Web前端
-
- Web前端课程安排
- 小结
- HTML、CSS介绍
- HTML快速入门
- HTML小结
- VS Code开发工具
- 基础标签 & 样式-合集(拟新浪微博为例)
-
- 标题
-
- 排版
- 样式
- 超链接
- 正文
-
- 排版
- 布局
- 表格、表单标签
-
- 表格标签
- 表单标签
-
- 表单项
- 二、JavaScript
-
- JS基本介绍
- JS引入方式
- JS基础语法
-
- 书写语法
- 变量
- 数据类型、运算符、流程控制语句
-
- 数据类型
- 运算符
- 流程控制
- JS函数
- JS对象
-
- Array
- String
- JSON
-
- JS自定义对象
- JSON-介绍
- JSON-基础语法
- BOM
-
- Window
- Location
- DOM
- JS事件监听
-
- 事件绑定
- 常见事件
- 三、Vue
-
- Vue简介(插值表达式)
- Vue使用方式
- Vue常用指令
- Vue生命周期
- 三-四、(Ajax、Ajax-Axios2、前后端分离开发、前端工程化、Element)
-
- Ajax前言
- 同步与异步
- Ajax
-
- 原生Ajax
- Axios
-
- Axios的使用
- 前端工程化
-
- 前后端分离开发
- 接口文档管理平台:YAPI
- 前端工程化-环境准备(Vue脚手架的基本环境)
- 前端工程化-Vue项目简介(基于Vue脚手架创建一个工程化的Vue项目&介绍项目的目录结构)
- 前端工程化-Vue项目开发流程(介绍工程化Vue项目的开发流程)
- 四、Maven
- 五、数据库-MySQL
- 六、Mybatis
- 七、SpringBootWeb
- 八、Maven高级
零、Web开发
- Web:全球广域网,也称为万维网(www World Wide Web),能够通过浏览器访问的网站
- Web 网站的开发模式
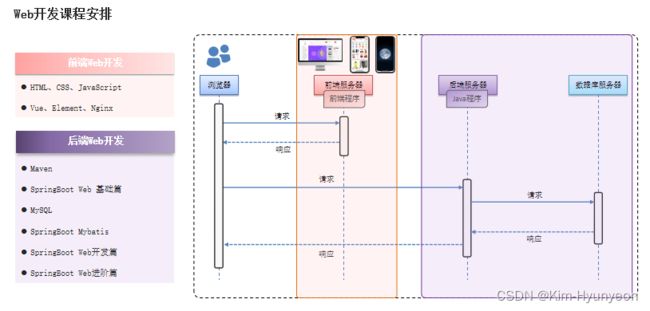
① 前后端分离开发 浏览器请求访问前端服务器,前端服务器接受到请求后会将对应的前端代码返回给浏览器(也就是图中的响应请求)。而我们知道浏览器也是一个程序,在浏览器里面内置了解析前端代码的解析引擎。那在浏览器接收到前端代码以后会自动解析前端的代码,从而展现出对应的页面样式。而现在浏览器解析的前端代码会呈现出基本的网页结构,但并没有数据。所以接下来就会去获取数据,而在前端代码中都会指定去哪里获取数据,如下图红框部分就是获取数据的请求路径。将来浏览器解析到前端代码当中的这个数据获取路径以后,浏览器就会拿着这个路径去访问部署在后端服务器当中的后端Java程序。那后端程序呢继续访问数据库,数据获取之后,后端服务器会将数据再返回给浏览器。那此时前端代码和数据就都有了,浏览器就会将数据填充在刚才的空架子的前端页面当中,从而形成了一个完整的页面呈现给用户。这就是 Web 网站前后端分离开发的整体工作流程。
浏览器请求访问前端服务器,前端服务器接受到请求后会将对应的前端代码返回给浏览器(也就是图中的响应请求)。而我们知道浏览器也是一个程序,在浏览器里面内置了解析前端代码的解析引擎。那在浏览器接收到前端代码以后会自动解析前端的代码,从而展现出对应的页面样式。而现在浏览器解析的前端代码会呈现出基本的网页结构,但并没有数据。所以接下来就会去获取数据,而在前端代码中都会指定去哪里获取数据,如下图红框部分就是获取数据的请求路径。将来浏览器解析到前端代码当中的这个数据获取路径以后,浏览器就会拿着这个路径去访问部署在后端服务器当中的后端Java程序。那后端程序呢继续访问数据库,数据获取之后,后端服务器会将数据再返回给浏览器。那此时前端代码和数据就都有了,浏览器就会将数据填充在刚才的空架子的前端页面当中,从而形成了一个完整的页面呈现给用户。这就是 Web 网站前后端分离开发的整体工作流程。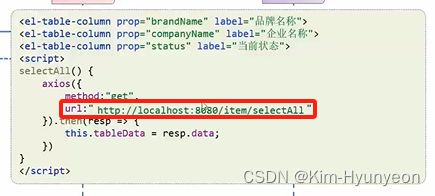
② 混合开发
市场调研结果 结果显示,混合开发的项目占比仅为26.56%;而前后端分离开发的项目占比已经高达73.44%,且这个比重仍在增加。
结果显示,混合开发的项目占比仅为26.56%;而前后端分离开发的项目占比已经高达73.44%,且这个比重仍在增加。
- Web开发课程安排
一、HTML-CSS
初识Web前端
提示:不同的浏览器,内核不同,对于相同的前端代码解析的效果会存在差异.
那么为了使不同浏览器解析同一段前端代码解析出来的效果是一样的,因此就需要定一套标准。即有了这套标准后,只需让所有浏览器厂商都来参照这个标准来进行开发就可以了。而这个标准其实早就已经制定好了,就是Web标准,如下图。
① W3C这个联盟的主要职责就是来指定Web标准的
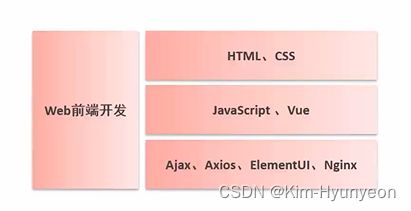
② 前端网页开发的三剑客:HTML、CSS、JS
③ 前端网页开发除了这三项基础的核心技术以外,现在还有非常流行的一些高级的技术。如:前端开发现在非常流行的基于JS封装的高级框架Vue,还有像基于Vue封装的桌面端组件库Element UI以及异步交互技术Ajax和Axios等技术
Web前端课程安排
小结

HTML、CSS介绍

补充:像我们平时基于Windows当中的记事本这一类工具所编写的这一类文本都称为普通文本,即只能记录文字信息
回顾:XML也是一种标记语言,即由标签构成的语言。XML是可扩展的标记语言,即在XML当中我们可以自定义一堆的标签,将来在解析时,只需要按照我们自己定义的规则去解析这些标签当中的内容就可以了。但HTML当中的标签都是预先定义好的,因为HTML的代码最终是不需要我们来解析,而是要在浏览器当中来运行,由浏览器来负责解析HTML代码的。那么当浏览器在解析时,一旦见到某一个标签,就会知道这一块的内容我该如何展示。如:一看到这个标签就知道这一块的文本是要加大加粗展示的,一旦看到标签就知道要展示出某个对应的图片
HTML快速入门

DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>testtitle>
head>
<body>
body>
html>
HTML小结

VS Code开发工具


基础标签 & 样式-合集(拟新浪微博为例)
标题
排版

样式


超链接

正文
排版

布局

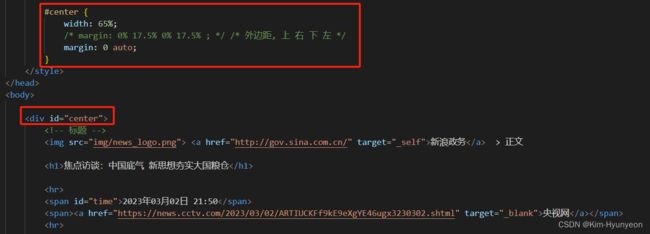
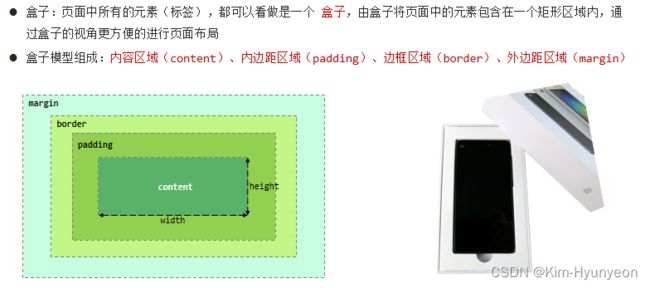 我们想要基于盒子模型来完成页面布局,还需要借助HTML中两个比较常见的布局标签来完成,分别是:div和span标签
我们想要基于盒子模型来完成页面布局,还需要借助HTML中两个比较常见的布局标签来完成,分别是:div和span标签

想要实现如上图版心居中需要利用div标签进行CSS盒子模型的样式设计,如下图代码所示:

表格、表单标签
表格标签

表单标签

HTTP请求中GET和POST的区别?
①参数传递的方式不同
GET方法请求的时候,参数会拼接到URL的后面,参数之间以&相连,如:login.php?username=xx&password=x,请求参数会暴露在浏览器中,所以是一种不安全的请求方式,多用来 获取数据。
POST方法请求的时候,参数会放到HTTP的请求体中,对于用户是不可见的。虽然请求参数对于用户是不可见的,但是对于浏览器而言仍然是可见的。我们可以通过浏览器的开发者模式查看POST的请求体,所以POST方法也是不安全的。
②URL长度不同严格来说
GET方法和POST方法的请求参数长度都是没有限制的,HTTP协议中并没有规定参数的长度。但是,在浏览器和WEB容器中有限制,主要是为了提高URL解析的效率。一般浏览器规定GET请求的时候,URL长度不能大于2000个字符,POST请求的数据不能大于4M。当然不同的浏览器和服务器限制条件不同。所以,为了兼容大多数的浏览器和服务器,URL参数保证在2000个字符以内,这样,对于服务器的压力也小,可以提升系统的性能。
③安全性不同
GET方法的请求的时候,参数暴露在浏览器中,用户可以明显地看到参数,这是不安全的请求方式。
POST请求的时候,参数随请求体传递。POST方法相对GET方法安全一些,但不是绝对的。通过抓包方式也是可以查看POST的请求参数的。
④数据包不同
GET请求的时候,产生一个TCP数据包。请求的header和data一起发送出去。
POST请求的时候,产生两个TCP数据包。先发送header信息,服务端响应100 continue,浏览器再发送data信息。
所以说,GET请求的性能要高于POST请求。但是这种差别几乎可以忽略不计。因为网络良好的情况下,两次包发送的时间几乎等于发送一次包的时间(tcp包)。而且,在某些浏览器下,POST请求也只发一次请求(Firefox)。
表单项

二、JavaScript
JS基本介绍

补充:JavaScript是一门脚本语言,即,将来JavaScript编写出来的代码是不需要经过编译的,直接经过浏览器的解释就可以运行了。那么像Java语言还需要经过编译,将编写好的源代码.java文件要编译成字节码.class文件,然后再由虚拟机去运行。而像JavaScript这种语言是不需要的,这样就简化了整个的开发过程,因为不需要编译。
JS引入方式

补充:自闭合标签 指的是没有内容【没有内容的意思是不需要用一对儿标签去包裹文字之类的】并且不需要使用闭合标签的元素。以下是一些常见的HTML自闭合标签及其代码示例:
1.标签:用于在文本中插入换行符。
2.
标签:用于在文档中插入水平线。
3.标签:用于插入图像。
4.标签:用于创建输入字段。
5.标签:用于引入外部CSS样式或者网页图标。
6.标签:用于描述HTML文档的元数据。
7.标签:用于定义图像映射中的可点击区域。
这些是一些常见的HTML自闭合标签,它们用于插入单个元素或者定义文档的元数据。一般情况下,这些标签不需要闭合标签,因为它们被设计成直接自闭合的。





JS基础语法
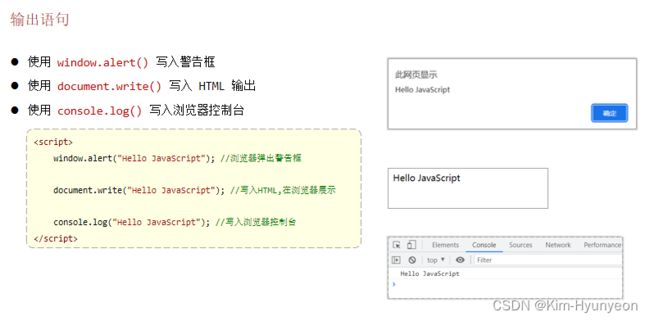
书写语法

变量

数据类型、运算符、流程控制语句
数据类型

关于null:

运算符

流程控制

JS函数


JS对象
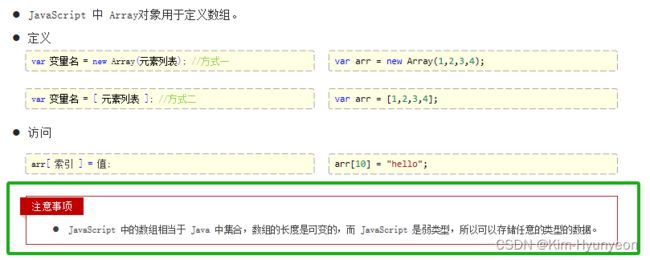
Array

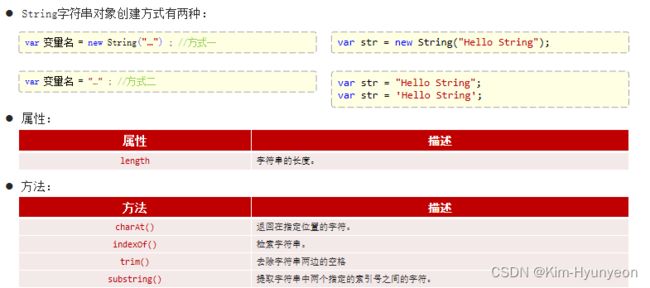
String
JSON
JS自定义对象

JSON-介绍
Json的数据格式与上面自定义对象的形式基本一致,只不过在Json的数据格式当中,要求所有的Key必须要使用双引号将其引起来。
需要注意的是Json本身是一个文本,所以Json格式的数据本质就是一个字符串。
Json用途:相比于XML这个数据载体来说,Json格式的数据更简洁明了(XML在传递数据的时候会非常的臃肿,数据是没多少但标签一大堆,所以在现在的前后端交互过程中一般使用Json数据格式)。

JSON-基础语法
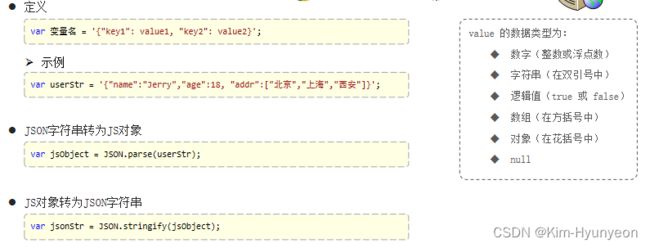
BOM

Window
Location

DOM


1.Core DOM是针对于任何标记语言的标准模型,无论是HTML还是XML都包含这些标准的DOM对象
2.XML DOM是Core DOM的子集,定义了操作XML文档的标准模型
3.HTML DOM是在Core DOM的基础上 进行了扩充 ,其实在HTML DOM当中,它是将所有的HTML标签都封装成了一个单独的元素对象。如它封装成了Image这么一个对象;而(input标签所定义的button按钮)也封装成了一个对象:Button对象

JS事件监听

事件绑定
事件绑定:
 使用事件监听绑定事件(两种方式):addEventListener() 和 attachEvent()
使用事件监听绑定事件(两种方式):addEventListener() 和 attachEvent()
<button id="btn">点我~</button>
<script>
btn.addEventListener("click",function(){
alert("我是被监听的btn~");
},false);
btn.attachEvent("onclick",function(){
alert("我是被监听的btn2~");
})
</script>
事件绑定与事件监听的区别:
事件绑定只能为一个元素的相同事件绑定一个响应函数,后面绑定的响应函数会覆盖之前绑定的响应函数。
事件监听可以为一个元素的相同事件同时绑定多个响应函数,当事件被触发时,响应函数将会按照函数的绑定顺序执行。
事件监听有两种方式:addEventListener() 和 attachEvent()
addEventListener() 和 attachEvent() 区别:
(1) 兼容性
attachEvent:兼容:IE7、IE8;不兼容firefox、chrome、IE9、IE10、IE11、safari、opera
addEventListener 兼容:firefox、chrome、IE、safari、opera;不兼容IE7、IE8及以下
(2) 执行顺序
addEventListener( ) :当事件被触发时,响应函数将会按照函数的绑定顺序执行
attachEvent( ): 当事件被触发时,响应函数将会按照与函数绑定顺序相反的顺序执行(与addEventListener相反)
事件监听的优点:
1、可以绑定多个事件
2、可以解除相应绑定
解除绑定
addEventListener( ) 事件:
<button id="btn">点我~</button>
<script>
function tag(){
alert("tag2");
}
btn.addEventListener("click",function(){
alert("tag1");
},false);
btn.addEventListener("click",tag2,false);
btn.addEventListener("click",function(){
alert("tag3");
},false);
btn.removeEventListener("click",tag2,false);// here here~~
</script>
执行结果:
tag1
tag3
attachEvent( )事件:
<button id="btn">点我~</button>
<script>
function tag(){
alert("tag2");
}
btn.attachEvent("onclick",function(){
alert("tag1");
})
btn.attachEvent("onclick",tag)
btn.attachEvent("onclick",function(){
alert("tag3");
})
btn.detachEvent("onclick",tag);// here here~~
</script>
执行结果:
tag3
tag1
常见事件
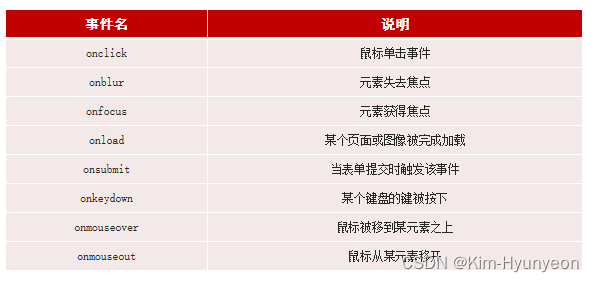
三、Vue
Vue简介(插值表达式)
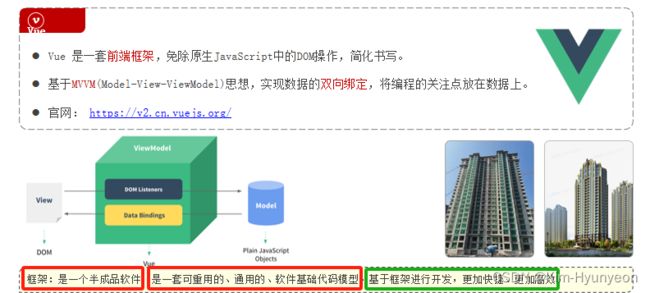
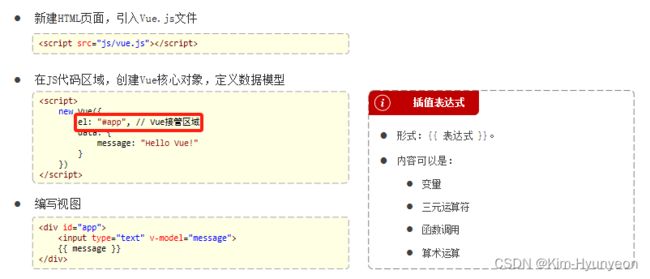
Vue使用方式
有两种方案:
一、将Vue当作js使用,只需要在页面上引入js即可。比较简单。
二、使用脚手架,需要下载node.js等工具或框架的支持,比较复杂,功能更强大。
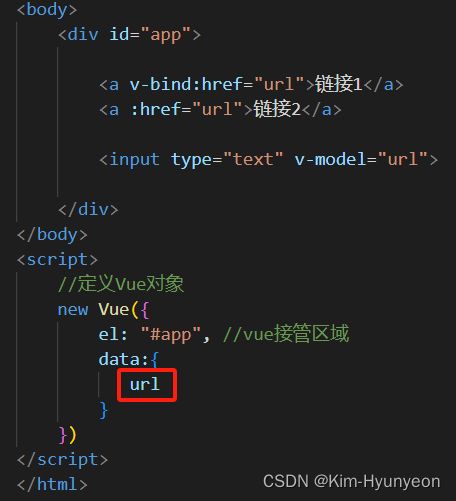
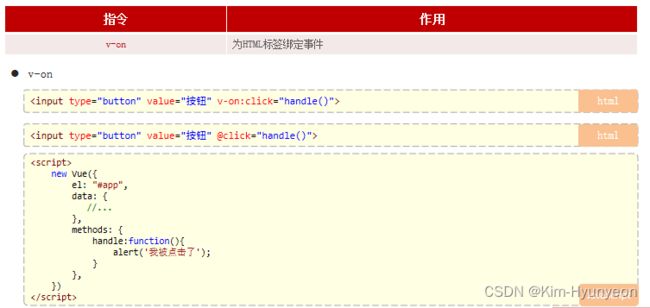
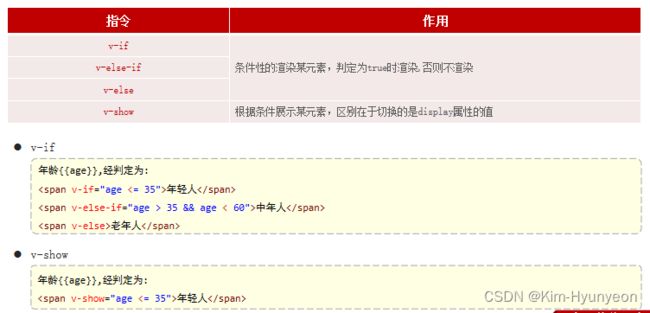
Vue常用指令


可以放空字符串①,但是不可以只声明变量不传值②或只声明变量和冒号③(后者属于语法错误了),如下图:
①
②
③



Vue生命周期
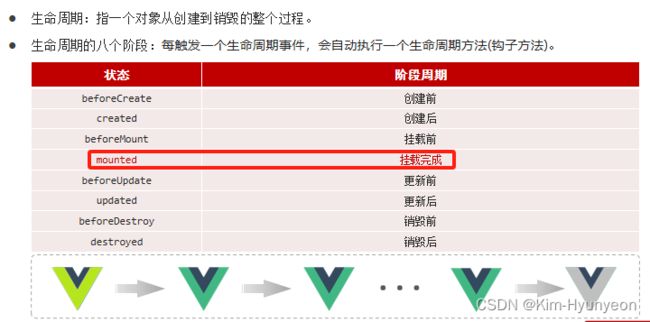
那生命周期的这八个阶段分别代表的是什么意思呢?又在什么时候要来执行生命周期的八个钩子方法呢?下面来看一下官方给的这幅图:
作为Java程序员,我们主要掌握一个钩子方法即可,即:mounted 挂载完成。因为将来我们需要在 mounted 这个钩子方法当中来发送请求到服务端来获取数据。

三-四、(Ajax、Ajax-Axios2、前后端分离开发、前端工程化、Element)
Ajax前言
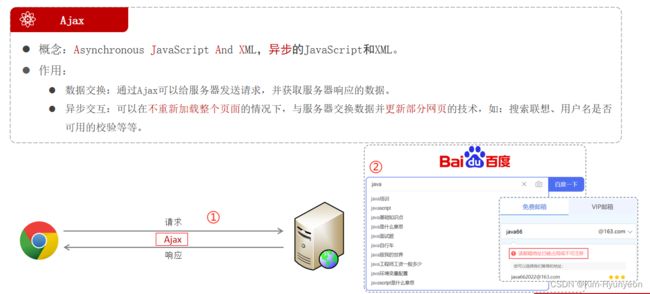
同步与异步

在同步操作中,当服务器在处理逻辑时,客户端处于等待状态。直到服务器为客户端响应数据后,客户端才可以执行其它操作。如:在浏览器地址栏输入一个域名去访问某一个网站时,可能会存在网速慢而加载不出来的情况。此时点击浏览器页面的其它位置也不会有任何反应,只有等到页面完全加载出来之后才可以继续操作,这就是同步
但是在异步操作中,当服务器在处理逻辑时,客户端也可以继续执行其它操作,不需要等待服务器响应客户端
Ajax
原生Ajax
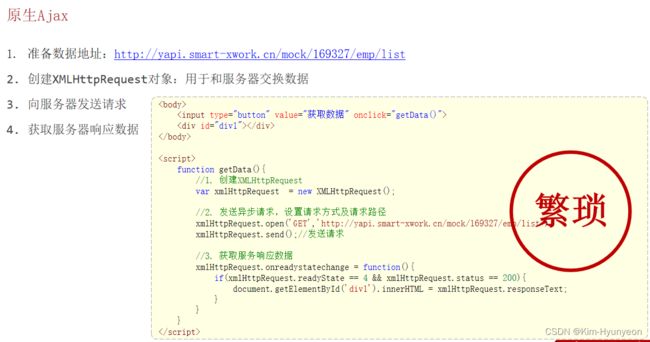
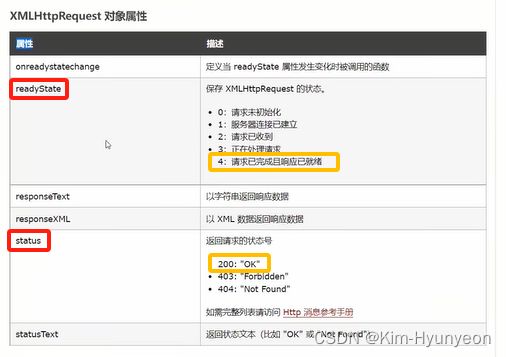
可以在W3C官网内查看Ajax使用的详细规则等内容
XHR为XMLHttpRequest的缩写形式,代表的就是一次异步请求
Axios
原生的Ajax比较繁琐,且在早期浏览器中还存在浏览器兼容的问题。所以在现在的项目开发当中,原生的方式已经基本不用了。而现在项目当中使用的是基于原生的Ajax封装的技术,如:Axios

Axios的使用
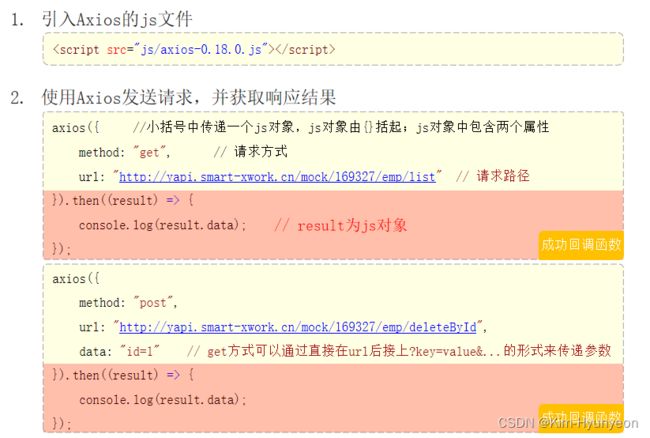
简化改造:

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Ajax-Axios-案例</title>
<script src="js/axios-0.18.0.js"></script>
<script src="js/vue.js"></script>
</head>
<body>
<div id="app">
<table border="1" cellspacing="0" width="60%">
<tr>
<th>编号</th>
<th>姓名</th>
<th>图像</th>
<th>性别</th>
<th>职位</th>
<th>入职日期</th>
<th>最后操作时间</th>
</tr>
<!-- v-for遍历展示数组 -->
<!-- emp指代遍历出来的元素;而emps指代的是要遍历展示的数组;index代表的是遍历的索引,从0开始 -->
<tr align="center" v-for="(emp,index) in emps">
<!-- 通过插值表达式来输出每一项的数据 -->
<td>{{index + 1}}</td>
<td>{{emp.name}}</td>
<td>
<img :src="emp.image" width="70px" height="50px">
</td>
<td>
<span v-if="emp.gender == 1">男</span>
<span v-if="emp.gender == 2">女</span>
</td>
<td>{{emp.job}}</td>
<td>{{emp.entrydate}}</td>
<td>{{emp.updatetime}}</td>
</tr>
</table>
</div>
</body>
<script>
// 当加载本html页面时,会自动创建Vue对象;
new Vue({
el: "#app",
data: {
// Vue当中的数据模型
emps:[]
},
// Vue对象创建完毕并且挂载完成以后,它会自动触发mounted钩子函数
mounted () {
//发送异步请求,加载数据
axios.get("http://yapi.smart-xwork.cn/mock/169327/emp/list").then(result => {
// this代表的就是当前Vue对象
this.emps = result.data.data;
})
}
});
</script>
</html>
前端工程化
前后端分离开发
在早期前后端混合开发项目过程中,开发人员既需要使用前端的技术栈来开发前端的功能,后需要使用java的技术栈来编写后端的功能实现,还需要操作数据库。这种方式就是将前后端代码全部都写在一个工程当中。
在这种开发模式下,其实也有少量的前端开发师,其主要职责就是开发静态的html页面并将开发好的html页面提供给后端开发人员。后端人员则需要直接基于这套html页面模板进行改造,与服务器端进行交互并完成页面的渲染和展示。那如果后端开发人员发现html页面有问题,再反馈给前端进行修改。那在这种开发模式当中就要求后端开发人员既需要熟悉前端开发的技术栈也需要熟悉服务器端开发的技术栈。
以上就是早期的前后端混合开发,它主要会存在以下几个问题:
- 沟通成本比较高(后端人员在使用html页面模板时,一旦发现模板有问题,就得反馈给前端让前端进行修改。前端修改完成之后要再交给后端人员进行使用,所以沟通成本比较高)
- 分工不明确(后端开发人员既需要开发前端的功能实现,还需要开发服务器端的功能。那这也就意味着在一个项目当中很难培养出专业性的人才,因为开发人员的精力都是有限的)
- 不便于管理(所有代码都写在了一个工程当中。此时这个前端可能包含了PC端和移动端,那如果后面需求增加了,需要再增加一端小程序端,就需要在原有的代码基础上再来进行改动。那这个操作其实并不方便。)
- 不便于后期的维护和扩展(同不便于管理的理由)
而在现在主流的开发模式-前后端分离开发模式中会将一个项目拆分为两个部分。一个称为前端工程,另外一个称之为后端工程。前端工程由专业的前端开发人员负责开发,而后端工程由专业的后端开发人员负责开发。最后开发好的前端工程要与后端程序进行交互,我们就可以在前端工程当中发起异步请求来请求后端工程,那后端工程接收到这个请求之后进行处理,处理完毕之后再给前端工程返回一个响应结果。那么在这种模式当中,前端程序和后端程序都是由独立的团队进行开发的。那前后端程序要想最终能够正常的交互对接起来,他们在进行开发的时候就必须要遵守某种开发规范。而这种开发规范是需要定义在一份专门的文档当中,即接口文档。【这里的接口指的是一个业务功能,比如添加员工就是一个功能,也就是一个接口;再比如删除员工也是一个功能,也是一个接口。所以一个业务功能就是一个接口。 】
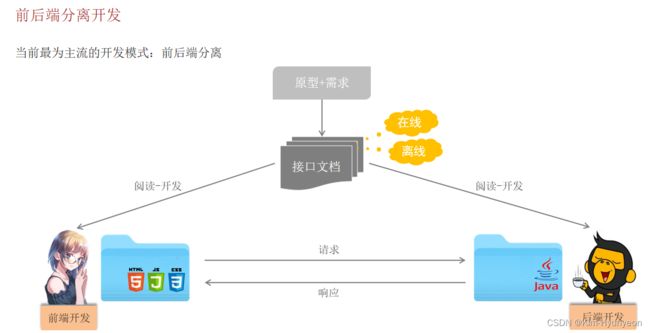
而有了这份儿文档后,前后端的开发人员就可以基于接口文档进行开发,接口文档描述了这个接口在请求的时候需要传递什么参数。后端需要什么样的参数,前端开发工程师就给后端传递对应的参数就可以了;后端也只需要根据接口文档当中所描述的形式来接收参数即可。然后当后端处理完了之后,再按照接口文档当中所描述的规范来给前端响应对应的数据。前端开发工程师再根据接口文档当中所描述的响应数据的格式,再来进行数据的解析就可以了。
倘若前后端开发工程师都严格的遵循了同一份接口文档,那最终他们所开发出来的前端工程和后端工程是可以无缝集成在一起的。

上述提到的接口文档维护的方式其实有很多,主要分为两类:一类是在线的方式;一类是离线的方式。在线的方式可以通过一些在线的接口文档管理平台进行维护;那离线的方式指的是可以在word的markdown或excel当中来定义这份接口文档。
接口文档是怎么来的,由谁定义的,依据什么定义的?
接口文档是由产品经理所提供的页面原型以及需求文档分析而来的
-
页面原型

-
需求文档

在这种开发模式下,要开发某一块功能,具体的开发流程如下:首先我们先得熟悉业务需求;然后依据页面原型和需求文档要定义出一份api接口文档;前后端开发人员遵守接口文档当中的规范并行开发;前后端开发人员分别测试相应的代码;最后进行前后端的联调测试(前端工程调用后端工程)

接口文档管理平台:YAPI
- 介绍:YApi 是高效、易用、功能强大的 api 管理平台,旨在为开发、产品、测试人员提供更优雅的接口管理服务
- 地址: http://yapi.smart-xwork.cn/
可以在公司内部署一份或使用YAPI公网注册一个账号使用 - 功能:API接口管理;Mock服务
Mock服务指的就是可以通过YAPI来模拟真实的接口,生成接口的模拟测试数据,用于前端工程测试【即,即使后端的接口还没有开发完毕,前端人员也可以使用YAPI当中所提供的mock地址来进行模拟数据的测试】 - 使用

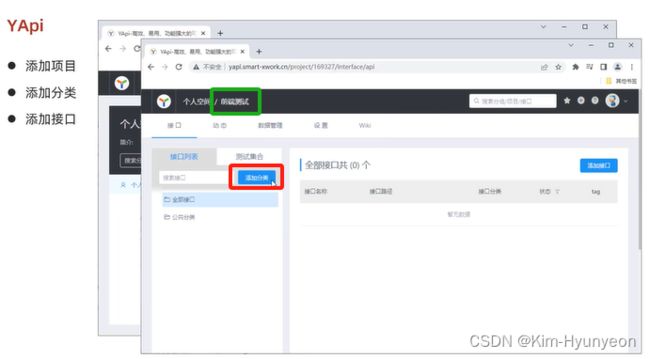
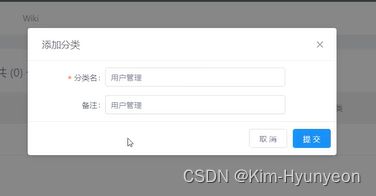


这样接口的基本信息就已经填写好了
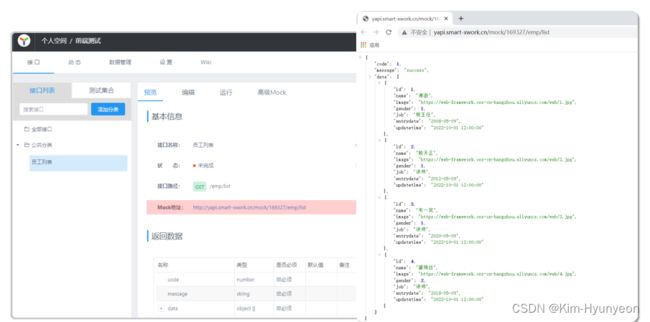
之后可以在编辑中完善接口的信息;除了基本信息,还有两个较为重要的信息,分别是:请求参数设置和返回数据设置


接口一旦管理好后,YAPI会自动生成一个mock地址,这个mock地址就可以在前端人员测试时供给其使用。浏览该地址会自动返回一个json格式数据
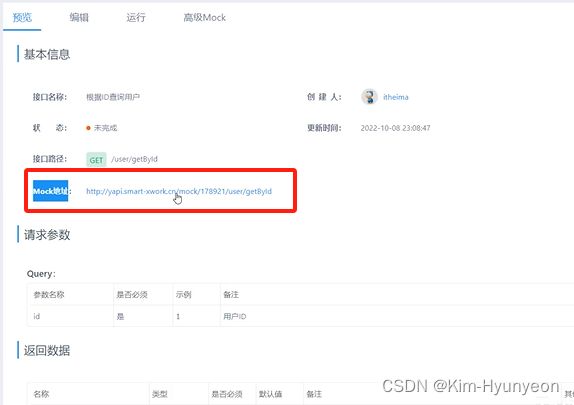

高级mock可以设置你期望返回的值


前端工程化-环境准备(Vue脚手架的基本环境)
前期开发过程中都是需要什么样的资源就引入什么样的资源并使用,从而形成一个工程结构

上面这种工程结构在开发大型项目中,存在很多问题:每次开发一个功能都是从零开始;多个页面当中的组件或者功能复用性并不好;js、图片资源文件没有规范化的存储目录,在团队协作开发时不便于项目的维护和项目的管理。所以在现在的前端开发当中,都讲究前端开发的模块化、组件化、规范化、自动化-这些组成了前端工程化开发。前端工程化: 是指在企业级的前端项目开发中,把前端开发所需的工具、技术、流程、经验等进行规范化、标准化,从而来提升前端工程的开发效率和提升前端工程的产品质量,降低开发难度和开发成本。

在使用了前端工程化以后,利用Vue开发大型项目时就需要考虑代码的目录结构、项目结构要考虑部署以及代码的单元测试等事情。为了提高效率,通常会使用一些现成的工具来帮助我们完成这些事情。这个工具就是Vue官方提供给的脚手架工具。
vue-cli:
- 介绍: Vue-cli 是Vue官方提供的一个脚手架,用于快速生成一个 Vue 的工程化项目模板
- Vue-cli提供了如下功能:
1.统一的目录结构
2.本地调试
3.热部署(应用程序的代码变动了,但我们不需要再次运行,就可以加载最新的程序)
4.单元测试
5.集成打包上线 - 依赖环境:NodeJS (前端工程化的运行环境,类似Java程序运行需要用到JDK的环境)