Spark-SQL 相关
相关链接
- DESCRIBE TABLE
https://spark.apache.org/docs/3.3.2/sql-ref-syntax-aux-describe-table.html
SQL concept
SQL(Structure Query Language)结构化查询语言
-
DQL(data query language)数据查询语言 select操作。
DQL即数据查询语言,实现数据的简单查询,主要操作命令有select where等,可以在查询时对数据进行排序,分组等操作。 -
DML(data manipulation language)数据操作语言,主要是数据库增删改三种操作
-
DDL(data definition language)数据库定义语言,主要是建表、删除表、修改表字段等操作
-
DCL(data control language)数据库控制语言,如commit,revoke之类的,在默认状态下,只有 sysadmin,dbcreator,db_owner db_securityadmin等人员才有权力执行DCL
Basic SQLs
val df = spark.sql("SELECT ceil(cast(l_orderkey as int)) from lineitem limit 1")
WITH AS
WITH AS短语,也叫做子查询部分,定义一个SQL片断后,该SQL片断可以被整个SQL语句所用到。有的时候,with as是为了提高SQL语句的可读性,减少嵌套冗余。
with A as (
select *
from user
)
select *
from A, customer
where
customer.userid = user.id**
先执行select * from user把结果放到一个临时表A中,作为全局使用。
with as的将频繁执行的slq片段加个别名放到全局中,后面直接调用就可以,这样减少调用次数,优化执行效率。
Window keyword
select * from
(
select *,row_number() over w as row_num,
from order_tab
WINDOW w AS (partition by product_id order by amount desc)
)t ;
window关键字的作用就是为当前窗口起别名。在本语句中,将当前窗口命名为w。
该语句的含义为按照product_id进行分组,并在组内根据amount值进行降序排列。
SQL
createTable
spark.catalog.createTable("table11", "file:///mnt/DP_disk1/table11", "parquet")
或
spark.catalog.createTable("table11", "file:/mnt/DP_disk1/table11", "parquet")
show create
spark-sql> show create table tbl_3742;
22/03/25 04:16:12 WARN hdfs.DFSClient: Slow ReadProcessor read fields took 139323ms (threshold=30000ms); ack: seqno: 33 reply: SUCCESS reply: SUCCESS downstreamAckTimeNanos: 537810 flag: 0 flag: 0, targets: [DatanodeInfoWithStorage[10.1.2.206:50010,DS-bc41e0d4-869a-4c25-a60f-492cff4e62ca,DISK], DatanodeInfoWithStorage[10.1.2.207:50010,DS-28aa5320-0828-440b-ad0c-511ef32e628c,DISK]]
CREATE TABLE `arrow_bytedance`.`tbl_3742` (
`col_76332` BIGINT,
`col_72588` STRING,
`col_60802` STRING,
`col_10061` BIGINT,
`date` STRING,
`live_id` BIGINT)
USING arrow
LOCATION 'hdfs:/bytedance_tables_10k_rows_Dec_17/tables/tbl_3742.parquet'
spark-sql> show create table table11;
CREATE TABLE `default`.`table11` (
`col2371` STRING,
`col2203` STRING,
`col2151` STRING,
`col2126` STRING,
`col2183` STRING,
`col2313` STRING,
`col2362` STRING,
`col2384` STRING,
`col2345` STRING,
`col2225` STRING,
`rand` DOUBLE)
USING parquet
LOCATION 'file:/mnt/DP_disk1/table11'
show create database
desc database du_shucang;
Namespace Name shucang
Comment
Location cosn://xxx/usr/hive/warehouse/shucang.db
Owner hadoop
Time taken: 0.108 seconds, Fetched 4 row(s)
其它关键字查询
spark-sql>
> describe student;
id int
name string
age int
Time taken: 0.075 seconds, Fetched 3 row(s)
spark-sql>
> show columns from student;
id
name
age
Time taken: 0.051 seconds, Fetched 3 row(s)
ALTER TABLE
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table RECOVER PARTITIONS").show
}catch{
case e: Exception => println(e)
}
}
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table SET LOCATION '$data_path/$table'").show
}catch{
case e: Exception => println(e)
}
}
窗口函数, Window
窗口函数用于解决排名问题
- 排名问题:每个部门按业绩来排名
- Top N 问题:找出每个部门排名前 N 的员工
窗口函数的基本语法
<窗口函数> over (partition by (用于分组的列名) order by (用于排序的列名))
常见窗口函数
- 专用窗口函数:rank、dense_rank、row_number 等
- 聚合函数:sum、avg、count、max、min
窗口函数是对 where 或者 group by 子句处理后的结果进行操作。所以窗口函数原则上只能用在 select 子句中。
使用
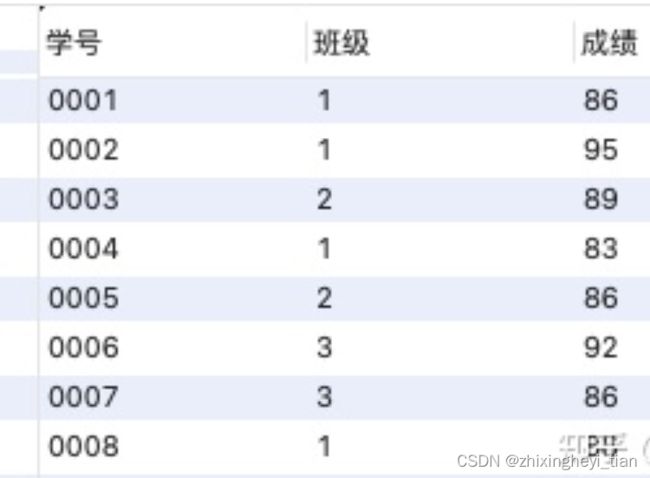
select *, rank() over(partition by 班级 order by 成绩 desc) as ranking
from 班级表;
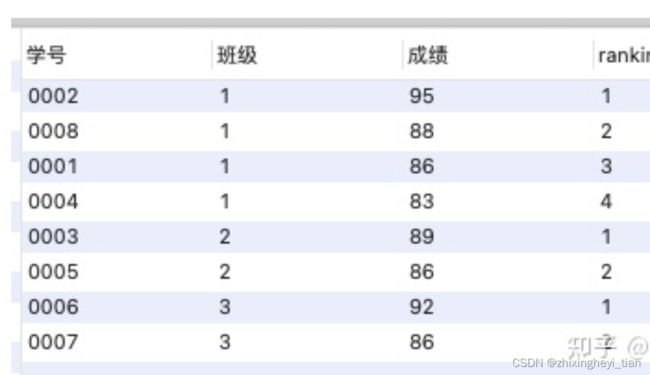
group by 分组汇总后改变了表的行数,一行只有一个类别
partition by 和 rank 函数不会减少原表中的行数
select 班级,count(学号)
from 班级表
group by 班级;

select 班级,count(学号) over (partition by 班级 order by 班级) as current_count
from 班级表;
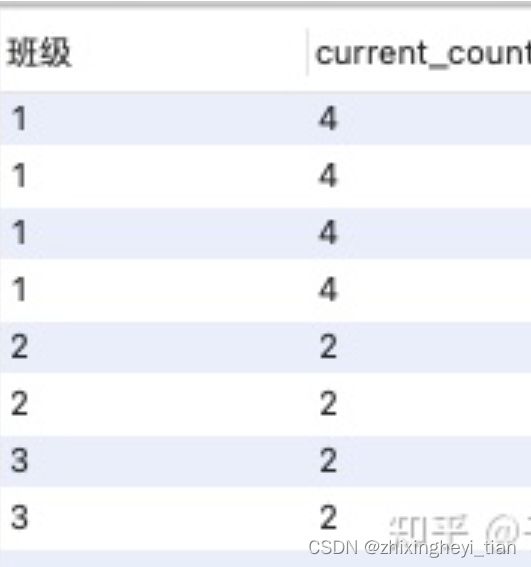
总之,窗口函数
- 同时具有分组和排序的功能
- 不减少原表的行数
- 语法为:<窗口函数> over (partition by (用于分组的列名) order by (用于排序的列名) )
专用窗口函数 rank、dense_rank、row_number 区别
- rank 函数:有并列名次的行,会占用下一名次的位置。例如,正常排名是:1、2、3、4,但是现在前 3 名是并列的名次,结果就是
1、1、1、4。 - dense_rank 函数:如果有并列名次的行,不占用下一名次的位置。例如,正常排名是:1、2、3、4,但是现在前 3 名是并列的名次,结果就是 1、1、1、2。
- row_number 函数:不考虑并列名次的情况。例如,前 3 名是并列的名次,排名结果就是正常的 1、2、3、4。
SQL functions
头尾函数
头尾函数 first_value() 和 last_value() 主要用于获取分组字段内的第一个值或最后一个值,部分情况下相当于 max 或 min
nth_value 函数
nth_value()函数用于返回分组内到当前行的第N行的值。如果第N行不存在,则函数返回NULL。
N必须是正整数,例如1,2和3
having :SQL19 分组过滤练习题
取出平均发贴数低于5的学校或平均回帖数小于20的学校
限定条件:平均发贴数低于5或平均回帖数小于20的学校,avg(question_cnt)<5 or avg(answer_cnt)<20,聚合函数结果作为筛选条件时,不能用where,而是用having语法,配合重命名即可;
按学校输出:需要对每个学校统计其平均发贴数和平均回帖数,因此group by university
select
university,
avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from user_profile
group by university
having avg_question_cnt<5 or avg_answer_cnt<20
不同大学的用户平均发帖情况,并按照平均发帖情况进行升序排列
select university,
avg(question_cnt) as avg_question_cnt
from user_profile
group by university
order by avg_question_cnt
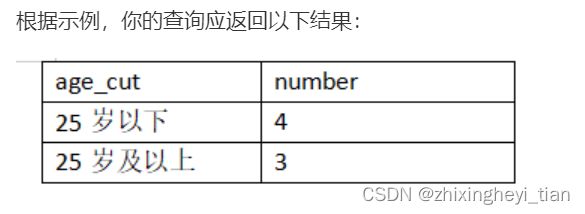
划分为25岁以下和25岁及以上两个年龄段
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END age_cut,COUNT(*)number
FROM user_profile
GROUP BY age_cut
LATERAL VIEW Clause
The LATERAL VIEW clause is used in conjunction with generator functions such as EXPLODE, which will generate a virtual table containing one or more rows. LATERAL VIEW will apply the rows to each original output row.
Syntax
LATERAL VIEW [ OUTER ] generator_function ( expression [ , ... ] ) [ table_alias ] AS column_alias [ , ... ]
Parameters:
- OUTER
If OUTER specified, returns null if an input array/map is empty or null.
- generator_function
Specifies a generator function (EXPLODE, INLINE, etc.).
- table_alias
The alias for generator_function, which is optional.
- column_alias
Lists the column aliases of generator_function, which may be used in output rows. We may have multiple aliases if generator_function have multiple output columns.
CREATE TABLE person (id INT, name STRING, age INT, class INT, address STRING);
INSERT INTO person VALUES
(100, 'John', 30, 1, 'Street 1'),
(200, 'Mary', NULL, 1, 'Street 2'),
(300, 'Mike', 80, 3, 'Street 3'),
(400, 'Dan', 50, 4, 'Street 4');
SELECT * FROM person
LATERAL VIEW EXPLODE(ARRAY(30, 60)) tableName AS c_age
LATERAL VIEW EXPLODE(ARRAY(40, 80)) AS d_age;
+------+-------+-------+--------+-----------+--------+--------+
| id | name | age | class | address | c_age | d_age |
+------+-------+-------+--------+-----------+--------+--------+
| 100 | John | 30 | 1 | Street 1 | 30 | 40 |
| 100 | John | 30 | 1 | Street 1 | 30 | 80 |
| 100 | John | 30 | 1 | Street 1 | 60 | 40 |
| 100 | John | 30 | 1 | Street 1 | 60 | 80 |
| 200 | Mary | NULL | 1 | Street 2 | 30 | 40 |
| 200 | Mary | NULL | 1 | Street 2 | 30 | 80 |
| 200 | Mary | NULL | 1 | Street 2 | 60 | 40 |
| 200 | Mary | NULL | 1 | Street 2 | 60 | 80 |
| 300 | Mike | 80 | 3 | Street 3 | 30 | 40 |
| 300 | Mike | 80 | 3 | Street 3 | 30 | 80 |
| 300 | Mike | 80 | 3 | Street 3 | 60 | 40 |
| 300 | Mike | 80 | 3 | Street 3 | 60 | 80 |
| 400 | Dan | 50 | 4 | Street 4 | 30 | 40 |
| 400 | Dan | 50 | 4 | Street 4 | 30 | 80 |
| 400 | Dan | 50 | 4 | Street 4 | 60 | 40 |
| 400 | Dan | 50 | 4 | Street 4 | 60 | 80 |
+------+-------+-------+--------+-----------+--------+--------+
left join
spark-sql>
> select * from person left join person1 on person.id = person1.id;
100 John 30 1 Street 1 100 John 30 1 Street 1
200 Mary NULL 1 Street 2 200 Mary NULL 1 Street 2
300 Mike 80 3 Street 3 300 Mike 80 3 Street 3
400 Dan 50 4 Street 4 400 Dan 50 4 Street 4
Time taken: 0.845 seconds, Fetched 4 row(s)
Explain
The EXPLAIN statement is used to provide logical/physical plans for an input statement. By default, this clause provides information about a physical plan only.’
可参考: https://spark.apache.org/docs/latest/sql-ref-syntax-qry-explain.html
Syntax
EXPLAIN [ EXTENDED | CODEGEN | COST | FORMATTED ] statement
EXTENDED
Generates parsed logical plan, analyzed logical plan, optimized logical plan and physical plan. Parsed Logical plan is a unresolved plan that extracted from the query. Analyzed logical plans transforms which translates unresolvedAttribute and unresolvedRelation into fully typed objects. The optimized logical plan transforms through a set of optimization rules, resulting in the physical plan.
CODEGEN
Generates code for the statement, if any and a physical plan.
COST
If plan node statistics are available, generates a logical plan and the statistics.
FORMATTED
Generates two sections: a physical plan outline and node details.
statement
Specifies a SQL statement to be explained.
explain sql
> explain select 1;
== Physical Plan ==
*(1) Project [1 AS 1#5]
+- *(1) Scan OneRowRelation[]
Table-valued Functions (TVF)
A table-valued function (TVF) is a function that returns a relation or a set of rows. There are two types of TVFs in Spark SQL:
a TVF that can be specified in a FROM clause, e.g. range;
a TVF that can be specified in SELECT/LATERAL VIEW clauses, e.g. explode.
可参考: https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-tvf.html
-- range call with start and end
SELECT * FROM range(5, 10);
+---+
| id|
+---+
| 5|
| 6|
| 7|
| 8|
| 9|
+---+
Hive SQL
CREATE TABLE t2(a string, b string, c string) PARTITIONED BY (b,c);
INSERT INTO t2 VALUES('a3', '3', 'c3');
INSERT INTO t2 VALUES('a1', '1', 'c1');
insert OVERWRITE TABLE t2 SELECT * from t2;
desc formatted 表名: 查看该表的结构化数据,但并不列出表中的数据
> desc formatted t1;
a string
b string
c string
# Partition Information
# col_name data_type comment
b string
c string
# Detailed Table Information
Database default
Table t1
Owner xxx
Created Time Fri Oct 20 14:55:17 CST 2023
Last Access UNKNOWN
Created By Spark 3.3.2
Type MANAGED
Provider PARQUET
Location file:/xxx/spark-warehouse/t1
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Partition Provider Catalog
Time taken: 0.081 seconds, Fetched 22 row(s)
如果使用 stored as 建表
CREATE TABLE t3(a string, b string, c string) PARTITIONED BY (b,c) stored as parquet;
Provider 一项显示的是 hive
> desc formatted t3;
a string
b string
c string
# Partition Information
# col_name data_type comment
b string
c string
# Detailed Table Information
Database default
Table t3
Owner xxx
Created Time Tue Oct 24 18:40:57 CST 2023
Last Access UNKNOWN
Created By Spark 3.3.2
Type MANAGED
Provider hive
Table Properties [transient_lastDdlTime=1698144057]
Location file:/xxx/spark-warehouse/t3
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Storage Properties [serialization.format=1]
Partition Provider Catalog
Time taken: 0.058 seconds, Fetched 24 row(s)
和HiveSQL 的兼容性探讨
参考链接:
https://spark.apache.org/docs/3.3.2/sql-migration-guide.html#compatibility-with-apache-hive
https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
创建hive表的典型特征是
- “using hive”
- “stored as xxx”
- …
相关优化配置
spark.sql.hive.convertMetastoreParquet
val CONVERT_METASTORE_PARQUET = buildConf("spark.sql.hive.convertMetastoreParquet")
.doc("When set to true, the built-in Parquet reader and writer are used to process " +
"parquet tables created by using the HiveQL syntax, instead of Hive serde.")
.version("1.1.1")
.booleanConf
.createWithDefault(true)
private def isConvertible(storage: CatalogStorageFormat): Boolean = {
val serde = storage.serde.getOrElse("").toLowerCase(Locale.ROOT)
serde.contains("parquet") && conf.getConf(HiveUtils.CONVERT_METASTORE_PARQUET) ||
serde.contains("orc") && conf.getConf(HiveUtils.CONVERT_METASTORE_ORC)
}
isConvertible 代表hive 转换为 datasource,所以才会去检查 outputpath。
// INSERT HIVE DIR
case InsertIntoDir(_, storage, provider, query, overwrite)
if query.resolved && DDLUtils.isHiveTable(provider) &&
isConvertible(storage) && conf.getConf(HiveUtils.CONVERT_METASTORE_INSERT_DIR) =>
val outputPath = new Path(storage.locationUri.get)
if (overwrite) DDLUtils.verifyNotReadPath(query, outputPath)
InsertIntoDataSourceDirCommand(metastoreCatalog.convertStorageFormat(storage),
convertProvider(storage), query, overwrite)
spark.sql.sources.partitionOverwriteMode
val PARTITION_OVERWRITE_MODE =
buildConf("spark.sql.sources.partitionOverwriteMode")
.doc("When INSERT OVERWRITE a partitioned data source table, we currently support 2 modes: " +
"static and dynamic. In static mode, Spark deletes all the partitions that match the " +
"partition specification(e.g. PARTITION(a=1,b)) in the INSERT statement, before " +
"overwriting. In dynamic mode, Spark doesn't delete partitions ahead, and only overwrite " +
"those partitions that have data written into it at runtime. By default we use static " +
"mode to keep the same behavior of Spark prior to 2.3. Note that this config doesn't " +
"affect Hive serde tables, as they are always overwritten with dynamic mode. This can " +
"also be set as an output option for a data source using key partitionOverwriteMode " +
"(which takes precedence over this setting), e.g. " +
"dataframe.write.option(\"partitionOverwriteMode\", \"dynamic\").save(path)."
)
.version("2.3.0")
.stringConf
.transform(_.toUpperCase(Locale.ROOT))
.checkValues(PartitionOverwriteMode.values.map(_.toString))
.createWithDefault(PartitionOverwriteMode.STATIC.toString)
这边会跳过 verifyNotReadPath 检查,因为 staging directories 存在
// For dynamic partition overwrite, we do not delete partition directories ahead.
// We write to staging directories and move to final partition directories after writing
// job is done. So it is ok to have outputPath try to overwrite inputpath.
if (overwrite && !insertCommand.dynamicPartitionOverwrite) {
DDLUtils.verifyNotReadPath(actualQuery, outputPath)
}
insertCommand
insert overwrite 相关测试
datasource table VS hive table
判断代码在这里
def isDatasourceTable(table: CatalogTable): Boolean = {
table.provider.isDefined && table.provider.get.toLowerCase(Locale.ROOT) != HIVE_PROVIDER
}
datasource 表
CREATE TABLE t2(a string, b string, c string) PARTITIONED BY (b,c);
INSERT INTO t2 VALUES('a3', '3', 'c3');
INSERT INTO t2 VALUES('a1', '1', 'c1');
insert OVERWRITE TABLE t2 SELECT * from t2;
须设置
set spark.sql.sources.partitionOverwriteMode=dynamic;
可选项
set spark.sql.hive.convertMetastoreParquet=false;
hive 表
CREATE TABLE t3(a string, b string, c string) PARTITIONED BY (b,c) stored as parquet;
INSERT INTO t3 VALUES('a3', '3', 'c3');
INSERT INTO t3 VALUES('a1', '1', 'c1');
insert OVERWRITE TABLE t3 SELECT * from t3;
如果出现以下错误
spark-sql> INSERT INTO t3 VALUES('a3', '3', 'c3');
org.apache.spark.SparkException: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:162)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:106)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:113)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:111)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:125)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:98)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:95)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:98)
直接
set hive.exec.dynamic.partition.mode=nonstrict
hive table 的insert 操作,走这个类
case class InsertIntoHiveTable(
table: CatalogTable,
partition: Map[String, Option[String]],
query: LogicalPlan,
overwrite: Boolean,
ifPartitionNotExists: Boolean,
outputColumnNames: Seq[String]) extends SaveAsHiveFile {