【PyTorch】卷积神经网络
卷积神经网络
卷积神经网络最初是为了解决计算机视觉的相关问题设计的,现在其不仅被应用在图像和视频领域,也可用于诸如音频信号的时间序列信号的处理之中。
本文主要着重于卷积神经网络的基本原理和使用PyTorch实现卷积神经网络。
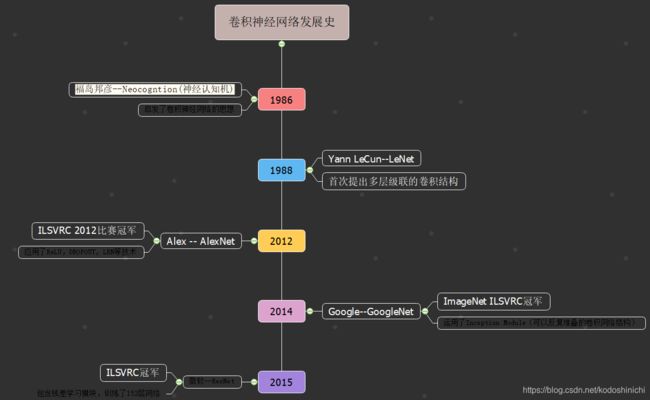
一. 发展脉络
二. 卷积神经网络
因为一开始卷积神经网络的提出也是为了解决图像问题,所以在阐述其理念时,我们也多会使用图像问题作为示例。
(一)综述
1. 全连接网络存在的问题
- 全连接神经网络:只包含全连接层(每两层的所有节点都是两两相连)的神经网络
①参数量巨大
比如对于一个200x200的输入图像而言,下一个隐层的神经元数目设定为104个,那么全连接层的结构下一共有200x200x104个权值参数。
p.s. 这里我们假定:针对图像的输入,采用像素级别的处理,即每一个输入层单元处理一个像素块。
②训练费时
因为参数数目巨大,所以进行反向传播的时候,训练效率低下。
③过拟合
也是因为参数数目的巨大,导致参数数目与标记数据比起来显得过于庞大,很容易导致模型训练的程度出现过拟合的问题。
2. 卷积神经网络的小trick
①局部连接
每一个卷积操作只负责处理一小块图像,并将得到的结果向后面的网格进行传递。
同样是针对一个200x200的输入图像,局部连接下,隐层中的每个单元只和图像中的4x4的局部图像进行连接,此时参数数目只有4x4x104 = 1.6x105,较全连接层减少了3个数量级。
②权值共享
- 按照前面我们局部连接中讨论的那样,如果隐层有n个神经元,每个神经元只和前一层的mxm的局部图像进行连接,那么我们会有n·m2个权值参数;在权值共享的思想下,我们让每个神经元都具有相同的mxm个参数,那么无论隐藏取的单元数目n为多少,在这一层我们只会有m2个权值参数。
【本质】
卷积层是用来承接卷积操作的结果,卷积操作的核心就是卷积核,卷积核的作用对应于原图像经过某种滤波得到新的图像。
新图像中的每一个像素,都是由这一个共同的卷积核作用得到的。而卷积层的每一个单元就是用来存放每一个新图像的像素,因此和每一个单元关联的权值参数都应该是一样的。
p.s. 关于卷积的相关知识具体可以参考博文《吴恩达深度学习cnn篇》
【卷积核与特征】
一个卷积层可以有多个不同的卷积核,每一种卷积层相当于提取出了原图像的一种特征出来;
在实际应用中,我们可能需要提取多个特征,因此可以通过增加卷积核的方式来实现
3. 卷积神经网络的一般结构
- 一般的卷积网络由卷积层、池化层、全连接层、Softmax层组成。
【卷积层】该层中每一一个节点的输入是上一层神经网络的一小块,它视图将神经网络中的每一小块进行更加深入的分析,从而得到抽象程度更高的特征。
【池化层】该层的网络不会改变三维矩阵的深度(比如RGB图像的长宽体现图像大小,而深度即为3通道),但是会缩小矩阵的大小。本质上该层将分辨率较高的图片转化为分辨率较低的图片。
【全连接层】经过多轮卷积和池化之后,卷积神经网络会连接1到2层的全连接层传递最后的结果。
【Softmax层】用于分类问题,即选用相应的激活函数和目标函数。
局部连接、权值共享以及池化层的下采样降低了参数量,使得训练复杂度降低,减轻了过拟合的风险;同时赋予了卷积神经网络对平移、形变、尺度的某种程度不变性,提高了模型的泛化能力。
(二)卷积层
1. 基本知识
卷积层神经网络结构中最重要的部分就是卷积核(kernel)或者也称为滤波器(filter),卷积核将当前层神经网络上的一个子节点矩阵转化成下一层神经网络上的一个节点矩阵。
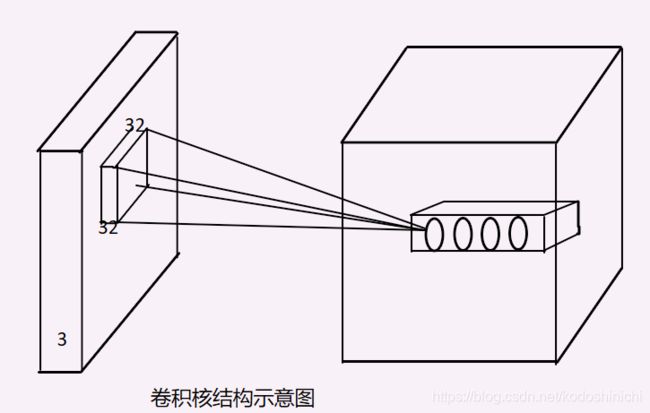
根据上图,我们在使用卷积神经网络及卷积运算和结构时,最重要的就是要了解卷积核的相关参数和神经元的相关设定。
- 卷积核的尺寸(卷积核的长宽),都是人工指定的,当前层神经网络的子节点矩阵的尺寸就是卷积核的尺寸。
- 卷积核的(处理)深度,与当前层的神经网络节点矩阵的深度是一致的。
要注意,卷积核的深度往往是默认相同的,即使传入的当前层矩阵是三维的,我们依然只需要人为指定长宽两个参数。
一般而言,我们会取卷积核的大小为3x3和5x5.
在上图中,左边所示就是输入图像对应的矩阵,其尺寸大小为3x32x32
因此如果我们取卷积核的大小为5x5,那么每一个卷积核的大小实际应该是3x5x5,卷积层每个神经元(上图中右边区域里的小椭圆)都会有输入数据中3x5x5区域的权重,一共75个权重。
p.s. 要注意在PyTorch中对数据大小的描述顺序。
- 卷积核的数量,也就是卷积层的输出深度,如上图右边区域所绘的一共有5个神经元,对应5个卷积核。卷积核的数目和所使用的滤波器的个数是相同的。
- 步长,滑动步长就是进行卷积运算时每次移动的像素点的个数。
滑动卷积的操作使得输出的数据一般会更少。
- 边界填充,根据需要有不同的填充模式;当全部填充为0时,保证输入出的数据具有相同的大小;填充值大于0的话,可以确保在卷积操作的过程中不损失边界信息。
【卷积计算公式】
进行卷积运算之后得到的输出大小,由以下公式计算可得
W ′ = f l o o r ( ( W − F + 2 P ) / S + 1 ) W' = floor((W-F+2P)/S+1) W′=floor((W−F+2P)/S+1)
其中floor表示取下整操作,W表示输入数据的大小,F表示卷积层中的卷积核的尺寸,S表示步长,P表示边界填充为0的数量。
2. PyTorch中的调用
在PyTorch中有专门封装好的卷积核模块nn.Conv2d()
其形参结构如下
nn.Conv2d(in_channels,out_channels,kernel_size,stride = 1,padding = 0,dilation = 1,groups = 1,bias = True)
in_channels:输入数据体的深度,由传入数据的大小决定out_channels:输出数据体的深度,通常由选用的核的个数决定kernel_size:卷积核的大小;当时方形卷积核的时候,只传入一个数;非方形卷积核的时候,传入一个元组stride:滑动的步长,默认为1padding:边界0的填充个数dilation:输入数据体的空间间隔groups:输入数据体和输出数据体在深度上的关联bias:表示偏置
'''
对PyTorch中的卷积核的调用示例
'''
#方形卷积核,等长的步长
m = nn.Conv2d(16,33,3,stride = 2)
#非方形卷积核,非登场的步长和边界填充
m = nn.Conv2d(16,33,(3,5),stride = (2,1),padding = (4,2))
#非方形卷积核,非登场的步长、边界填充和空间间隔
m = nn.Conv2d(16,33,(3,5),stride = (2,1),padding = (4,2),dilation = (3,1))
#进行卷积运算
input = autograd.Variable(torch.randn(20,16,50,100))
output = m(input)
(三)池化层
通常会在卷积层之后插入一个池化层,该层神经网络有以下作用:
- 逐渐降低网络的空间尺寸
- 减少网络中参数的数量
- 减少计算资源的使用
- 有效控制模型的过拟合
池化层一般有两种计算方式,Max Pooling和Mean Pooling;前者是采用【取最大值】的计算,后者是采用【取平均值】的计算,以下用Max Pooling作为示例来讨论。
1. 计算过程
池化层只对数据的长宽尺寸进行降采样,并不会改变模型的深度。
它将输入数据在深度上的切片作为输入,不断地滑动窗口,在Max Pooling的计算原则下,取这些窗口中的最大值为输出结果。

池化层的有效性?
- 图像特征具有局部不变性,也就是说经过下采样之后得到的缩小的图片依然不对丢失其具有的特征
基于此,将图片缩小之后再进行卷积运算(所谓卷积运算就是使用设计kernel对图片的特征进行提取),可以降低卷积运算的时间。
- 采用常用的池化方案(池化尺寸为2x2,滑动步长为2),对图像进行下采样实际上丢失了原图的75%的信息,选择其中最大的部分保留下来,也可以去除噪声。
2. PyTorch中的调用
因为有两种不同的池化方案,同样地,在PyTorch中也相应有
nn.MaxPool2d和nn.AvgPool2d
nn.MaxPool2d(kernel_size,stride = None,padding = 0,dilation = 1,
return_indices = False,ceil_mode = False)
- 有关参数可以参考卷积层中的解释
return_indices:是否返回最大值所处的下标ceil_model:使用方格代替层结构
同样地,如果选用的池化尺寸是方形的则只需要传入一个数,否则需要传入一个元组。
三. 经典卷积神经网络
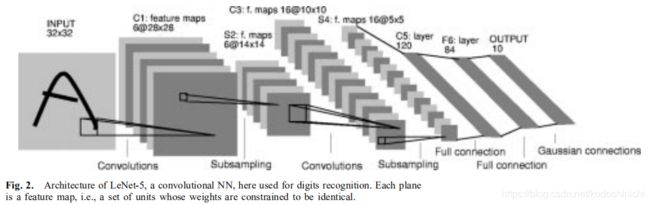
1. LeNet
LeNet具体所指的是LeNet-5,是Yann LeCun教授于1988年在论文《Gradient-based learning applied to document recognition》中提出,是第一个成功应用于数字识别问题的卷积神经网络。
LeNet-5模型一共有7层(2个卷积层、2个池化层、2个全连接层和一个输出层)
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out,2)
out = F.relu(self.con2(out))
out = F.max_pool2d(out,2)
out = out.view(out.size(0),-1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
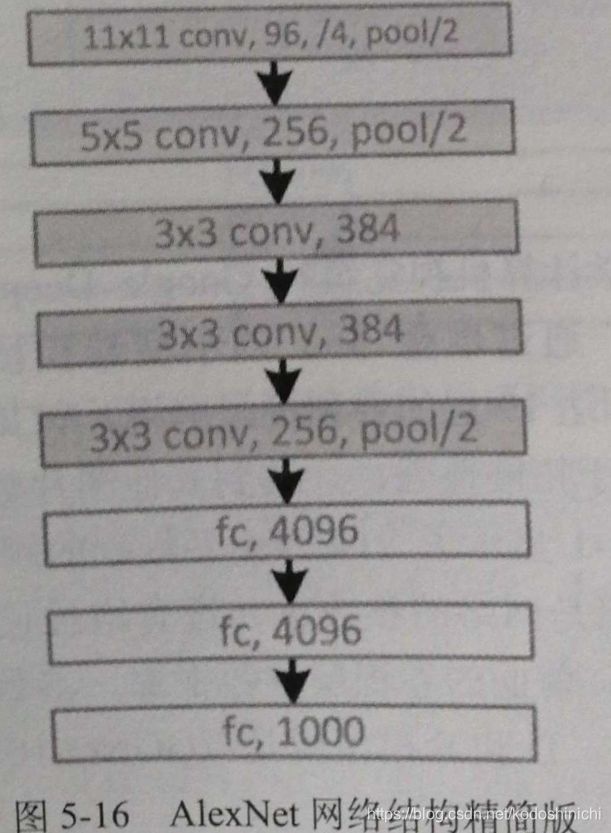
2. AlexNet
2012年由Hilton的学生Alex Krizhevsky提出;该结构成功应用了Relu、Dropout和LRN等技巧。
AlexNet的模型结构图如下所示,因为当时计算能力的制约,采取了两个GPU并行计算,因此结构图看起来略显复杂。
下面给出单个GPU计算时等价的模型结构图
整个AlexNet中包含5个卷积层、3个池化层和3个全连接层。
其中卷积层和全连接层中都包含有ReLU层,在全连接层中还有对Dropout层的应用。
class AlexNet(nn.Module):
def __init__(self,num_classes):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,96,kernel_size = 11,stride = 4,padding = 2),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
nn.Conv2d(64,256,kernel_size = 5,padding = 2),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
nn.Conv2d(192,384,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.Conv2d(384,256,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.Conv2d(256,256,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256*6*6,4096),
nn.ReLU(inplace = True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(inplace = True),
nn.Linear(4096,num_classes)
)
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),256*6*6)
x = self.classifier(x)
return x