使用ControlNet生成视频(Pose2Pose)
目录
ControlNet 介绍
ControlNet 14种模型分别是用来做什么的
ControlNet 运行环境搭建
用到的相关模型地址
ControlNet 介绍
ControlNet 是一种用于控制扩散模型的神经网络结构,可以通过添加额外的条件来实现对图像生成的控制¹²。它通过将神经网络块的权重复制到一个“锁定”的副本和一个“可训练”的副本来实现这一点。 “可训练”的副本学习你的条件,而“锁定”的副本保留你的模型。这样,使用小规模的图像对数据集进行训练不会破坏生产就绪的扩散模型。
ControlNet 的创新之处在于它解决了空间一致性的问题。以前,没有有效的方法可以告诉 AI 模型保留输入图像的哪些部分,而 ControlNet 通过引入一种方法来实现这一点,使得稳定扩散模型能够使用额外的输入条件来指导模型的行为。
ControlNet 可以通过重复上述简单的结构 14 次来控制稳定扩散。这样,ControlNet 就可以重用 SD 编码器作为一个深层、强大、稳健和强大的骨干网络,来学习多样化的控制¹。
ControlNet 可以使用各种技术来对输入图像和提示进行条件化,例如姿态、边缘检测、深度图等。它可以让我们通过不同的方式来控制最终的图像生成,例如涂鸦、交互式分割、内容混合等。
ControlNet 14种模型分别是用来做什么的
- Canny: 用于生成边缘检测图像,可以用于AI绘画或者风格迁移。
- Depth: 用于生成深度图像,可以用于3D重建或者虚拟现实。
- Openpose: 用于生成人体姿态估计图像,可以用于动作识别或者动画制作。
- Style: 用于生成不同风格的图像,可以用于艺术创作或者滤镜效果。
- MLSD: 用于生成直线检测图像,可以用于几何变换或者透视校正。
- Normal: 用于生成法线图像,可以用于光照模拟或者材质编辑。
- Seg: 用于生成分割图像,可以用于物体识别或者背景替换。
- Inpaint: 用于生成修复图像,可以用于去除水印或者填补空缺。
- Lineart: 用于生成线稿图像,可以用于漫画制作或者素描练习。
- Lineart_anime: 用于生成动漫风格的线稿图像,可以用于二次元创作或者上色。
- Scribble: 用于生成涂鸦图像,可以用于草图设计或者儿童游戏。
- Softedge: 用于生成软边缘图像,可以用于模糊效果或者边缘检测。
- Shuffle: 用于生成随机排列的图像,可以用于拼图游戏或者视觉混乱。
- IP2P: 用于生成图片到图片的转换,可以用于风格迁移或者内容变换。
ControlNet 运行环境搭建
- 克隆项目
git clone --recursive https:\\github.com\lllyasviel/ControlNet-v1-1-nightly- 创建虚拟环境
cd ControlNet-v1-1-nightly
conda env create -f=environment.yml- 试运行depth模型
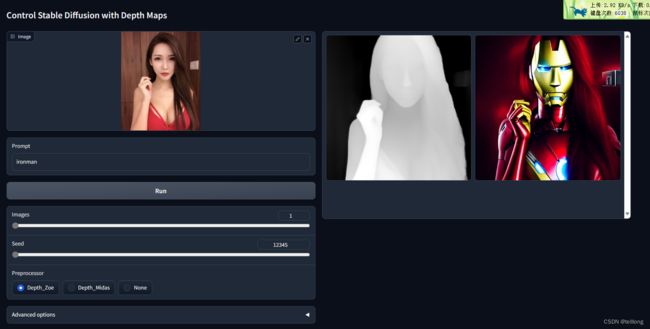
首先去huggingface下载,control_v11flp_sd15_depth.pth模型和v1-5-pruned.ckpt两个模型放置在models目录下,运行代码
python gradio_depth.py浏览器打开http://127.0.0.1:7860/
- 使用视频生成连续的帧并合成视频文件
生成得太慢了,这里只生成100帧,模型用的原生stablediffusion的模型,对人物的绘制不太好,用经过lora训练的模型生成的视频更好
from share import *
import config
import cv2
import einops
import gradio as gr
import sys
import numpy as np
import torch
import random
from pytorch_lightning import seed_everything
from annotator.util import resize_image, HWC3
from annotator.openpose import OpenposeDetector
from cldm.model import create_model, load_state_dict
from cldm.ddim_hacked import DDIMSampler
preprocessor = None
model_name = 'control_v11p_sd15_openpose'
model = create_model(f'./models/{model_name}.yaml').cpu()
model.load_state_dict(load_state_dict('./models/v1-5-pruned.ckpt', location='cuda'), strict=False)
model.load_state_dict(load_state_dict(f'./models/{model_name}.pth', location='cuda'), strict=False)
model = model.cuda()
ddim_sampler = DDIMSampler(model)
# def process(det, input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta):
def process(input_image, prompt, det="Openpose_Full", seed=1, num_samples=1, detect_resolution=512, image_resolution=512, guess_mode=False, a_prompt="best quality", n_prompt="lowres, bad anatomy, bad hands, cropped, worst quality", strength=1.0, ddim_steps=20, eta=1.0, scale=9.0):
global preprocessor
if 'Openpose' in det:
if not isinstance(preprocessor, OpenposeDetector):
preprocessor = OpenposeDetector()
with torch.no_grad():
input_image = HWC3(input_image)
if det == 'None':
detected_map = input_image.copy()
else:
detected_map = preprocessor(resize_image(input_image, detect_resolution), hand_and_face='Full' in det)
detected_map = HWC3(detected_map)
img = resize_image(input_image, image_resolution)
H, W, C = img.shape
detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_LINEAR)
control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0
control = torch.stack([control for _ in range(num_samples)], dim=0)
control = einops.rearrange(control, 'b h w c -> b c h w').clone()
if seed == -1:
seed = random.randint(0, 65535)
seed_everything(seed)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}
un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]}
shape = (4, H // 8, W // 8)
if config.save_memory:
model.low_vram_shift(is_diffusing=True)
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13)
# Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples,
shape, cond, verbose=False, eta=eta,
unconditional_guidance_scale=scale,
unconditional_conditioning=un_cond)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
x_samples = model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)
results = [x_samples[i] for i in range(num_samples)]
return [detected_map] + results
if __name__=='__main__':
video_capture = cv2.VideoCapture(sys.argv[1])
fps = int(video_capture.get(cv2.CAP_PROP_FPS))
frame_size = (
int(video_capture.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(video_capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
)
count = video_capture.get(cv2.CAP_PROP_FRAME_COUNT)
output_video = None
init = False
while True:
ret, frame = video_capture.read()
if not ret:
break
oimage = process(input_image=np.uint8(frame), prompt="photorealistic,long_hair,realistic,solo,long_hair,(photorealistic:1.4),best quality,ultra high res,teeth,Long sleeve,"
"Blue dress,full body,big breasts, 3girls,Grin,graffiti (medium),ok sign,sexy,"
"smile,stand,1girl,full body,beautiful,masterpiece,best quality,extremely detailed face,perfect lighting,1girl,solo"
"best quality,ultra high res,(photorealistic:1.4),parted lipslipstick,ultra detailed,Peach buttock,looking at viewer,masterpiece,best quality")
print(oimage[1].shape)
if init is False:
output_video = cv2.VideoWriter("output_video.mp4", cv2.VideoWriter_fourcc(*'mp4v'), fps, (oimage[1].shape[1], oimage[1].shape[0]))
init = True
output_video.write(oimage[1])
print("==> frame:%d count:%d" % (video_capture.get(cv2.CAP_PROP_POS_FRAMES), count))
if video_capture.get(cv2.CAP_PROP_POS_FRAMES) == 100:
break;
video_capture.release()
output_video.release()
cv2.destroyAllWindows()- 运行
python ovc_openpose.py exp.mp4用到的相关模型地址
Annotators
StableDiffusion
ControlNet