自监督学习之对比学习:MoCo模型超级详解解读+总结
文章目录
- 一、MoCo简介
-
- 1.1 整体思想
- 1.2 动量
- 1.3 正负样本如何选取
- 二、动态字典
-
- 2.1 query和key
- 2.2 字典特点
- 三、编码器的动量更新
-
- 3.1 编码器的更新规则
- 3.2 使用动量更新的原因
- 四、实验过程
-
- 4.1 目标函数:infoNCE
-
- 4.1.1 softmax
- 4.1.2 交叉熵损失
- 4.1.3 交叉熵损失函数和softmax的关系
- 4.1.4 为什么使用NCE loss
- 4.2 前向传播过程
-
- 4.2.1 模型图
- 4.2.2 伪代码
学习资料:
MOCO论文精读-哔哩哔哩
一、MoCo简介
动量对比学习方法做无监督表征学习。
使用动量的方式更新编码器,使用队列的方法存储memory bank这个字典,从而获得一个又大又一致的字典。
1.1 整体思想
把memory bank这个字典当做一个队列进行维护
1.2 动量
加权移动平均。让当前输出不完全依赖于当前输入,而是也取决于前一时刻的输出。
y t = m ∗ y t − 1 + ( 1 − m ) ∗ x t y_t = m*y_{t-1}+(1-m)*x_t yt=m∗yt−1+(1−m)∗xt
- y t − 1 y_{t-1} yt−1 :上一时刻的输出
- y t y_t yt:这一时刻想要改变的输出
- x t x_t xt:当前时刻的输入
- m m m:动量,超参数,介于0-1之间
当 m m m趋近于1的时候, y t y_t yt改变的非常缓慢,因为它基本就相当于前一刻的输出, x t x_t xt基本不起作用。
当 m m m趋近于0的时候, y t y_t yt改变的非常迅速,因为前一刻的输出基本不起作用,基本取决于当前输入 x t x_t xt。
moco利用动量的特性,缓慢更新编码器。让字典中的特征尽可能保持一致。
1.3 正负样本如何选取
原图x1经过数据增广后产生的两张图片互为正样本对,数据集中除了x1以外的其他图片都可以为负样本。
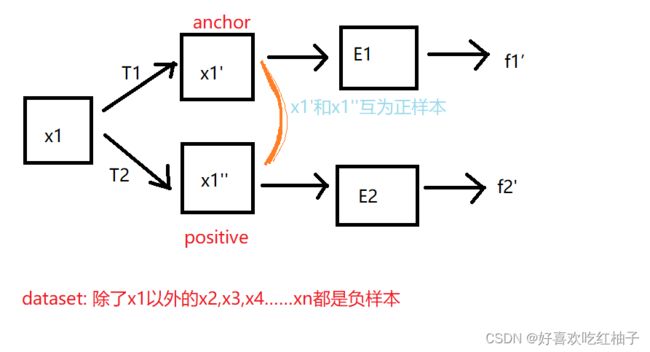
二、动态字典
2.1 query和key
把对比学习当成动态字典。
These methods can be thought of as building dynamic dictionaries. The “keys” (tokens) in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network. Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others. Learning is formulated as minimizing a contrastive loss.

在论文中,作者使用:
- x q x_q xq表示x1’
- x k x_k xk表示x1’’
- q q q来表示锚点图片产生的特征f1’,
- k 0 , k 1 , k 2 … … k_0,k_1,k_2…… k0,k1,k2……表示剩余图片提取到的特征f11,f2,f3……

2.2 字典特点
- 动态:字典中的key都是随机取样的,用来给key做编码的编码器也是在训练中不断改变的。
- 足够大:包含足够多的负样本,从而让对比学习的效果更好。
- 保持一致性:尽量保持训练神经网络的过程中编码器的变化不要过大,防止由于编码器训练过程中变化过大导致提取到的特征不一致。
三、编码器的动量更新
3.1 编码器的更新规则
- q编码器:梯度更新
- k编码器:动量更新,不使用梯度更新

3.2 使用动量更新的原因
使用队列可以使字典变大,但它也使得通过反向传播(梯度应该传播到队列中的所有样本)更新编码器变得难以处理。
一个解决方案是直接把 f q f_q fq的参数直接复制给 f k f_k fk,而不进行梯度更新,但是这样效果很差,因为这样就会失去 f k f_k fk编码器对特征提取的一致性,由于编码器的参数一直在改变,所以一开始提取的特征就会和后面提取的特征很不一致,所以对 f k f_k fk编码器采用动量更新。

动量更新通过逐步调整编码器参数,使 f k f_k fk编码器逐渐学习到 f q f_q fq编码器的知识。这种更新策略有助于提高特征表示的一致性和稳定性,使得编码器能够更好地捕捉数据的结构和语义信息。
四、实验过程
一个正样本对:anchor和positive,anchor为q(anchor经过编码器后生成的特征向量),在字典中与q唯一配对的key成为 k + k_+ k+(positive经过编码器后生成的特征向量)
对于目标函数来说,当 q q q与它的 k + k_+ k+相似而与所有其他key(q的负样本)不相似时,它的值应该很低。
4.1 目标函数:infoNCE
4.1.1 softmax

4.1.2 交叉熵损失
一文详解Softmax函数-知乎

4.1.3 交叉熵损失函数和softmax的关系
损失函数简化后即可得到:

4.1.4 为什么使用NCE loss
对于损失函数来说,如果使用交叉熵作为损失函数,那么公式中的k值就会非常大,因为k代表的是类别个数,在个体判别领域,一张图片代表一个类,那么k值就等于数据集的大小,这样计算量过大。
为解决交叉熵损失函数中对类别求概率时k值过大的问题,提出了NCE loss(noise contractive )
NCE loss(noise contractive estimation) 可以把问题转换为只有以下两个类别的二分类问题:
- data sample:数据类别,即为正样本
- noise sample:噪声类别,从dataset中抽取出来的部分负样本

在公式中:
- τ:温度系数,控制分布形状,超参数
- q ∗ k + q*k_+ q∗k+:softmax的logits,点积相乘相当于 q 和 k + q和k_+ q和k+的相似值度量
- q ∗ k i q*k_i q∗ki:softmax的logits,点积相乘相当于 q 和 k i q和k_i q和ki的相似值度量
其实NCE loss就类似于一个交叉熵损失函数,做了一个k+1类的分类任务,目的就是把q分类为 k + k_+ k+类。
4.2 前向传播过程
MOCO详解-知乎
更新的有两个:encoder和队列
encode_p是根据梯度回传进行更新的,encode_k是通过动量进行缓慢 更新的。
4.2.1 模型图

4.2.2 伪代码
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward() update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch