【自监督论文阅读 4】BYOL
文章目录
- 一、摘要
- 二、引言
- 三、相关工作
- 四、方法
-
- 4.1 BYOL的描述
- 4.2 Intuitions on BYOL’s behavior(BYOL行为的直觉)
- 4.3 实验细节
- 五、实验评估
-
- 5.1 Linear evaluation on ImageNet(ImageNet上的线性评估)
- 5.2 Semi-supervised training on ImageNet(ImageNet上的半监督训练)
- 5.3 Transfer to other classification tasks(迁移到其他分类任务)
- 5.4 Transfer to other vision tasks(迁移到其他视觉任务)
- 六、消融实验(用消融来建立直觉)
-
- 6.1 相比SimCLR, BYOL对batch size的依赖更低
- 6.2 数据增强
- 6.3 Bootstrapping
- 七、结论
- 八、附录中图标的解释
- 参考
自监督论文阅读系列:
【自监督论文阅读 1】SimCLR
【自监督论文阅读 2】MAE
【自监督论文阅读 3】DINOv1
【自监督论文阅读 4】BYOL
论文地址:https://arxiv.org/pdf/2006.07733.pdf
github代码地址:https://github.com/deepmind/deepmind-research/tree/master/byol
论文题目:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
一、摘要
介绍了一种新的自监督图像表示学习方法BYOL(Bootstrap Your Own Latent )。
- BYOL依赖于两个神经网络,分别是在线网络和目标网络,它们相互作用并相互学习。
- 从图像的增强视图出发,我们训练在线网络来预测同一图像在不同增强视图下的目标网络的表示。
- 同时,使用在线网络的缓慢移动平均值来更新目标网络。
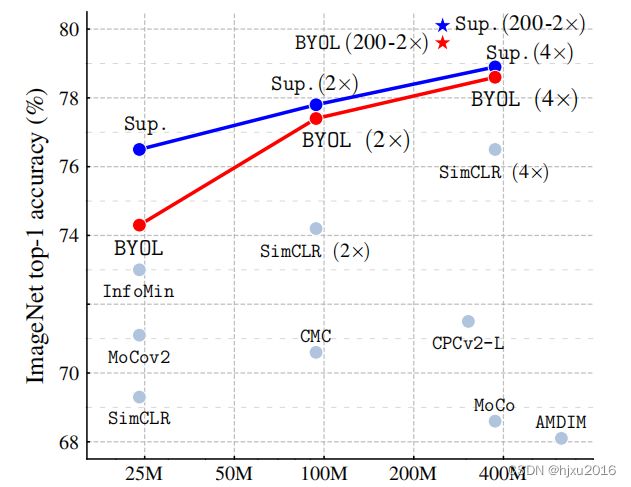
BYOL在没有负样本对的情况下达到了SOTA水平。在ImageNet数据集上,BYOL采用ResNet-50的Top-1线性分类精度为74.3%,采用更大的ResNet的精度可以达到79.6%。BYOL在迁移学习和半监督学习上的表现与当前的SOTA水平相当,甚至更好。
二、引言
学习良好的图像表示是计算机视觉的一个关键挑战,因为它允许对下游任务进行有效的训练。
已经提出了很多不同的训练方法来学习这种表示,这些方法通常依赖于视觉前置任务 pretext task。
- 最先进的对比方法通过减小同一图像的不同增强视图的表示之间的距离(正样本对)和增加来自不同图像的增强视图的表示之间的距离(负样本对)来训练。
这些方法需要很仔细的方法来处理negative pair, 比如通过依赖大batchsize、记忆库、或定制挖掘策略来检索negative pair, 此外,它们的性能主要取决于图像增强的选择。
在这篇文章中,我们介绍了BYOL,一种新的自监督图像表示学习的方法。
- 在不使用负样本对的情况下,BYOL获得了比最先进的对比方法更高的性能;
- 它迭代引导网络的输出,以作为强大的表征目标;
- 此外,与对比方法相比,BYOL对图像增强的选择更加鲁棒(本文猜测,不依赖负对是其鲁棒性提高的主要原因之一)
-本文直接引导表征信息的输出( 之前基于引导的方法,用了伪标签、聚类索引、一些少量的标签等) - BYOL使用两个神经网络,称为在线和目标网络,相互作用和相互学习。
从图像的增强视图开始,BYOL训练在线网络来预测目标网络,即预测同一图像的另一个增强视图的表示,实验表明,并没有出现模型坍塌的情况。
- 本文猜测,是因为在线网络添加了一个预测头和使用slow-moving average的方法讲online的参数更新到target网络中,鼓励了在线的prejection编码了更多的信息,从而避免模型坍塌。
这篇文章使用ResNet架构评估了BYOL在ImageNet和其他视觉基准上所学的表现。在ImageNet上的线性评估协议下,包括在冻结层来训练线性分类器,BYOL在标准ResNet-50上达到74.3%的top-1精度,在更大的ResNet上达到79.6%的top-1精度(图1)。在ImageNet上的半监督和 迁移学习中,也获得了与当前技术水平相当或更好的结果。
本文主要贡献如下:
- 引入了BYOL, 一种新的自监督图像表示学习的方法。在不使用负样本对的情况下,BYOL获得了比最先进的对比方法更高的性能
- 展示了,在弱监督和迁移学习的benchmarks, 我们学习的表征优于先进的方法;
- 相比于对比学习,BYOL在batchsize和数据增强的选择上,更有弹性;
- 在仅使用随机裁剪的数据增强时,BUOL性能下降明显比SimCLR低
三、相关工作
大多数无监督方法可以分成生成式和判别式。
- 生成式:在数据和潜在编码上建立分布,并将学习到的编码用作图像表示。
大多数方法依靠图像自编码、对抗学习、联合建模数据和表征。生成式方法通常直接操作在像素空间,但计算量大,且图像生成所需要的高水平细节可能不是表示学习所必须的。
- 判别式:比学习最近取得了最佳的性能。
对比学习通过将同一图像不同视角的表征拉近,不同图像的视图表征远离,来避免在像素空间中昂贵的生成步骤。
但是对比学习通常需要将每个样本与许多其他样本进行比较才能更好的工作,这就带来一个问题、使用负样本对是否是必要的。
- DeepCluster:使用以前版本表征的引导来为下一个表征生成目标;
DeepCluster是一个繁琐的解决方案,崽使用先验表征对数据点进行聚类,并使用每个样本的聚类索引作为新表示的分类目标。这个避免使用了负样本对,但是需要昂贵的聚类阶段和特定的预防措施来避免崩溃。
- 其他的自监督方法:没有采用对比的方式,而是依赖于使用辅助的人工设定预测任务来学习它们的表示。
比如相关patch预测、彩色灰度拓展图像、图像inpainting、图像拼接、图像超分辨率、集合变换, 这些已被证明是有用的。然而,即使有合适的构,这些方法也被对比方法所超越。
- PBL,Predictions of Bootstrapped Latents:强化学习(reinforcement learning (RL))里的自监督表征学习技术,本文方法与PBL相似。
PBL共同训练代理的历史表征和未来观察的编码。观察编码作为目标训练代理表征;代理表征作为目标训练观察编码。与PBL不同,BYOL使用表征的slow-moving average来提供目标,且不需要第二个网络。
- reinforcement learning (RL) 强化学习: 使用slow-moving average目标网络为在线网络产生稳定目标,到了深度RL(深度强化学习)的启发。
大多数RL的方法,使用固定的目标网络;而BYOL使用以前网络的加权平均移动,以便在目标表征中提供更平滑的变化
- 半监督设置: 半监督设置中,无监督的损失和少量标签的分类损失相结合来进行训练。
这些方法中,***mean teacher (MT)***使用slow-moving average network,为一个被称之为学生的在线网络产生目标。
通常在分类损失中teacher和student的L2一致性,但是当移除分类损失时,类似的方法会出现模型坍塌。而BYOL在oneline上增加了一个额外的预测器来避免坍塌。
- MoCo : 使用移动平均网络(动量编码器)来保持一致的表征(从记忆库中提取的负对)。
BYOL与MoCo不一样,BYOL直接使用移动平均网络来产生目标,作为稳定引导步骤的一种手段。这种纯粹稳定效应也可以改进现有的对比方法。
四、方法
先提了下研究动机:
- 在保持高性能的同时,负样本对防止模型坍塌是否是不可或缺的
许多成功的自监督学习方法建立在交叉视图预测框架的基础上。通常,这些方法通过彼此预测同一图像的不同视图(例如,不同的随机裁剪)来学习表征。
许多这样的方法将预测问题直接投射到表示空间中,图像的增强视图的表示应该是同一图像的另一增强视图的表示的预测。
然而,直接在表示空间中进行预测会导致表征的坍塌: 例如,一个表示在视图之间是恒定的,它总是对自己有完全的预测。
对比方法通过将预测问题重新表述为一个辨别问题来回避这个问题:从一个增强视图的表示中,他们学会辨别同一图像的另一个增强视图的表征和不同图像的增强视图的表征。
在绝大多数情况下,这阻止了训练找到崩塌的表征。然而,这种辨别方法通常需要将增强视图的每个表示与许多负面示例进行比较,以找到足够接近的示例,从而使辨别任务具有挑战性。
- 通过预测目标表征来训练一个新的,潜在的增强的在线表征
为了防止崩溃,一个简单的解决方案是使用一个固定的随机初始化的网络来产生我们预测的目标。虽然避免了崩溃,但从经验上看,它不会产生很好的表现。
尽管如此,有趣的是,使用该过程获得的表示已经比初始固定表示好得多。
4.1 BYOL的描述
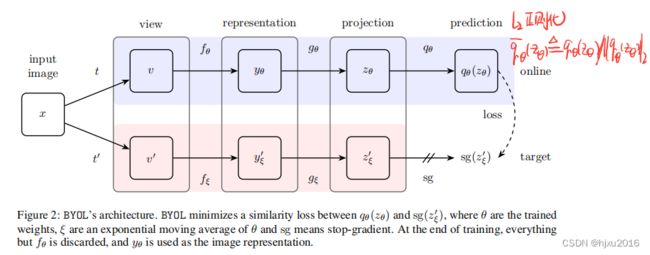
BYOL的目的是学习一个可以被用到下游任务的表征 y θ y_θ yθ,描述如下:
- BYOL由两个网络组成: o n l i n e online online 和 t a r g e t target target 网络.
- o n l i n e online online网络 :有三个阶段,编码器 f θ f_θ fθ、投影头 g θ g_θ gθ 和预测头 q θ q_θ qθ, 其中 θ θ θ指 o n l i n e online online网络的权重;
- t a r g e t target target网络:与 o n l i n e online online网络有着相似的结构,但使用不同的权重 ξ ξ ξ
- 训练方式: t a r g e t target target 网络提供回归目标给 o n l i n e online online网络进行训练, t a r g e t target target 的参数 ξ ξ ξ 是通过指数移动平均(EMA, exponential moving average)从 o n l i n e online online网络的权重 θ θ θ获取,公式如下:
ξ ← τ ξ + ( 1 − τ ) θ , τ ∈ [ 0 , 1 ] , ξ ← τ ξ + (1 − τ )θ, τ ∈ [0, 1], ξ←τξ+(1−τ)θ,τ∈[0,1], , τ τ τ 为target的衰减比例 - 给定一个图像集合 D D D, 从 D D D中均匀采样图片 x , x ∼ D x, x ∼ D x,x∼D, 两种数据增强的分布 T 和 T ′ T 和T' T和T′
- 图像 x x x 经过两种数据增强后,分别得到同一个图的两个视角 v v v和 v ′ v' v′
- 第一个视角 v v v 经过在线网络输出表征信息 y θ = f θ ( v ) y_θ =f_θ(v) yθ=fθ(v) ,在经过投影头 z θ = g θ ( y ) z_θ =g_θ(y) zθ=gθ(y)
- 第二个视角 v ′ v' v′ 输入目标网络中,得到 y ξ ′ = f ξ ( v ′ ) y'_ξ =f_ξ(v') yξ′=fξ(v′) 和目标投影头 z ξ ′ = g ξ ( y ′ ) z'_ξ =g_ξ(y') zξ′=gξ(y′)
- 整个架构最终输出预测头 q θ ( z θ ) q_θ(z_θ) qθ(zθ) 和 z ξ ′ z'_ξ zξ′
- 最后对两个输入进行l2归一化。

- 注意,预测头仅用在online的分支上,online 和 target在结构上是不对称的
- 最后,损失函数为 均方误差(MSE)

为了对称 L θ , ξ L_{θ,ξ} Lθ,ξ, 又将 v v v和 v ′ v' v′ 再分别送入到 target 和online中,得到 L ~ θ , ξ \widetilde{L}_{θ,ξ} L θ,ξ
使用随机梯度下降法最小化最终的损失
![]()
- 更新参数的时候,仅更新在线网络中的参数 θ θ θ, target网络中的 参数 ξ ξ ξ则停止更新,如下公式, η η η指学习率。
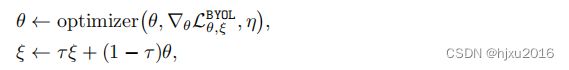
BYOL的结构如下:
以神经网络为架构的草图如下:

算法伪代码如下:

4.2 Intuitions on BYOL’s behavior(BYOL行为的直觉)
BYOL没有使用显示的对策来防止模型坍塌,仅通过最小化损失来更新参数(没有使用负样本,也没有对比损失)
总结两点如下:
-
目标网络的参数不是直接通过损失函数来更新的,在训练中只训练online network,target network实际上是一种过去的online network。这也就导致了无论怎么训练这个模型都不能使loss达到最小值。有些类似于GAN,有两个network进行对抗,始终无法将loss降下来。
-
BYOL增加了一个预测头,BYOL在online network后又增加了几层神经网络将online network中的projection预测到target network的latent space中, 为了能够完美的达成以上目标,整体的网络结构必须能够很好的克服图像增强对图像的影响,能够准确的将增广后的图像聚集(靠拢)在一起。这样实际上强迫了encoder学习出一个好的、更高级语义的表达。
4.3 实验细节
- 数据增强: BYOL使用与SimCLR中相同的图像增强集。
首先,通过随机水平翻转选择图像的随机块并将其大小调整到224 × 224,随后是颜色失真,由亮度、对比度、饱和度、色调调整和可选灰度转换的随机序列组成。最后,高斯模糊和solarization被用于随机块。
- 架构: 具有50层和后激活(ResNet-50(1×) v1)的卷积残差网络作为我们的基本参数编码器。我们还使用更深(50、101、152和200层)和更宽(从1倍到4倍)的ResNets。
表征 y y y对应着最后一层平均池化层的输出,维度为2014。和SimSLR一样,表征 y y y被多层感知器(MLP) g θ g_θ gθ投影到更小的空间,并且对于目标投影 g ξ g_ξ gξ也是相同。该MLP包括输出尺寸为4096的线性层,随后是批量归一化]、校正线性单元(ReLU) ,以及输出尺寸为256的最终线性层。与SimCLR相反,这个MLP的输出不是批量标准化的。预测器 q θ qθ qθ采用与 g θ gθ gθ相同的架构。
- 优化器:使用LARS优化器 和余弦衰减学习速率表 ,没有重新启动,超过1000个epoch,预热周期为10个epoch。
基本学习率设置为0.2,随批次大小线性缩放(学习率= 0.2 ×批次大小/256)。此外,我们使用 1.5 ⋅ 1 0 − 6 1.5 · 10^{−6} 1.5⋅10−6的全局权重衰减参数,同时从LARS自适应和权重衰减中排除偏差和批次标准化参数。对于目标网络,指数移动平均参数 τ τ τ从 τ b a s e = 0.996 τ_{base}= 0.996 τbase=0.996开始,在训练期间增加到1。具体来说,我们设置 τ = 1 − ( 1 − τ b a s e ) ⋅ ( c o s ( π k / K ) + 1 ) / 2 τ =1 − (1 − τ_{base}) · (cos(πk/K) + 1)/2 τ=1−(1−τbase)⋅(cos(πk/K)+1)/2,k为当前训练步骤,K为最大训练步骤数。我们使用的批量大小为4096,分布在512个云TPU v3内核上。使用这种设置,ResNet-50(×1)的训练大约需要8个小时。
五、实验评估
用ImageNet的数据进行自监督预训练,然后在各种下游任务中进行评估。
- 首先在 ImageNet (IN)上使用线性评估和半监督设置中对其进行评估。
- 在其他数据集和任务上测量其迁移学习 能力,包括分类、分割、对象检测和深度估计。
- 为了进行比较,还报告了使用来自训练 ImageNet子集 (称为监督输入)的标签训练的表示的效果。
- 为了评估BYOL的通用性,在复制该评估协议前,还在Place-365标准数据集上进行预训练特征。
5.1 Linear evaluation on ImageNet(ImageNet上的线性评估)
冻结表征层,然后训练一个线性分类器

5.2 Semi-supervised training on ImageNet(ImageNet上的半监督训练)
在ImageNet的一个小子集分类任务上,微调震哥哥网络。这里没有冻结表征层

下图展示了不同训练数据比例的性能,可以看到,有监督在训练数据很少的情况下,性能是非常差的。
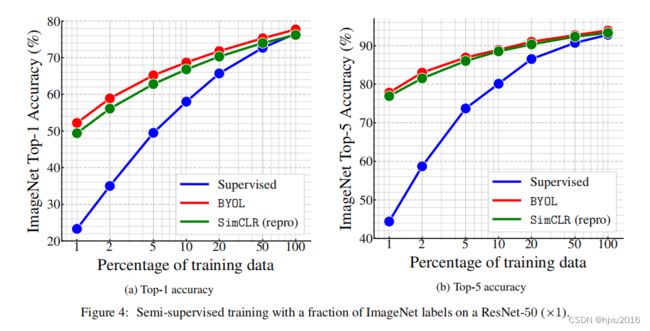
下图是在多个Resnet上,不同比例的数据Fintuning的结果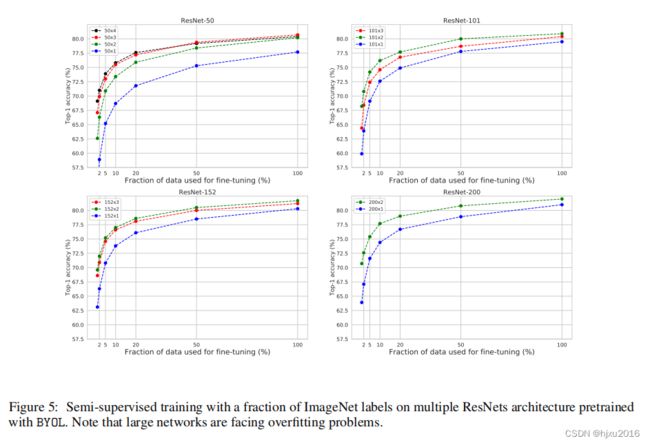
5.3 Transfer to other classification tasks(迁移到其他分类任务)
评估在ImageNet上学到的表征是否通用,因此在其他分类数据集上进行了评估。同样两种实验,冻结表征层和全部层进行微调。
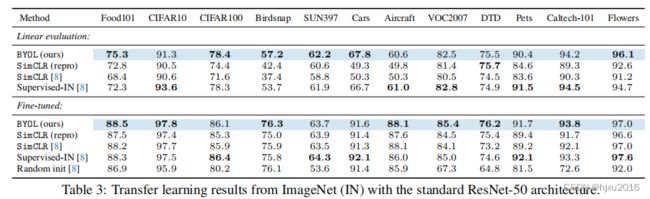
5.4 Transfer to other vision tasks(迁移到其他视觉任务)
在语义分割、目标检测、深度估计都评估了BYOL学习到的表征能否推广到分类任务之外

六、消融实验(用消融来建立直觉)
6.1 相比SimCLR, BYOL对batch size的依赖更低
猜测SimCLR batchsize小时,负样本对就比较少,所以对batchsize很敏感。
BYOL在batch从256-4096时,相对比较稳定。此外还提到,由于编码器中的批归一化层,只有在较小的值上下降
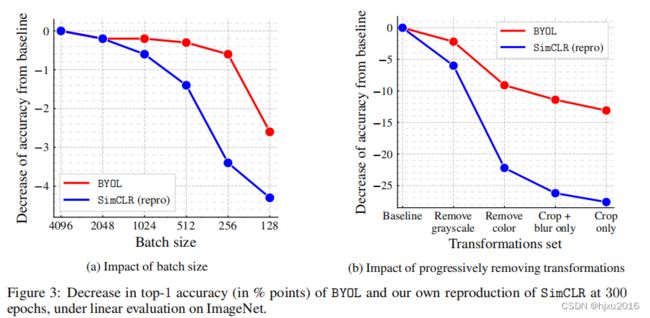
6.2 数据增强
也依赖数据增强,但相比SimCLR, 对数据增强没那么敏感。


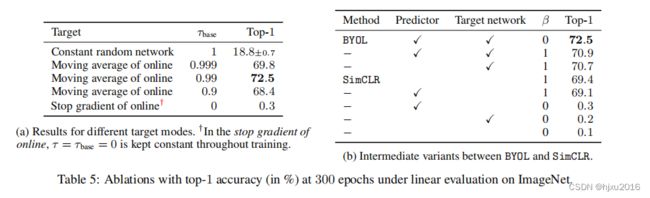
6.3 Bootstrapping
评估了动量更新的参数、网络结构等
- 预测头结合目标网络效果最好
- EMA参数更新效果最好,衰减指数为0.99效果最好
- 随机常量固定目标网络,还达到18.8的精度,和online一起更新只有0.3的精度。
七、结论
- 介绍了BYOL,一种新的自监督表征学习方法
- 通过预测以前版本的数据来学习标准,可以不使用负样本对
- 在带有ResNet-50 (1×)的ImageNet上的线性评估协议下,BYOL实现了新的技术水平,并弥合了自我监督方法和监督学习baseline之间的大部分剩余差距, 使用ResNet-200上,精度达到79.6%的top-1精度,同时参数减少了30%
- BYOL仍然依赖于特定视觉任务的数据增强,为了将BYOL推广到其他模态(例如,音频、视频、文本、.。。)有必要为它们中的每一个获得类似的合适的增强。设计这样的增强可能需要大量的努力和专业知识。
- 因此,自动搜索这些增强将是将BYOL推广到其他模式的重要的下一步。
八、附录中图标的解释
本文的实验数据非常详细,有着很重要参考价值,并且都记录在附录中。
详细见这篇博客:
BYOL:一种新的自监督学习方法
参考
BYOL论文简析——笔记