RNN and Transformer理解
RNN:
参考:
https://github.com/AntoineTheb/RNN-RL/blob/master/algos/PPO.py
https://blog.csdn.net/baishuiniyaonulia/article/details/100051600
https://www.machunjie.com/deeplearning/120.html
https://blog.csdn.net/qq_32146369/article/details/106293327
https://blog.csdn.net/qq_41775769/article/details/121707309
Transformer
参考:
https://colab.research.google.com/drive/1h-RFjV6xqKwQhCBODGHzhmuRiiWtwXpX?usp=sharing#scrollTo=jcnBZY4eFO9i
十分钟理解Transformer - 知乎
【简单理解】Transformer_雾行的博客-CSDN博客_如何理解transformer
Transformer理解_陶将的博客-CSDN博客_transformer理解
Transformer遵循encoder-decoder架构,使用encode和decoder的堆叠自我关注和逐点全连接层,结构见下图:
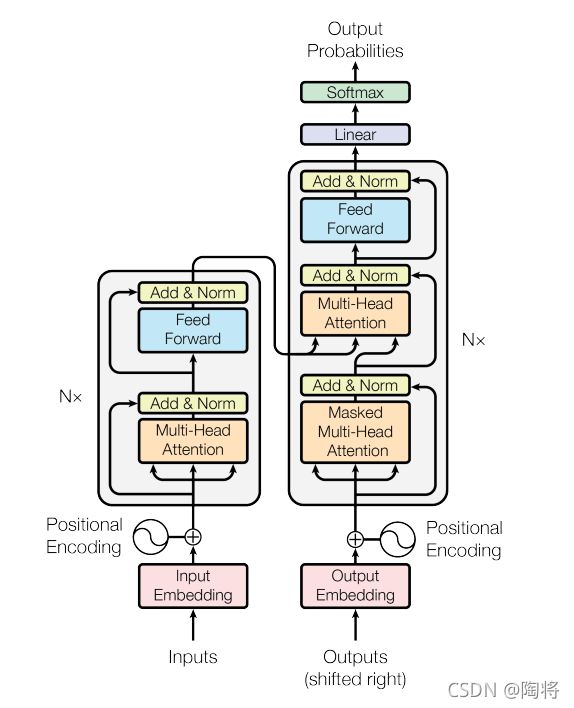
Encoder and Decoder
Encoder:Encoder由N = 6 N=6N=6个相同层的堆栈组成。每层有两个子层。第一种是多头自我注意机制(multi-head self-attention mechanism),第二种是简单的位置全连接前馈网络(a single, position-wise fully connected feed-forward network)。我们在两个子层的每个层周围使用残差连接(residual connection),然后使用层规范化(layer normalization)。也就是说,每个子层的输出是L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm \left( x+Sublayer \left( x \right) \right)LayerNorm(x+Sublayer(x)),其中S u b l a y e r ( x ) Sublayer \left( x \right)Sublayer(x)是由子层本身实现的功能。为了方便这些残差连接,模型中的所有子层以及嵌入层都会生成维数为512的输出, d m o d e l = 512 d_{model} = 512d
model
=512。
Decoder:Decoder也由N = 6 N=6N=6个相同层的堆栈组成。除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。与编码器类似,我们在每个子层周围使用残差连接,然后进行层规范化。我们还修改了解码器堆栈中的自我注意子层,以防止位置转移到后续位置。这种掩蔽,再加上输出嵌入偏移一个位置的事实,确保位置i ii的预测只能依赖于位置小于i ii的已知输出。
Attention
注意函数可以描述为将查询(query)和一组键值对(key-value)映射到输出,其中查询、键、值和输出都是向量。输出可作为这些值的加权和,其中分配给每个值的权重由查询与相应键的兼容函数(compatibility function)计算。
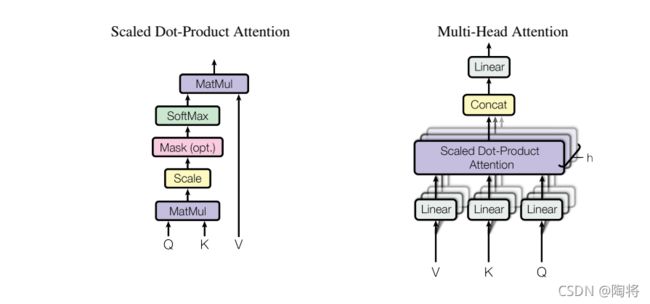
Scaled Dot-Product Attention
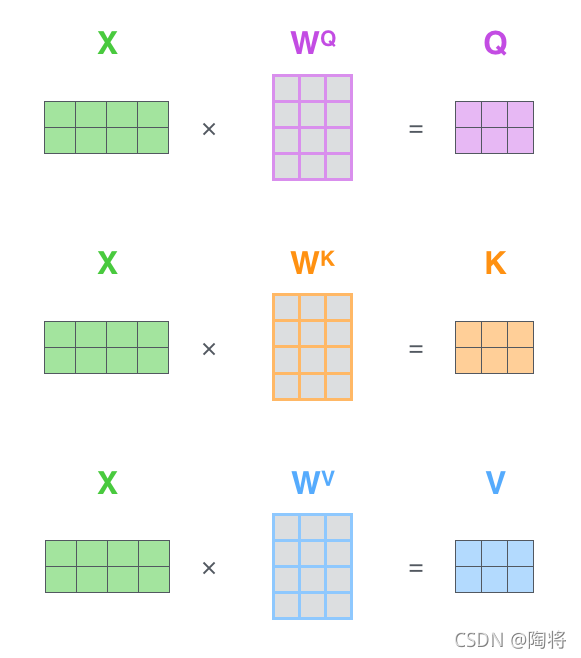
我们之前已经提到过,Self-Attention的输入仅仅是矩阵X的三个线性映射。那么Self-Attention内部的运算具有什么样的含义呢?我们从单个词编码的过程慢慢理解:
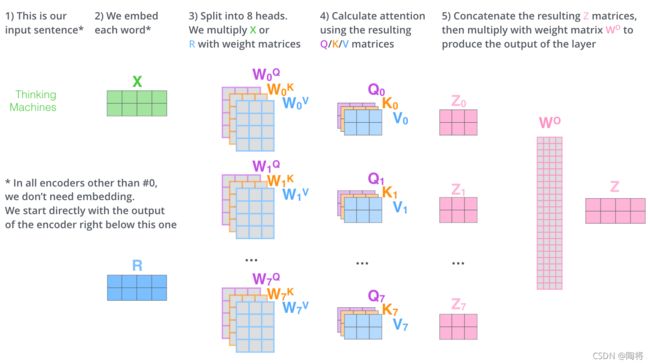
1) 首先,我们对于输入单词向量X生成三个对应的向量: Query, Key 和 Value。注意这三个向量相比于向量X要小的多(论文中X的长度是512,三个向量的长度为64,这只是一种基于架构上的选择,因为论文中的Multi-Head Attention有8个Self-Attention模块,8个Self-Attention的输出要拼接,将其恢复成长度为512的向量),这一个部分是对每个单词独立操作的
2) 用Queries和Keys的点积计算所有单词相对于当前词(图中为Thinking)的得分Score,该分数决定在编码单词“Thinking”时其他单词给予了多少贡献
3) 将Score除以向量维度(64)的平方根(保证Score在一个较小的范围,否则softmax的结果非零即1了),再对其进行Softmax(将所有单词的分数进行归一化,使得所有单词为正值且和为1)。这样对于每个单词都会获得所有单词对该单词编码的贡献分数,当然当前单词将获得最大分数,但也将会关注其他单词的贡献大小
4) 对于得到的Softmax分数,我们将其乘以每一个对应的Value向量
5) 对所得的所有加权向量求和,即得到Self-Attention对于当前词”Thinking“的输出
Multi-Head Attention
Position-wise Feed-Forward Networks
我们之前提到过,由于RNN的时序性结构,所以天然就具备位置编码信息。CNN本身其实也能提取一定位置信息,但多层叠加之后,位置信息将减弱,位置编码可以看作是一种辅助手段。Transformer的每一个词的编码过程使得其基本不具备任何的位置信息(将词序打乱之后并不会改变Self-Attention的计算结果),因此位置向量在这里是必须的,使其能够更好的表达词与词之间的距离。构造位置编码的公式如下所示:

Transformer和RNN区别:
参考:
Transformer和RNN区别_真心乖宝宝的博客-CSDN博客_rnn transformer
RNN
主要特点是:
1.顺序处理:句子必须逐字处理
2.RNN指的是一个序列当前的输出与之前的输出也有关,具体的表现形式为网络会对前面的信息进行记忆,保存在网络的内部状态中,并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包含输入层的输出还包含上一时刻隐藏层的输出
3.它采取线性序列结构不断从前往后收集输入信息
Transformer
主要特点是:
1.非顺序处理:句子是整体处理,而不是逐字处理
2.单个的Transformer Block主要由两部分组成:多头注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward),Transformer Block代替了LSTM和CNN结构作为了我们的特征提取器,使得Transformer不依赖于过去的隐藏状态来捕获对先前单词的依赖性,而是整体上处理一个句子,以便允许并行计算,减少训练时间,并减少由于长期依赖性而导致的性能下降