MySQL索引详解
MySQL索引详解
一、索引概述
索引是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的
- 索引示意图:
我们来直观的感受一下,有建立索引和没有建立索引的直观感觉

如图所示,索引能够帮我们快速的定位到数据的具体位置,高效查询。一般来说,索引本身也很大,不可能全部存储在内存当中,因此索引往往以索引文件的形式存储在磁盘上。索引是用来提供高性能数据库的常用工具。
二、索引类型
MySQL 的索引有不同的角度的分类方式,例如:按数据结构分、按逻辑角度分、按物理存储分、按业务角度分。
1)数据结构
- B-tree: 常见的索引类型
- B+tree: B-tree数据结构上做的优化
- Hash索引(仅Memory引擎支持): 是基于哈希表实现的,只有精确匹配索引所有列的查询才会生效
- Full-text 索引(全文索引,MyISAM引擎支持;InnoDB引擎5.6之后支持): 它的存储结构也是B-Tree
- R-Tree索引(spatial空间索引): R-Tree是B-tree在高维空间的扩展,也叫空间索引,主要用于地理空间数据类型,存储高维数据的平衡树。
2)物理存储
- 聚簇索引:指索引项的排序方式和表中数据记录排序方式一致的索引
- 非聚簇索引:索引顺序与物理存储顺序不同
- 稠密索引:每个索引键值都对应有一个索引项

- 稀疏索引:稀疏索引只为某些搜索码值建立索引记录
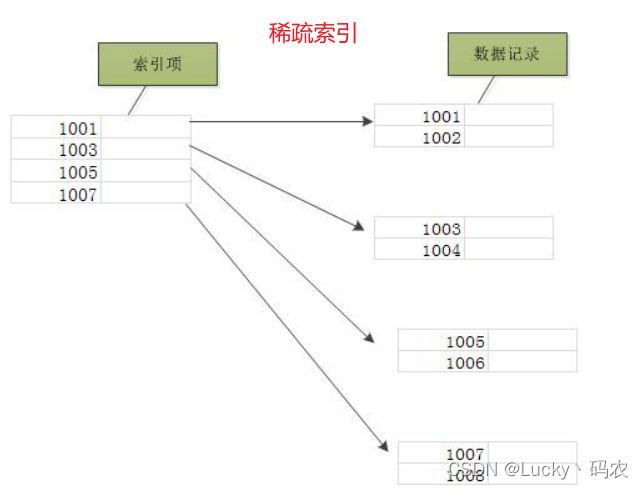
3)逻辑角度
- 主键索引(聚簇索引): 主键索引的叶子节点存储的是一行完整的数据
- 普通索引(单列索引): 非主键索引的叶子节点存储的是主键值
- 多列索引(复合索引、组合索引)
- 唯一索引
- 空间索引
4)业务角度
- 覆盖索引
- 前缀索引
- 辅助索引(非聚集索引)
三、索引支持
MyISAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|---|
| B-Tree索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-Tree 索引 | 不支持 | 支持 | 不支持 |
| Full-Text | 5.6版本之后支持 | 支持 | 不支持 |
我们都知道InnoDB是底层存储文件是分为:.frm(表空间文件)、.idb(索引文件和数据文件);
MyISAM则是分了三个文件:.frm(表空间)、.MYD(数据文件)、MYI(索引文件);
MyISAM没有聚集索引,MyISAM建立的都是普通索引(即使是主键);
MyISAM引擎是没有聚集索引的,因为MyISAM引擎不属于索引组织表,即有单独的空间存储表数据,表数据并不是和主键建立的B+Tree存储在一起的;MyISAM表通过任何索引来查询数据都需要回表查询;
四、索引数据结构
- **树的演变:**二叉树演变平衡二叉树(AVL树)、平衡二叉树演变多路平衡搜索树(B-Tree)、B-Tree演变B+Tree
- **B+Tree相对于B-Tree的改进:**将数据都存放在叶子节点,让每一个磁盘块都能够存储更多的指针,减少IO检索次数,并且叶子节点都加上循环链表,提高区间访问能力
五、聚集索引与非聚集索引
1)概述
聚集索引:也叫聚簇索引(ClusterIndex),一般来说是以主键创建的索引,一张表只能有一个聚集索引,而且只有InnoDB能够创建聚集索引。
非聚集索引:也叫普通索引、辅助索引(Secondary Index),除了聚集索引外的索引都是非聚集索引。
聚集索引的数据存放在B+Tree索引树的叶子节点上,而非聚集索引的B+Tree索引树上只会存储当前索引列的数据与主键索引列的数据,并不会存放整行数据,当需要通过非聚集索引去检索一行数据时,首先非聚集索引通过索引树找到主键,然后通过主键去主键索引的B+Tree上查询出整行的数据;
上面这句话很重要,务必记牢!
比如字典中,用‘拼音’查汉字,就是聚集索引。因为正文中字都是按照拼音排序的。而用‘偏旁部首’查汉字,就是非聚集索引,因为正文中的字并不是按照偏旁部首排序的,我们通过检字表得到正文中的字在索引中的映射,然后通过映射找到所需要的字。
2)使用场景
聚集索引的使用场合为:
a.查询命令的回传结果是以该字段为排序依据的;
b.查询的结果返回一个区间的值;
c.查询的结果返回某值相同的大量结果集。
聚集索引会降低 insert,和update操作的性能,所以,是否使用聚集索引要全面衡量。
非聚集索引的使用场合为:
a.查询所获数据量较少时;
b.某字段中的数据的唯一性比较高时;
非聚集索引必须是稠密索引
3)一、二级索引和聚集、非聚集索引
大家多多少少有听过一些DBA大佬口中经常说一级索引、二级索引吧?啥是一级索引和二级索引???
关于一级索引的定义:索引和数据存储是在一起的,都存储在同一个B+Tree中的叶子节点。一般主键索引都是一级索引。
关于二级索引的定义:二级索引树的叶子节点存储的是本列索引值和主键值;而不是数据。在使用二级索引检索数据时,需要借助一级索引;也就是说,在找到索引后,得到对应的主键,再回到一级索引中找主键对应的数据记录。
咋一看怎么和聚集索引和非聚集索引那么像???
对!一级索引就是聚集索引;二级索引就是非聚集索引!!
4)InnoDB表能不能没有聚集索引?
我们知道InnoDB表是属于索引组织表,整表的数据都需要根据主键(聚集索引)来排序,并且数据也是存储在主键(聚集索引)的B+Tree上的;那么万一我们在表中没有创建主键(聚集索引)那么怎么办呢???
InnoDB必须要有且只有一个主键(聚集索引)!!!不能没有主键(聚集索引)!!!
那奇了怪了,我在InnoDB建表的时候明明可以不创建主键(聚集索引)呀,也没见他报错呀,咋回事????
是这样的,主键(聚集索引)对于InnoDB实在是太重要了,InnoDB不能没有他,如果你不创建他会根据规则来选出较为合适的一列来做聚集索引,实在不行他就帮你创建一个隐藏的列作为聚集索引,规则如下:
(1)如果表定义了主键,则该列就是聚集索引;
(2)如果表没有定义主键,则第一个not null unique列是聚集索引;
(3)以上条件都不满足:InnoDB会创建一个隐藏的row-id作为聚集索引;
现在知道聚集索引对InnoDB来说有多重要了吧???
六、其他索引
1)覆盖索引
1.1 覆盖索引概念
覆盖索引只是一个概念,MySQL官方并没有说明什么是覆盖索引,只为了表达一下"该SQL语句是使用索引覆盖查询的",仅此而已;
覆盖索引(或称索引覆盖):即从二级索引中就可以得到要查询的记录,而不需要查询聚簇索引中的记录(回表查询),很显然,聚簇索引就是一种覆盖索引,因为聚簇索引中包含了数据行的全部数据,而非聚集索引的话,要看SQL语句查询的列是在索引树上,如果不在则需要回表查询;简单的说就是查询的列要被所使用的索引覆盖,换句话说就是查询的列要在索引树上,不需要回表查询。
1.2 覆盖索引应用
使用覆盖索引的SQL语句:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
我们给username列加上索引:
create index idx_name on t_user(username);
- 执行如下SQL:
-- username创建的B+Tree上有值(使用了覆盖索引)
explain select username from t_user where username='xxx';
-- username创建的B+Tree上有值(使用了覆盖索引)
explain select id,username from t_user where username='xxx';
-- username创建的B+Tree上没有值,age列需要回表到聚集索引上去查询(没有使用覆盖索引)
explain select id,username,age from t_user where username='xxx';
上面提一下,有得时候MySQL的执行计划不是非常准确,因为MySQL底层有优化器来优化SQL,所以我们看到的执行计划的信息有得时候可能不是很准确
1.3 覆盖索引总结
覆盖索引:查询的数据被索引树覆盖了,即:查询的数据都在索引树上,不需要回表查询;
2)前缀索引
2.1 前缀索引概念
前缀索引也是一种概念,或者说是操作索引的一种技巧;当索引列的数据是非常大时,那么该列建立的索引会非常大,而且检索速度也会很慢,这个时候我们考虑能否让该列的前面几个字符拿出来建立索引,而不是整列是数据建立索引,因此前缀索引的概念就由此产生;
我们知道前缀索引其实就是拿出该列数据的前几个字符出来建立索引来降低索引的大小,以及加快索引的速度的一种技巧性索引,但是毕竟前面几个字符不能够代替整列数据,有可能重复,我们应该尽量的减低重复的概率,提高不重复的概率,这样的前缀索引检索速度更快;
2.2 前缀索引的应用
- 数据准备:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`birthday` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB ;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '小明', '1999-10-20');
INSERT INTO `student` VALUES (2, '小军', '1999-02-21');
INSERT INTO `student` VALUES (3, '小龙', '1999-01-19');
INSERT INTO `student` VALUES (4, '小刚', '1999-06-06');
INSERT INTO `student` VALUES (5, '小红', '1999-02-05');
- 计算不重复率:
mysql> select 1.0*count(distinct birthday)/count(*) from student;
+---------------------------------------+
| 1.0*count(distinct birthday)/count(*) |
+---------------------------------------+
| 1.00000 |
+---------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,1))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,1))/count(*) |
+-----------------------------------------------+
| 0.20000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,2))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,2))/count(*) |
+-----------------------------------------------+
| 0.20000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,3))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,3))/count(*) |
+-----------------------------------------------+
| 0.20000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,4))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,4))/count(*) |
+-----------------------------------------------+
| 0.20000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,5))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,5))/count(*) |
+-----------------------------------------------+
| 0.20000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,6))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,6))/count(*) |
+-----------------------------------------------+
| 0.40000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,7))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,7))/count(*) |
+-----------------------------------------------+
| 0.80000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,8))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,8))/count(*) |
+-----------------------------------------------+
| 0.80000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> select 1.0*count(distinct left(birthday,9))/count(*) from student;
+-----------------------------------------------+
| 1.0*count(distinct left(birthday,9))/count(*) |
+-----------------------------------------------+
| 1.00000 |
+-----------------------------------------------+
1 row in set (0.00 sec)
dent;
±----------------------------------------------+
| 1.0count(distinct left(birthday,9))/count() |
±----------------------------------------------+
| 1.00000 |
±----------------------------------------------+
1 row in set (0.00 sec)
发现不重复率在`birthday`字段在第9个字符时,达到100%,也就是说,在的倒数第二个字符时,数据没有重复的。