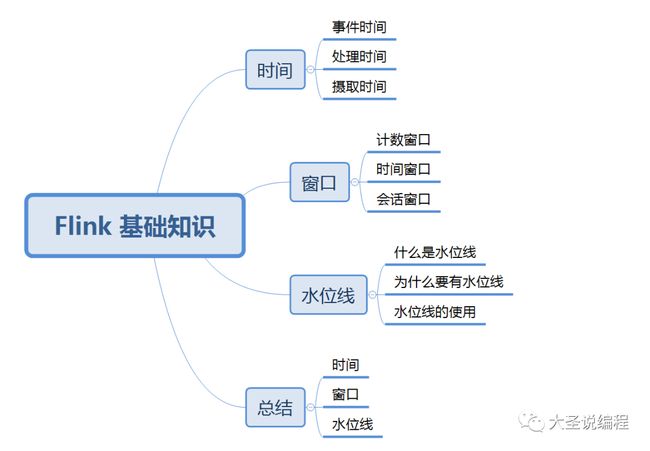
Flink 基础知识 - 时间、窗口、水位线
最近在整理 Flink 方面的知识点,今天更新一遍 Flink 的基础的知识点,让大家对 Flink 的 时间、窗口、水位线 有一个基本的认识,然后下一篇文章会从源码的角度来解析 Flink 在 时间、窗口、水位线 底层是怎么实现的。
话不多说,直接上今天的大纲主题:
时间
Flink 中 定义了 3 种 时间类型:事件时间(Event Time)、处理时间(Processing Time)和摄取时间(Ingestion Time)。
下面画张图来解释一下 3 种 时间类型:
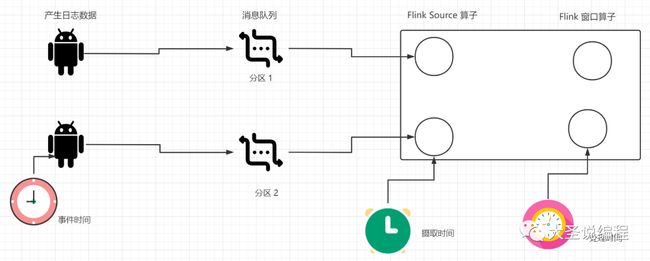
(1)事件时间
事件时间指的是这条数据发生的时间,比如我用手机在某团上 2022-01-01:13:14 这个一时刻下单点了一个外卖,那么下单点外卖的这个时间 2022-01-01:13:14 就是我点外卖这个事件发生的时间,这个时间确定之后就不会改变。
还例如,我们用 Flink 消费 Kafka 里面的日志数据的时候,每条日志里面所包含的时间字段 的时间戳就是事件时间。通过事件时间可以实现时间旅行。
使用事件时间的好处是不依赖服务器的时钟,这一批数据无论你反复执行多少次,得到的结果都是一样的。但是我们使用事件时间的时候,需要从每一条日志数据里面把含有时间戳字段的提取出来。
(2)处理时间
处理时间是指数据被计算引擎(Flink) 处理的时间,这个时间以你 Flink 程序在哪台服务器执行,就以那台服务器的时钟为准。
使用处理时间依赖于操作系统的时钟,但是每台机器的时钟是变化的。比如我开了 2s 的处理时间的窗口去处理数据,但是可能每台服务器的处理数据的能力不一样,可能第一次跑这一批数据的时候,2s 的时间处理了 100 条数据,第二次跑这一批数据的时候,2s 的时间处理了 500 条数据。
这样就会导致两次计算的结果不一样,就是可能是同一台机器也会出现这种情况,因为 处理能力可能受当时 CPU 的影响,在2s 内处理的数据条数不一样。但是处理时间计算逻辑简单,延迟性低性能好于事件时间。
(3)摄取时间
摄取时间是指我们的数据进入 Flink source 算子的时间,摄取时间一般用的比较少,它也会代带来处理数据的结果不正确的情况。
在代码层面怎么使用这三个时间:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//使用处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//使用摄取时间
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
窗口
批处理本质上是处理有限不变的数据集,流处理的本质是处理无限持续产生的数据集,所以批本质上来说是流的一种特例,那么窗口就是流和批统一的桥梁,对流上的数据进行窗口切分。
每一个窗口一旦到了要计算的时候,就可以被看成一个不可变的数据集,在触发计算之前,窗口里面的数据可能会持续的改变,因此对窗口的数据进行计算就是批处理。
Flink 中窗口按照是否并发执行,分为 Keyed Window 和 Non-Keyed Window,它们主要的区别是有没有 keyBy 操作。
Keyed Window 可以按照指定的分区方式并发执行,所有相同的键会被分配到相同的任务上执行。Non-Keyed Window 会把所有数据放到一个任务上执行,并发度为 1。下面是窗口相关的API。
- Keyed Wind
stream
.keyBy(...)
.window(...) // 接受 WindowAssigner 参数,用来分配窗口
[.trigger(...)] // 可选的,接受 Trigger 类型参数,用来触发窗口
[.evictor(...)] // 可选的,接受 Evictor 类型参数,用来驱逐窗口中的数据
// 可选的,接受 Time 类型参数,表示窗口允许的最大延迟,超过该延迟,数据会被丢弃
[.allowedLateness(...)]
// 可选的,接受 OutputTag 类型参数,用来定义抛弃数据的输出
[.sideOutputLateData(...)]
.reduce/aggregate/apply() // 窗口函数
[.getSideOutput(...)] // 可选的,获取指定的 DataStream
- Non-Keyed Windows
stream
.windowAll(...) // 接受 WindowAssigner 参数,用来分配窗口
[.trigger(...)] // 可选的,接受 Trigger 类型参数,用来触发窗口
[.evictor(...)] // 可选的,接受 Evictor 类型参数,用来驱逐窗口中的数据
// 可选的,接受 Time 类型参数,表示窗口允许的最大延迟,超过该延迟,数据会被丢弃
[.allowedLateness(...)]
// 可选的,接受 OutputTag 类型参数,用来定义抛弃数据的输出
[.sideOutputLateData(...)]
.reduce/aggregate/apply() // 窗口函数
[.getSideOutput(...)] // 可选的,获取指定的 DataStream
下面我们来看看上面提到的几个概念。
WindowAssiner:窗口分配器。我们常用的滚动窗口、滑动窗口、会话窗口等就是由 WindowAssiner 决定的,比如 TumblingEventTimeWindows 可以基于事件时间的滚动窗口。
Trigger:触发器。Flink 根据 WindowAssigner 把数据分配到不同的窗口,还需要知道什么时候触发窗口,Trigger 就是用来判断什么时候触发窗口的计算。Trigger 类中定义了一些返回值类型,根据返回值类型来决定是否触发窗口的计算。
Evictor:驱逐器。在窗口触发之后,在调用用户自己写的窗口函数之前或者之后,Flink 允许我们定制要处理的数据集合,Evictor 就是用来驱逐或者过滤不需要的数据集的。
Allowed Lateness:最大允许延迟。主要用在基于事件时间的窗口,表示水位线触发窗口计算之后还允许数据迟到多久,在最长允许的延迟时间内,窗口是不会销毁的。
Window Function:窗口函数。用户代码执行函数,就是用户自己写的业务逻辑,用来做真正计算的。
Side Output:丢弃数据的集合。通过 getSideOutput 方法可以获取丢弃的数据,然后用户自己灵活去处理丢弃的数据。
下面我们来看看 Flink 里面的 计数窗口,时间窗口,会话窗口
(1)计数窗口
这个用到的不多,这里就不做介绍了。
(2)时间窗口
Tumble Time Window(滚动窗口)
图片
表示在时间上按照事先约定的窗口大小(就是你在代码里面指定的窗口大小)进行窗口的切分,窗口之间不会相互重叠。
基于时间的 滚动窗口 又分为 基于 处理时间的 滚动窗口 和 基于事件时间的 滚动窗口。具体如下:
处理时间的 滚动窗口:
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
事件时间的 滚动窗口:
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
Sliding Time Window(滑动窗口)
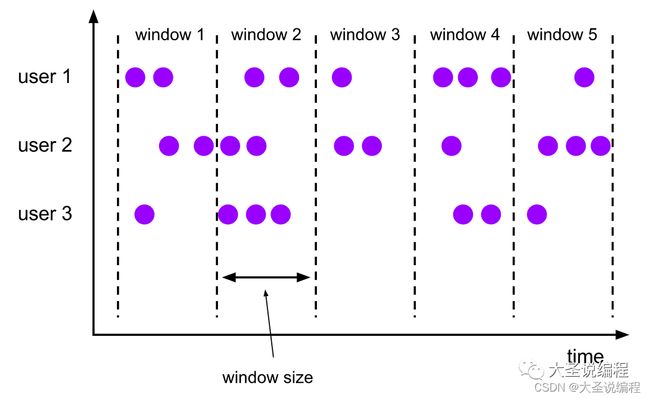
与滚动窗口类似,滑动窗口的 assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置。 滑动窗口需要一个额外的滑动距离(window slide)参数来控制生成新窗口的频率。 因此,如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
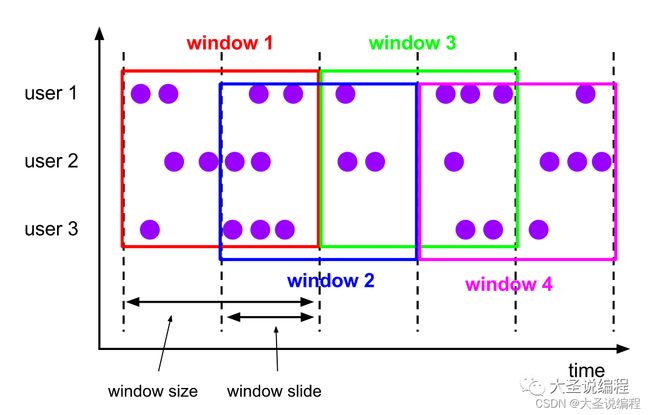
比如说,你设置了大小为 10 分钟,滑动距离 5 分钟的窗口,你会在每 5 分钟得到一个新的窗口, 里面包含之前 10 分钟到达的数据(如上图所示)。
基于时间的 滑动窗口 又分为 基于 处理时间的 滑动窗口 和 基于事件时间的 滑动窗口。具体如下:
处理时间的 滑动窗口:
.window(SlidingProcessingTimeWindows.of(Time.minutes(10), Time.minutes(5)))
事件时间的 滑动窗口:
.window(SlidingEventTimeWindows.of(Time.minutes(10), Time.minutes(5)));
(4) 会话窗口
Session Window 是一种特殊的窗口,当超过一段时间,该窗口没有收到新的数据元素,则视为这个窗口就结束了,所有无法事先确认窗口的长度等。
会话窗口平时工作中,我用到的也比较少,所以这里面不做详解。
水位线
水位线(Watermark) 用于处理乱序事件,而正确的处理乱序事件,通常用 Watermark 机制结合窗口来实现。
从流处理原始设备产生事件,到 Flink 读取到数据,再到 Flink 多个算子处理数据,在这个过程中,会受到网络延迟、数据乱序、背压、Failover 等多种情况的影响,导致数据是乱序的。
虽然大部分情况下是没有问题,但是不得不在设计上考虑此类异常情况,为了保证计算结果的正确性,需要等待数据,这带来了计算的延迟。对于延迟太久的数据,不能无限的等下去,所以必须有一个机制,来保证特定的时间后一定会触发窗口的来进行计算,这个触发机制就是水位线(Watermark)。
下面我们来看一组代码,怎么去使用 Watermark,并且怎么去触发窗口计算:
```java
public class EventTimeExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.socketTextStream("192.168.1.141", 9998, '\n')
.map(new MapFunction<String, TumblingBean>() {
@Override
public TumblingBean map(String value) throws Exception {
String[] s = value.split("\\s");
TumblingBean bean = new TumblingBean();
bean.setUserId(s[0]);
bean.setTime(Long.parseLong(s[1]) * 1000L);
return bean;
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<TumblingBean>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<TumblingBean>() {
@Override
public long extractTimestamp(TumblingBean element, long recordTimestamp) {
System.out.println("水位线的时间戳:" + element.getTime());
return element.getTime();
}
})
)
.keyBy(TumblingBean::getUserId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new EventTimeWindow())
.print();
env.execute();
}
}
class EventTimeWindow extends ProcessWindowFunction<TumblingBean, String, String, TimeWindow> {
@Override
public void process(String s, ProcessWindowFunction<TumblingBean,
String, String, TimeWindow>.Context context, Iterable<TumblingBean> elements, Collector<String> out) throws Exception {
int i = 0;
for (TumblingBean bean : elements) {
i++;
}
out.collect("总共有:" + i + "条数据");
}
}
一看这很多代码,第一反应就是不想看。别急,我这里给你整体说一下这个代码你就懂了,主要逻辑 就是:
-
socketTextStream 读取数据
-
把读取到的数据利用map 算子进行 split 切分
-
然后提取数据中的含有时间的字段,并设置最大延迟时间是 2s
-
接着进行 key 操作
-
最后开了一个 10s 的窗口,等触发了窗口就进行计算
先补充几个重要的概念:
-
水位线(Watermark)就是一个 毫秒的时间戳
-
Flink 默认每隔 200ms (机器时间)向数据流中插入一个 水位线
-
Watermark 是⼀种衡量 Event Time 进展的机制(逻辑时钟),可以设定延迟触发
-
水位线必须单调递增,以确保任务的事件时间在向前推进,而不是在后退
-
只有事件时间需要水位线
-
水位线产生的公式:水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间
-
最大延迟时间由程序员自己设定
数据流中的水位线 用于表示 如果程序已经处理的数据中含有的时间戳都小于 水位线 的话,那么这些数据都已经到达了,所以窗口的触发条件就是
水位线 >= 窗口结束时间
那 这个窗口怎么触发呢? 这是个好问题 水位线 >= 窗口结束时间
我们的程序里 设置的延迟时间是 2s ,窗口结束时间是 10s 但是不包括 10s 因为窗口是左闭又开的
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间
假如 我们 造的测试数据是 每条数据第一个字母是代表key,第二个数字代表这条数据发生的时间
a 1
a 2
b 5
b 4
b 12
说明:
- 当 a 1 这条数据过来时,我们套用上面的公式
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间 = 1 - 2 = -1
窗口触发的条件:
水位线 >= 窗口结束时间 -----> -1 < 10 窗口不触发,数据被保存到状态里面
- 当 a 2 这条数据过来时,我们套用上面的公式
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间 = 2 - 2 = 0
窗口触发的条件:
水位线 >= 窗口结束时间 ----->0 < 10 窗口不触发,数据被保存到状态里面
- 当 b 5 这条数据过来时,我们套用上面的公式
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间 = 5 - 2 = 3
窗口触发的条件:
水位线 >= 窗口结束时间 -----> 3 < 10 窗口不触发,数据被保存到状态里面
- 当 b 4 这条数据过来时,我们套用上面的公式
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间 = 4 - 2 = 2
窗口触发的条件:
水位线 >= 窗口结束时间 -----> 2 < 10 窗口不触发,数据被保存到状态里面
- 当 b 12 这条数据过来时,我们套用上面的公式
水位线 = 系统观察到的最大时间(就是 数据中携带的最大时间戳) - 最大延迟时间 = 12 - 2 = 10
窗口触发的条件:
水位线 >= 窗口结束时间 -----> 10 < 10 窗口触发,计算窗口里面的逻辑
但是 b 12 这条数据 是不在 这次窗口里面的,因为 b 12 不属于 这个窗口。
说明:其实
a 1
a 2
b 5
b 4
b 12
这几条数据中,b 4 是属于乱序数据,因为 先来了一条时间戳是 5 的数据过后了,又来了一条时间戳是 4 的数据 如果不用水位线去等待一下的,默认我们就会把 b 4 这条数据给丢弃了,这就可能导致最后计算的结果不正确。
public class GenWatermark {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//TODO 系统默认每隔200ms机器时间插入一次水位线
//TODO 下面的语句设置为每隔1分钟插入一次水位线
env.getConfig().setAutoWatermarkInterval(60000L);
env
.socketTextStream("192.168.1.141", 9999, '\n')
.map(new MapFunction<String, TumblingBean>() {
@Override
public TumblingBean map(String value) throws Exception {
String[] s = value.split("\\s");
TumblingBean bean = new TumblingBean();
bean.setUserId(s[0]);
bean.setTime(Long.parseLong(s[1]) * 1000L);
return bean;
}
})
.assignTimestampsAndWatermarks(
new MyAssigner()
)
.keyBy(TumblingBean::getUserId)
.window(TumblingEventTimeWindows.of(Time.minutes(10)))
.process(new WaterMarkWindow())
.print();
env.execute();
}
}
class WaterMarkWindow extends ProcessWindowFunction<TumblingBean, String, String, TimeWindow> {
@Override
public void process(String s, ProcessWindowFunction<TumblingBean,
String, String, TimeWindow>.Context context, Iterable<TumblingBean> elements, Collector<String> out) throws Exception {
System.out.println("当前水位线的值为:" + context.currentWatermark() + "\t" + "窗口开始时间:" + context.window().getStart() + "\t" + "窗口结束时间:" + context.window().getEnd());
int i = 0;
for (TumblingBean bean : elements) {
i++;
}
out.collect("总共有:" + i + "条数据");
}
}
class MyAssigner implements AssignerWithPeriodicWatermarks<TumblingBean> {
//TODO 设置最大延迟时间为10s
Long bound = 10 * 1000L;
//TODO 系统观察到的元素包含的最大时间戳
Long maxTs = Long.MIN_VALUE + bound;
@Nullable
@Override
public Watermark getCurrentWatermark() {
System.out.println("观察到的最大时间戳是:" + maxTs);
return new Watermark(maxTs - bound);
}
@Override
public long extractTimestamp(TumblingBean element, long recordTimestamp) {
System.out.println("观察到的数据:" + element.getTime());
maxTs = Math.max(maxTs, element.getTime());
return maxTs;
}
}
下面有一个我自己自定义水位线的逻辑代码,大家感兴趣可以看看
总结
时间,窗口,水位线 这三个是 Flink 中最基础的概念了,同时也是开发过程中用到的最多的东西,只有很好的掌握了 时间,窗口,水位线这些概念,才能按照需求去写出正确的代码,同时在出现窗口不触发的情况下 快速排查到 问题所在。
其实 关于窗口和水位线这块还有很多东西,比如多并行度下 水位线是怎么传递的,允许窗口的最大延迟等,不过小伙伴们放心,接下来这些东西我们都会讲到的。
下一篇文章会从源码的角度来解读,当一条数据来了,我们怎么提前数据里面的时间字段生成水位线的,这条数据怎么分配到对应的窗口的,窗口的数据到底存在哪里了,这些窗口怎么触发的,触发完了怎么进行我们自己写的逻辑运算的,怎么销毁窗口的等。
我会把这部分源码从头到尾讲一遍,让你对这部分的内容的理解更加深刻,另外文章里面涉及到的代码,如果大家想下载下来自己去测试的话,直接加我微信联系我就行了。
