SPDK概览
女主宣言:
SPDK是Intel针对NVMe SSD开源的高性能存储框架,它能够减低IO路径上软件栈所占用的耗时占比,从而尽可能发挥出硬件设备的性能。接下来小编带大家去深入了解SPDK,让我们一起探究它的奥妙所在吧!
PS:丰富的一线技术、多元化的表现形式,尽在"360云计算",点击关注哦!
01简介:

随着硬件设备存储介质的改变和性能不断的提升,存储设备处理IO的能力越来越快,传统的旋转设备HDD单个IO需要几毫秒到十几毫秒不等,而如今的高性能的NVMe SSD已经降低到了微妙级别。

因此出现了一种现象,硬件处理数据的占比在整个IO路径中越来也少,软件处理开销占比越来越高,传统的驱动方式成为了IO性能无法继续提升的罪魁祸首,SPDK由此应运而生。
SPDK主要包含了以下这些特性:
用户态驱动
和常见的驱动在内核中实现不同,SPDK借助于UIO或者VFIO将NVMe驱动移动了用户态,应用可以在用户态直接和SSD进行数据传输,这样相对于内核驱动带来的好处是:消除了IO调用时的上下文切换;去除了用户空间和内核空间的数据拷贝操作;有效地降低了IO延迟。
轮询
在内核驱动中,当IO提交到设备时,进程会进入睡眠状态,当数据传输完毕,设备会发起中断从而将进程唤醒,到此整个IO就处理完毕;在SPDK中,并没有使用中断的方式,而是使用轮询的方式检查IO是否完成,当IO完成时,使用异步的方式进行回调,消除了中断的CPU消耗和避免IO延迟抖动。
无锁
SPDK中的进程使用了绑核无锁机制,进程间使用无锁队列进行通信,避免了锁资源竞争导致IO延迟抖动。
02架构:

如上图,是SPDK的整体架构,从下至上,最底层是最核心的用户态NVMe驱动,这是SPDK的基石;再往上一层是基于用户态驱动程序构建的存储服务,从后文的分析可知,这部分主要是统一抽象的块设备层,包含了用户空间块设备语义的抽象和多个不同后端存储实现;在块设备之上,SPDK提供了标准存储协议的实现,使得SPDK可以为通用存储客户端提供高性能的存储服务。
除此之外,SPDK还包含了用于管理运行环境、不同层内的管理开发工具,方便开发者的日常开发测试;为了适配更多的使用环境,SPDK也集成了不同的社区组件、如用户空间TCP/IP协议栈VPP、KV存储引擎RocksDB、缓存加速框架OCF等。
驱动层:

用户态驱动是SPDK构建其他服务的基础,主要实现了基于PCIe的NVMe协议,用于在用户态驱动NVMe SSD,也实现了NVMe-over-Fabric(NVMe-oF)用于连接网络的NVMe设备,其中Fabric在SPDK中支持RDMA和TCP两种实现方式;驱动层还包含了其他两类驱动,Virtio用于加速虚拟机IO,I/OAT是通过提高数据拷贝效率的IO加速引擎。
存储服务层

存储服务层主要在用户空间对块设备语义进行了统一封装抽象,并开发了不同的实现,用于支持不同的后端存储,比如NVMe bdev支持SPDK NVMe驱动管理本地NVMe SSD或则使用NVMe-oF连接远端服务器的NVMe SSD,Ceph RBD用于对接Ceph块存储,AIO和uring等则使用不同的IO模型管理内核块设备;有一类bdev被称为vbdev,它们基于原本的bdev之上实现了一定的功能,比如逻辑卷管理、分区表、缓存加速等,对于更上层的应用来说,它们还是属于bdev。
bdev本身并没有任何元数据,服务重启需要手动或则使用配置文件重新进行配置,blobstore则是基于bdev之上的具有持久化元数据的存储引擎,如果bdev具有持久化能力,则blobstore能够在掉电后进行恢复,blobstore将整个bdev分成blob进行管理,支持对blob进行创建、删除、写入、读取、快照、克隆、flatten等操作;blobfs则是基于blobstore实现的简易文件系统,一个文件会对应一个blob,本身不兼容POSIX语义,目前的只能对文件进行追加写,不能修改,主要用于和RocksDB进行集成用于作为高性能的KV存储;
存储协议层

SPDK在存储协议层主要实现了基于网络的块存储协议,将bdev暴露到网络中供其他服务进行使用,除了支持NVMe-oF协议之外,还支持iSCSI、nbd等协议;由于bdev层屏蔽掉了后端存储的实现,所以可以按需使用不同的协议将bdev进行暴露,如将Ceph RBD暴露成NVMe设备给客户端使用。
03应用编程框架:

用户态无锁的NVMe驱动在使用的过程中,如果不能在上层应用中消除IO锁或则应用IO线程模型使用不当,很容易造成无法发挥软硬件性能的问题,因此,SPDK提供了一套标准的应用框架,业务应用可以根据自身情况集成到这套框架中或则参照其进行设计,上面提到的块设备bdev以及更上层的标准协议服务都运行在这套框架之内。
SPDK应用在启动的时候,可以指定线程数量,用掩码的方式进行标识,标识在那几个指定的CPU核上运行,如上图所示,一个核就会运行一个线程,SPDK把它称为reactor,下面解释一下各个概念:
reactor:对应一个线程,一个CPU核上就只有一个,框架中所有的reactor被组织成一个数组,指定的CPU核的reactor放在数组中的固定位置。
Events Ring:属于reactor中的结构,一个Reactor只有一个Events Ring,它是DPDK实现的MPSC(多生产者单消费者)无锁循环队列,用于完成不同Reactor之间的通信;当一个Reactor需要发送消息给另一个Reactor时,只要将消息放到对应Reactor的Events Ring中即可,接收到消息的Rector取出消息后就就会将消息删除。
Thread:属于reactor中的结构,包括一个或者多个。
pollers:一个Thread会包括三类poller,active_poller用于包括多个不断运行的消息,timed_poller用于包括多个定时运行的消息,pased_poller则表示暂停运行的消息,可以再次重启运行。
io_channel:一个Thread可以包括多个io_channel,每个channel对应了一个具体的后端实现,例如,在bdev层进行IO之前,需要获取对应设备的io_channel。
msg ring:一个Thread包含了一个MPSC(多生产者单消费者的)消息环,用于存储那些只运行一次的消息;它和poller的区别是,poller内的方法只要不注销,就会不断的运行,而msg ring中的消息运行一次后就会删除。
Reactor线程就是一个while死循环,首先会检查Events Ring是否有消息,有消息则进行处理,然后轮询每一个Thread,处理msg ring,运行poller,如此循环往复。
04基本应用:
编译
下载源码
$ git clone https://github.com/spdk/spdk
$ cd spdk
$ git submodule update --init
安装编译依赖
$ sudo scripts/pkgdep.sh --all
编译
$ ./configure --help
$ ./configure
$ make -j24
性能测试
为了尽可能的发挥SPDK的性能,该测试使用了SPDK自带的perf工具而非fio,随机的IO大小都为4k。
单核单盘
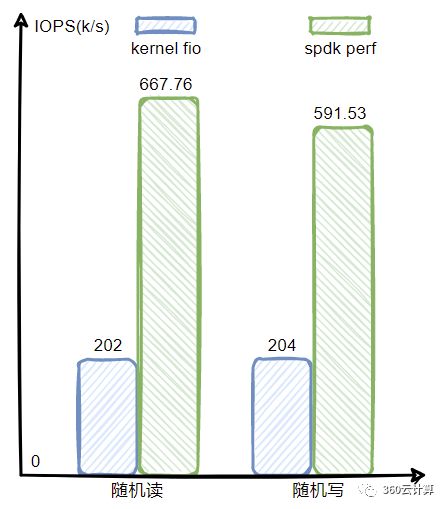
从测试结果可看出,单核单盘的情况下,kernel NVMe驱动只能达到200k+的IOPS,但是SPDK能发挥出几乎设备的全部性能,达到了600k+的IOPS。
单核4盘

对比单核单盘的测试结果,可以看出SPDK的性能随着SSD盘的数量呈现线性增长的趋势,单个CPU核就能驱动多个SSD磁盘,而kernel NVMe驱动在单块磁盘下CPU就已经成为了瓶颈。
05总结:
SPDK作为用户态的框架,基于传统存储开发的应用并不能直接使用,需要进行相应的开发和移植,并且SPDK为了集成方便,已经对RocksDB、VPP、OCF等进行了适配;以上,本文对SPDK的引入、主要特性以及SPDK架构进行了简要介绍,最后对SPDK进行了基本的使用和性能测试,后续还会对SPDK的bdev、blobstore以及blobfs进行深入分析。
参考文章
SPDK document
Accelerate Your NVMe Drives with SPDK
Why SPDK?