1.8.6 Spark与Iceberg整合查询操作
1.8.6.1 DataFrame API加载Iceberg中的数据
Spark操作Iceberg不仅可以使用SQL方式查询Iceberg中的数据,还可以使用DataFrame方式加载Iceberg表中的数据,可以通过spark.table(Iceberg表名)或者spark.read.format("iceberg").load("iceberg data path")来加载对应Iceberg表中的数据,操作如下:
val spark: SparkSession = SparkSession.builder().master("local").appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//1.创建Iceberg表,并插入数据
spark.sql(
"""
|create table hadoop_prod.mydb.mytest (id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.mydb.mytest values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)
//1.SQL 方式读取Iceberg中的数据
spark.sql("select * from hadoop_prod.mydb.mytest").show()
/**
* 2.使用Spark查询Iceberg中的表除了使用sql 方式之外,还可以使用DataFrame方式,建议使用SQL方式
*/
//第一种方式使用DataFrame方式查询Iceberg表数据
val frame1: DataFrame = spark.table("hadoop_prod.mydb.mytest")
frame1.show()
//第二种方式使用DataFrame加载 Iceberg表数据
val frame2: DataFrame = spark.read.format("iceberg").load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
frame2.show()
====我的测试=====
package com.shujia.spark.iceberg
import org.apache.spark.sql.{DataFrame, SparkSession}
object DFUseIceberg {
def main(args: Array[String]): Unit = {
/**
*Spark操作Iceberg不仅可以使用SQL方式查询Iceberg中的数据,还可以使用DataFrame方式加载Iceberg表中的数据,
* 可以通过spark.table(Iceberg表名)或者spark.read.format("iceberg").load("iceberg data path")
* 来加载对应Iceberg表中的数据,操作如下:
*
*/
//由于需要用到hdfs的路径来找到对应的表,我们现在不用hive-catalog而是是使用hadoop-catalog;
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
//1.创建Iceberg表,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.mydb.df_use (id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.mydb.df_use values (4,"xx",22),(5,"cc",19),(6,"vv",20)
""".stripMargin)
//1.SQL 方式读取Iceberg中的数据
spark.sql("select * from hadoop_prod.mydb.df_use").show()
/**
* 2.使用Spark查询Iceberg中的表除了使用sql 方式之外,还可以使用DataFrame方式,建议使用SQL方式
*/
//第一种方式使用DataFrame方式查询Iceberg表数据
val frame1: DataFrame = spark.table("hadoop_prod.mydb.df_use")
frame1.show()
//第二种方式使用DataFrame加载 Iceberg表数据
val frame2: DataFrame = spark.read.format("hadoop_prod")
.load("hdfs://master:9000/spark/mydb/df_use")
frame2.show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.DFUseIceberg spark-1.0.jar
}
}1.8.6.2 查询表快照
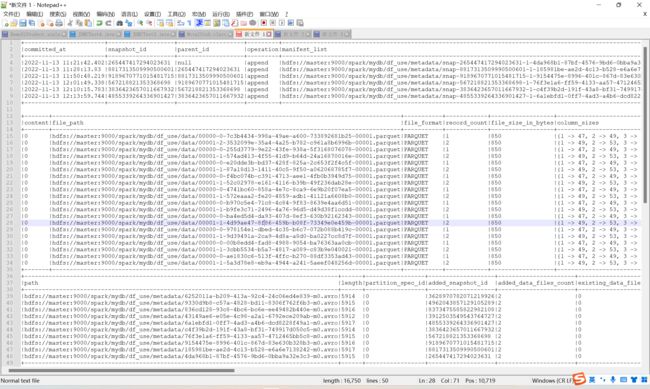
每次向Iceberg表中commit数据都会生成对应的一个快照,我们可以通过查询“* c*a*t*a*l*o*g*名称.{库名}.${Iceberg表}.snapshots** ”来查询对应Iceberg表中拥有的所有快照,操作如下:
//向表 hadoop_prod.mydb.mytest 中再次插入以下数据
spark.sql(
"""
|insert into hadoop_prod.mydb.mytest values (4,"ml",18),(5,"tq",19),(6,"gb",20)
""".stripMargin)
//3.查看Iceberg表快照信息
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.snapshots
""".stripMargin).show(false)结果如下:

1.8.6.3 查询表历史
对Iceberg表查询表历史就是查询Iceberg表快照信息内容,与查询表快照类似,通过“c*a*t*a*l*o*g*名称.{库名}.${Iceberg表}.history*** ”命令进行查询,操作如下:
//4.查询表历史,实际上就是表快照的部分内容
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.history
|
""".stripMargin).show(false)结果如下:

1.8.6.4 查询表data files
我们可以通过”c*a*t*a*l*o*g*名称.{库名}.${Iceberg表}.files*** ”命令来查询Iceberg表对应的data files 信息,操作如下:
//5.查看表对应的data files
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.files
""".stripMargin).show(false)结果如下:

1.8.6.5 查询Manifests
我们可以通过“c*a*t*a*l*o*g*名称.{库名}.${Iceberg表}.manifests*** ”来查询表对应的manifests信息,具体操作如下:
//6.查看表对应的 Manifests
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.manifests
""".stripMargin).show(false)结果如下:

1.8.6.6 查询指定快照数据
查询Iceberg表数据还可以指定snapshot-id 来查询指定快照的数据,这种方式可以使用DataFrame Api方式来查询,Spark3.x版本之后也可以通过SQL 方式来查询,操作如下:
//7.查询指定快照数据,快照ID可以通过读取json元数据文件获取
spark.read
.option("snapshot-id",3368002881426159310L)
.format("iceberg")
.load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
.show()结果如下:

Spark3.x 版本之后,SQL指定快照语法为:
CALL ${Catalog 名称}.system.set_current_snapshot("${库名.表名}",快照ID)操作如下:
//SQL 方式指定查询快照ID 数据
spark.sql(
"""
|call hadoop_prod.system.set_current_snapshot('mydb.mytest',3368002881426159310)
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show()结果如下:

1.8.6.7 根据时间戳查询数据
Spark读取Iceberg表可以指定“as-of-timestamp ”参数,通过指定一个毫秒时间参数查询Iceberg表中数据,iceberg会根据元数据找出timestamp-ms <= as-of-timestamp 对应的 snapshot-id ,也只能通过DataFrame Api把数据查询出来,Spark3.x版本之后支持SQL指定时间戳查询数据。具体操作如下:
//8.根据时间戳查询数据,时间戳指定成毫秒,iceberg会根据元数据找出timestamp-ms <= as-of-timestamp 对应的 snapshot-id ,把数据查询出来
spark.read.option("as-of-timestamp","1640066148000")
.format("iceberg")
.load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
.show()结果如下:

Spark3.x 版本之后,SQL根据时间戳查询最近快照语法为:
CALL ${Catalog 名称}.system.rollback_to_timestamp("${库名.表名}",TIMESTAMP '日期数据')操作如下:
//省略重新创建表mytest,两次插入数据
//SQL 方式查询指定 时间戳 快照数据
spark.sql(
"""
|CALL hadoop_prod.system.rollback_to_timestamp('mydb.mytest', TIMESTAMP '2021-12-23 16:56:40.000')
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show()结果如下:

1.8.6.8 回滚快照
在Iceberg中可以回滚快照,可以借助于Java 代码实现,Spark DataFrame Api 不能回滚快照,在Spark3.x版本之后,支持SQL回滚快照。回滚快照之后,Iceberg对应的表中会生成新的Snapshot-id,重新查询,回滚生效,具体操作如下:
//9.回滚到某个快照,rollbackTo(snapshot-id),指定的是固定的某个快照ID,回滚之后,会生成新的Snapshot-id, 重新查询生效。
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
catalog.setConf(conf)
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
table.manageSnapshots().rollbackTo(3368002881426159310L).commit()注意:回滚快照之后,在对应的Iceberg表中会生成新的Snapshot-id,再次查询后,会看到数据是回滚快照之后的数据。
//查询表 hadoop_prod.mydb.mytest 数据,已经是历史数据
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show(100)Spark3.x 版本之后,SQL回滚快照语法为:
CALL ${Catalog 名称}.system.rollback_to_snapshot("${库名.表名}",快照ID)操作如下:
//省略重新创建表mytest,两次插入数据
//SQL方式回滚快照ID,操作如下:
spark.sql(
"""
|Call hadoop_prod.system.rollback_to_snapshot("mydb.mytest",5440886662709904549)
""".stripMargin)
//查询表 hadoop_prod.mydb.mytest 数据,已经是历史数据
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show(100)结果如下:

1.8.6.9 合并Iceberg表的数据文件
针对Iceberg表每次commit都会生成一个parquet数据文件,有可能一张Iceberg表对应的数据文件非常多,那么我们通过Java Api 方式对Iceberg表可以进行数据文件合并,数据文件合并之后,会生成新的Snapshot且原有数据并不会被删除,如果要删除对应的数据文件需要通过“Expire Snapshots来实现 ”,具体操作如下:
//10.合并Iceberg表的数据文件
// 1) 首先向表 mytest 中插入一批数据,将数据写入到表mytest中
import spark.implicits._
val df: DataFrame = spark.read.textFile("D:\\2018IDEA_space\\Iceberg-Spark-Flink\\SparkIcebergOperate\\data\\nameinfo")
.map(line => {
val arr: Array[String] = line.split(",")
(arr(0).toInt, arr(1), arr(2).toInt)
}).toDF("id","name","age")s
df.writeTo("hadoop_prod.mydb.mytest").append()经过以上插入数据,我们可以看到Iceberg表元数据目录如下:

数据目录如下:

//2) 合并小文件数据,Iceberg合并小文件时并不会删除被合并的文件,Compact是将小文件合并成大文件并创建新的Snapshot。如果要删除文件需要通过Expire Snapshots来实现,targetSizeInBytes 指定合并后的每个文件大小
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
Actions.forTable(table).rewriteDataFiles().targetSizeInBytes(1024)//1kb,指定生成合并之后文件大小
.execute()合并小文件后,Iceberg对应表元数据目录如下:

数据目录如下:

1.8.6.10 删除历史快照
目前我们可以通过Java Api 删除历史快照,可以通过指定时间戳,当前时间戳之前的所有快照都会被删除(如果指定时间比最后一个快照时间还大,会保留最新快照数据),可以通过查看最新元数据json文件来查找要指定的时间。例如,表mytest 最新的json元数据文件信息如下:
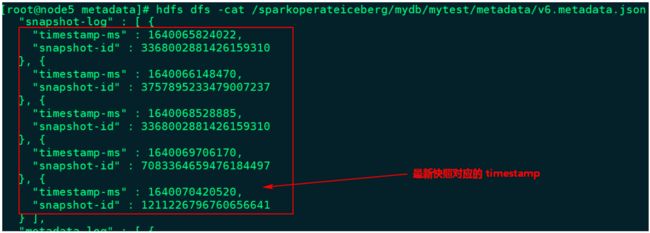
这里删除时间为“1640070000000”之前的所有快照信息,在删除快照时,数据data目录中过期的数据parquet文件也会被删除(例如:快照回滚后不再需要的文件),代码操作如下:
//11.删除历史快照,历史快照是通过ExpireSnapshot来实现的,设置需要删除多久的历史快照
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
table.expireSnapshots().expireOlderThan(1640070000000L).commit()以上代码执行完成之后,可以看到只剩下最后一个快照信息:

数据目录如下:

注意:删除对应快照数据时,Iceberg表对应的Parquet格式数据也会被删除,到底哪些parquet文件数据被删除决定于最后的“snap-xx.avro”中对应的manifest list数据对应的parquet数据,如下图所示:
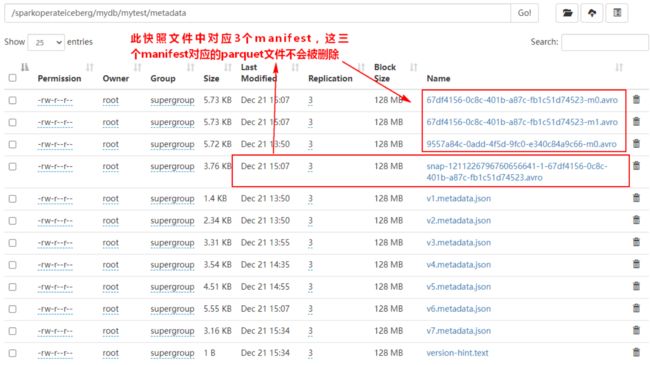
随着不断删除snapshot,在Iceberg表不再有manifest文件对应的parquet文件也会被删除。
除了以上这种使用Java Api方式来删除表旧快照外,在Spark3.x版本之后,我们还可以使用SQL方式来删除快照方式,SQL删除快照语法为:
//删除早于某个时间的快照,但保留最近N个快照
CALL ${Catalog 名称}.system.expire_snapshots("${库名.表名}",TIMESTAMP '年-月-日 时-分-秒.000',N)注意:以上使用SQL方式采用上述方式进行操作时,SparkSQL执行会卡住,最后报错广播变量广播问题(没有找到好的解决方式,目测是个bug问题)
每次Commit生成对应的Snapshot之外,还会有一份元数据文件“Vx-metadata.json”文件产生,我们可以在创建Iceberg表时执行对应的属性决定Iceberg表保留几个元数据文件,属性如下:
| Property | Description |
|---|---|
| write.metadata.delete-after-commit.enabled | 每次表提交后是否删除旧的元数据文件 |
| write.metadata.previous-versions-max | 要保留旧的元数据文件数量 |
例如,在Spark中创建表 test ,指定以上两个属性,建表语句如下:
CREATE TABLE ${CataLog名称}.${库名}.${表名} (
id bigint,
name string
) using iceberg
PARTITIONED BY (
loc string
) TBLPROPERTIES (
'write.metadata.delete-after-commit.enabled'= true,
'write.metadata.previous-versions-max' = 3
)关于查询快照,表历史,data files Manifests 查询快照,时间戳数据我的测试代码如下:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object ScanSnapshots {
def main(args: Array[String]): Unit = {
/**
*
* 每次向Iceberg表中commit数据都会生成对应的一个快照,我们可以通过查询“catalog名称.{库名}.${Iceberg表}.snapshots ”
* 来查询对应Iceberg表中拥有的所有快照,操作如下:
*
*/
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
//向表 hadoop_prod.mydb.mytest 中再次插入以下数据
spark.sql(
"""
|insert into hadoop_prod.mydb.df_use values (4,"ml",18),(5,"tq",19),(6,"gb",20)
""".stripMargin)
//3.查看hadoop_prod表快照信息
spark.sql(
"""
|select * from hadoop_prod.mydb.df_use.snapshots
|
""".stripMargin).show(false)
/**
*
* 我们可以通过”catalog名称.{库名}.${Iceberg表}.files ”命令来查询Iceberg表对应的data files 信息,操作如下:
*
*/
//4.查询表历史,实际上就是表快照的部分内容
spark.sql(
"""
|select * from hadoop_prod.mydb.df_use.history
""".stripMargin).show(false)
//5.查看表对应的data files
spark.sql(
"""
|select * from hadoop_prod.mydb.df_use.files
""".stripMargin).show(false)
//6.查看表对应的 Manifests
spark.sql(
"""
|select * from hadoop_prod.mydb.df_use.manifests
|
""".stripMargin).show(false)
//SQL 方式指定查询快照ID 数据
/**
*
* Spark3.x 版本之后,SQL根据时间戳查询最近快照语法为:虽然我的是Spark3.x版本,但是我的用不了。报错。
*
* 不知道是否是版本的问题,我通过下列方法不能查询到数据 大致意思是不能识别 call 的方法:
*
*
* 报错如下:
Exception in thread "main" org.apache.spark.sql.catalyst.parser.ParseException:
mismatched input 'CALL' expecting {'(', 'ADD', 'ALTER', 'ANALYZE', 'CACHE', 'CLEAR', 'COMMENT', 'COMMIT', 'CREATE', 'DELETE', 'DESC', 'DESCRIBE', 'DFS', 'DROP', 'EXPLAIN', 'EXPORT', 'FROM', 'GRANT', 'IMPORT', 'INSERT', 'LIST', 'LOAD', 'LOCK', 'MAP', 'MERGE', 'MSCK', 'REDUCE', 'REFRESH', 'REPLACE', 'RESET', 'REVOKE', 'ROLLBACK', 'SELECT', 'SET', 'SHOW', 'START', 'TABLE', 'TRUNCATE', 'UNCACHE', 'UNLOCK', 'UPDATE', 'USE', 'VALUES', 'WITH'}(line 2, pos 0)
== SQL ==
CALL hadoop_prod.system.set_current_snapshot('mydb.df_use',265447417294023631)
^^^
*/
// spark.sql(
// """
// |CALL hadoop_prod.system.set_current_snapshot('mydb.df_use',265447417294023631)
// |
// """.stripMargin)
// spark.sql(
// """
// |select * from hadoop_prod.mydb.df_use
// |
// """.stripMargin).show()
//省略重新创建表mytest,两次插入数据
//SQL 方式查询指定 时间戳 快照数据
// spark.sql(
// """
// |CALL hadoop_prod.system.rollback_to_timestamp('mydb.df_use', TIMESTAMP '2021-12-23 16:56:40.000')
// """.stripMargin)
// spark.sql(
// """
// |select * from hadoop_prod.mydb.df_use
// """.stripMargin).show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.ScanSnapshots spark-1.0.jar
/**
*
* 查询Iceberg表数据还可以指定snapshot-id 来查询指定快照的数据,
* 这种方式可以使用DataFrame Api方式来查询,Spark3.x版本之后也可以通过SQL 方式来查询,操作如下:
*
* 测试成功!
*/
//7.查询指定快照数据,快照ID可以通过读取json元数据文件获取
// spark.read
// .option("snapshot-id",567218821353368698L)
// .format("iceberg")
// .load("hdfs://master:9000/spark/mydb/df_use")
// .show()
//
}
}