Python数据分类汇总与统计
笔记
目录
前言
一、Groupby分类统计
1.按列分组
2.遍历各分组
二、数据聚合
1. groupby的聚合函数
2. 逐列及多函数应用
3. 返回不含行索引的聚合数据
三、Apply函数
1.计算平均值
2.计算总和
3.计算平方根
4.用于填充缺失值
四、数据透视表与交叉表
1. 数据透视表
2 .交叉表
五、数据采样
前言
掌握python的groupby分类统计函数
掌握python数据聚合方法
掌握python的Apply函数用法
掌握python数据透视表与交叉表
掌握python数据采样方法

一、Groupby分类统计
1.按列分组
按列分组分为以下三种模式
第一种: df.groupby(col),返回一个按列进行分组的groupby对象第
二种:df.groupby([col1,col2]),返回一个按多列进行分组的groupby对象;
第三种: df.groupby(col1)[col2] 或者 df[col2].groupby(col1),两者含义相同,返回按列col1进行分组后col2的值;
#数据集为第十一届泰迪杯b题数据
import pandas as pd
database=pd.read_csv('../data/order_train2.csv')#导入数据
#第一
a=database.groupby('sales_region_code')
#第二
b=database.groupby(['sales_region_code','second_cate_code'])
#第三
c=database.groupby('sales_region_code')['ord_qty']
groupby对象不能直接打印输出,可以调用list函数显示分组,还可以对这个对象进行各种计算
2.遍历各分组
对于多重键的情况,元组的第一个元素将会是由键值组成的元组
for i in :
print(i)当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算将这些数据片段做成一个字典
pieces = dict(list(a))
print(pieces)
pieces['101']groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。拿上面例子中的database来说,我们可以根据dtype对列进行分组
grouped=database.groupby(database.dtypes, axis=1)可以如下打印分组
for i,j in grouped:
print(i)
print(j)二、数据聚合
聚合指的是任何能够从数组产生标量值的数据转换过程,下表是经过优化的groupby方法:
| 函数名 |
说明 |
| count |
分组中非NA值的数量 |
| sum |
非NA值的和 |
| mean |
非NA值的平均值 |
| median |
非NA值的算数中位数 |
| std、var |
无偏标准差和方差 |
| min、max |
非NA值的最小值和最大值 |
| prod |
非NA值的积 |
| first、last |
第一个和最后一个非NA值 |
1. groupby的聚合函数
[例8]使用groupby聚合函数对数据进行统计分析
关键技术:采用describe()函数求各种统计值:
#根据sales_region_code进行分组并计算ord_qty在分组后的统计值
addressqty1=database.groupby('sales_region_code')['ord_qty'].describe()关键技术:采用mean()函数求均值
addressqty1=database.groupby('sales_region_code')['ord_qty'].mean()关键技术:采用count()和size()函数求计数
size跟count的区别是:size计数时包含NaN值,而count不包含NaN值
addressqty1=database.groupby('sales_region_code')['ord_qty'].count()
addressqty1=database.groupby('sales_region_code')['ord_qty'].size()[例]采用agg()函数对数据集进行聚合操作
关键技术:采用agg()函数进行聚合操作
agg函数也是我们使用pandas进行数据分析过程中,针对数据分组常用的一条函数。如果说用groupby进行数据分组,可以看做是基于行(或者说是index)操作的话,则agg函数则是基于列的聚合操作
1.采用agg()函数计算价格与需求量的求和与均值
database[['item_price','ord_qty']].agg(['sum','meam'])2.采用agg()函数使用不同的聚合函数
database.agg({'item_price':['sum'],'ord_qty':['meam']})2. 逐列及多函数应用
[例]同时使用groupby函数和agg函数进行数据聚合操作
关键技术:groupby函数和agg函数的联用
在我们用pandas对数据进行分组聚合的实际操作中,很多时候会同时使用groupby函数和agg函数
addressqty1=database.groupby('sales_region_code').agg(['min','max','mean'])多重函数以字典形式传入:
d_age={'Age':['min','max','mean']}
addressqty1=database.groupby('sales_region_code').agg(d_age)在我们对数据进行聚合的过程中,除了使用sum()、max()等系统自带的聚合函数之外,大家也可以使用自己定义的函数,使用方法也是一样的
cateqty=database.groupby('sales_region_code')['item_price']
#创建函数
def peak_to_peak(arr):
return arr.max()-arr.min()
#使用函数
cateqty.agg(peak_to_peak)
[例11]同时使用groupby函数和agg函数进行数据聚合操作,并且一次应用多个函数
关键技术:对于自定义或者自带的函数都可以用agg传入,一次应用多个函数 。传入函数组成的list。所有的列都会应用这组函数
如果希望对不同的列使用不同的聚合函数,或一次应用多个函数,将通过下面的例来进行展示。首先,根据item_price和ord_qty对database进行分组,然后采用agg()方法一次应用多个函数
database[['item_price','ord_qty']].agg(['std','meam','peak_to_peak'])如果传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名。如果不想接收GroupBy自动给出的那些列名,那么如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射)
database[['item_price','ord_qty']].agg([('方差','std'),('平均值','meam')])对于DataFrame,你可以定义一组应用于全部列的一组函数,或不同的列应用不同的函数。假设我们想要对item_price和ord_qty列计算三个统计
func=['min','max','mean']
addressqty1=database.groupby(['item_price','ord_qty']).agg(func)3. 返回不含行索引的聚合数据
到目前为止,所有例中的聚合数据都有由唯一的分组键组成的索引(可能还是层次化的)。.由于并不总是需要如此,所以你可以向groupby传入as_index=False以禁用该功能
[例]采用参数as_index返回不含行索引的聚合数据
关键技术:可以向groupby传入as_index=False以禁用索引功能
database.groupby(['sales_region_code','second_cate_code'],as_index=False).mean()三、Apply函数
一般性的“拆分-应用-合并”
Apply函数会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起
函数语法:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
1.func 代表的是传入的函数或 lambda 表达式
2.axis 参数可提供的有两个,该参数默认为0/列
(1) 0 或者 index ,表示函数处理的是每一列
(2) 1 或 columns ,表示处理的是每一行
3.raw bool 类型,默认为 False
(1)False ,表示把每一行或列作为 Series 传入函数中
(2)True,表示接受的是 ndarray 数据类型
1.计算平均值
axis=0时处理列,axis=1时处理行,默认axis=0
a=database.groupby(['sales_region_code','second_cate_code'])['ord_qty'].apply(np.mean)
a2.计算总和
a=database.groupby(['sales_region_code','second_cate_code'])['ord_qty'].apply(np.sum)3.计算平方根
a=database.groupby(['sales_region_code','second_cate_code'])['ord_qty'].apply(np.sqrt)4.用于填充缺失值
import pandas as pd
df=pd.read_csv('data.csv')#导入数据
fill_mean=lambda g: g.fillna(g.mean())
df.apply(fill_mean)四、数据透视表与交叉表
1. 数据透视表
pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),pivot_table函数可以产生类似于excel数据透视表的结果,相当的直观。其中参数index指定“行”键,columns指定“列”键。
函数形式:
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True)
参数说明:
data = 原始数据,要应用透视表的数据框
index = 用于分组的列名或其他分组键,出现在结果透视表的行
columns = 用于分组的列名或其他分组键,出现在结果透视表的列
values = 待聚合的列的名称,默认聚合所有数值列
aggfunc = 值的聚合方式,聚合函数或函数列表,默认为 'mean',可以是任何对 groupby 有效的函数
margins = 总计。添加行/列小计和总计,默认为 False
fill_value = 当出现nan值时,用什么填充 dropna = 如果为True,不添加条目都为NA的列
margins_name = 当margins为True时,行/列小计和总计的名称
[例]利用Python的数据透视表分析计算每个地区的销售总额
关键技术:在pandas中透视表操作由pivot_table()函数实现,其中在所有参数中,values、index、columns最为关键,它们分别对应Excel透视表中的值、行、列
a=pd.pivot_table(database,index='sales_region_code',values='ord_qty',aggfunc=np.sum)
a
2 .交叉表
交叉表采用crosstab函数,可是说是透视表的一部分, 是参数aggfunc=count情况下的透视表。crosstab函数 可以按照指定的行和列统计分组频数
函数形式: pd.crosstab(index,columns,values=None,rownames=None,colnames=None,aggfunc=None,margins=False,margins_name:str='All',dropna: bool = True,normalize=False)
参数说明:
index::要在行中分组的值
columns:要在列中分组的值
values:聚合计算的值,需指定aggfunc
aggfunc:聚合函数,如指定,还需指定value,默认是计数
rownames :列名称
colnames : 行名称
margins : 总计行/列
normalize:将所有值除以值的总和进行归一化 ,为True时候显示百分比
dropna : 是否删除缺失值
[例]根据不同地方的销售方式对这段数据进行统计汇总
关键技术:频数统计时,使用交叉表(crosstab)更方便。传入margins=True参数(添加小计/总计),将会添加标签为ALL的行和列
a=pd.crosstab(database.sales_region_code,database.sales_chan_name,margins=True)
a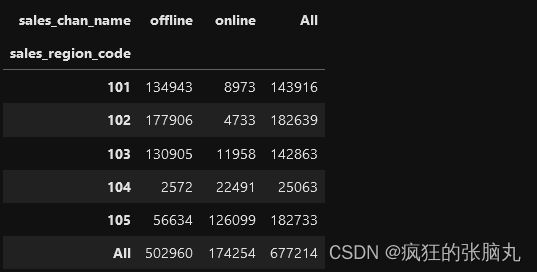
[例] 对sales_region_code和sales_chan_name列同时进行统计汇总
a=pd.crosstab([database.sales_region_code,database.sales_chan_name]
,database.ord_qty,margins=True)
a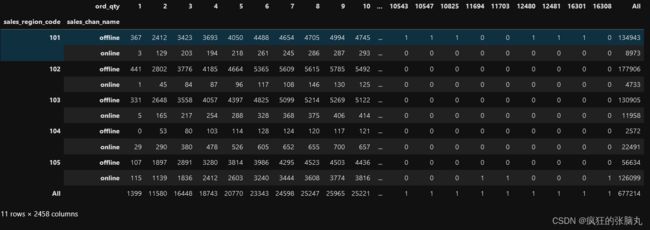
五、数据采样
Pandas中的resample()是一个对常规时间序列数据重新采样和频率转换的便捷的方法,可以对原样本重新处理,
函数语法:
resample(rule,how=None,axis=0,fill_method=None,closed=None,label=None,convention=“start”,kind=None,loffset=None,limit=None,base=0,on=None,level=None)
部分参数含义如下:
rule:表示重采样频率的字符串或DateOffset,比如M、5min等
how:用于产生聚合值的函数名或函数数组,默认为None
fill_method:表示升采样时如何插值,可以取值为fill、bfill或None,默认为None
closed:设置降采样哪一端是闭合的,可以取值为right或left。若设为right,则表示划分为左开右闭的区间;若设为left,则表示划分为左闭右开的区间
label:表示降采样时设置聚合值的标签
convention:重采样日期时,低频转高频采用的约定,可以取值为start或end,默认为start
limit:表示前向或后向填充时,允许填充的最大时期数
[例]数据采集时间为2015/09/1-2019/03/20,默认采集时间以“天”为单位,请利用Python对数据进行以“周”为单位的采样,并计算ord_qty的总和
关键技术:可以通过resample()函数对数据进行采样,并设置参数为'W',表示以“周”为单位的采样。若想以“月”为单位的采样,可以设置参数为'M',若想以“年”为单位的采样,可以设置参数为'Y'
import pandas as pd
database=pd.read_csv('../data/order_train2.csv',
index_col=[0],parse_dates=True)#导入数据
df=database['ord_qty']
df=pd.DataFrame(df)
week=df.resample('M').sum()
week