SEnet实战 -- 垃圾分类
数据集介绍:
有一个文件夹data,下面一个train文件夹,再下面有6个子文件夹,文件夹名称分别是每种垃圾图片的类别,每个类别下面有该类垃圾的图片。
网路结构:
SEnet:resnet18+通道域注意力
采用SEnet网络训练进行分类,加注意力机制后准确率会稍高一些。
SE层结构如下,暂时不讲注意力机制。
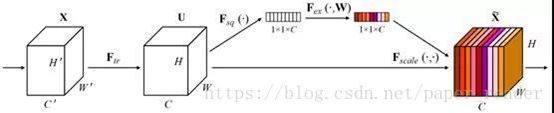
训练过程:
训练集占70%,测试集占30%
数据预处理过程比较简单,只进行了大小的调整,全部缩放到224x224
(还可以增加的常规的数据增强操作,如翻转、裁剪等)
&
类别数字代表含义如下:
0:cardboard
1:glass
2:metal
3:paper
4:plastic
5:trash
网络seresnet代码如下:
import torch.nn as nn
import math
import torch.nn.functional as F
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
if planes == 64:
self.globalAvgPool = nn.AvgPool2d(56, stride=1)
elif planes == 128:
self.globalAvgPool = nn.AvgPool2d(28, stride=1)
elif planes == 256:
self.globalAvgPool = nn.AvgPool2d(14, stride=1)
elif planes == 512:
self.globalAvgPool = nn.AvgPool2d(7, stride=1)
self.fc1 = nn.Linear(in_features=planes, out_features=round(planes / 16))
self.fc2 = nn.Linear(in_features=round(planes / 16), out_features=planes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
original_out = out
out = self.globalAvgPool(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.size(0), out.size(1), 1, 1)
out = out * original_out
out += residual
out = self.relu(out)
return out
class SENet(nn.Module):
def __init__(self, block, layers, num_classes=6):
self.inplanes = 64
super(SENet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
logits = self.fc(x)
probas = F.softmax(logits, dim=1)
return logits, probas
训练文件train.py代码如下
import torchvision
import torch
import torch.nn.functional as F
from torchvision import transforms
from wastesorting.seresnet import SENet
from wastesorting.seresnet import BasicBlock
import os
import shutil
import random
import numpy as np
import matplotlib.pyplot as plt
device = torch.device('cude:0' if torch.cuda.is_available() else 'cpu')
class Classification(object):
def __init__(self, model_name=None, ctx_id=-1):
self.model_name = model_name
self.device = torch.device("cuda:" + str(ctx_id)) if ctx_id > -1 else torch.device("cpu")
self.net = self.load_model()
def load_model(self):
net = SENet(BasicBlock, [2, 2, 2, 2])
if self.model_name is not None:
net.load_state_dict(torch.load(self.model_name, map_location=None if torch.cuda.is_available() else 'cpu'))
if torch.cuda.is_available():
net.to(self.device)
net.eval()
return net
def train(self, dataset=None, batch_size=20, lr=0.05, num_epochs=20):
train_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
optimizer = torch.optim.SGD(self.net.parameters(), lr=lr)
loss_list = []
train_acc = []
test_acc = []
for epoch in range(0, num_epochs):
self.net.train()
train_loss = 0
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = self.net.forward(features)
loss = F.cross_entropy(logits, targets)
train_loss += loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch: %03d/%03d | Batch %04d/%04d | Loss: %.4f'
% (epoch + 1, num_epochs, batch_idx, len(train_loader), loss))
tr_acc = self.compute_accuracy(train_loader)
te_acc = self.compute_accuracy(test_loader)
print('Epoch: %03d/%03d training accuracy: %.2f%% testing accuracy: %.2f%%' % (
epoch + 1, num_epochs, tr_acc, te_acc))
loss_list.append(train_loss / len(train_loader))
train_acc.append(tr_acc)
test_acc.append(te_acc)
if epoch > 15:
torch.save(self.net.state_dict(), './model' + str(epoch) + '.pth')
l = len(loss_list)
x = np.arange(0, l)
plt.figure(figsize=(12, 6))
ax1 = plt.subplot(121)
plt.plot(x, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('loss function curve')
ax2 = plt.subplot(122)
plt.plot(x, train_acc, color='r')
plt.plot(x, test_acc, color='g')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train_acc', 'test_acc'], loc=4)
plt.title('accuracy curve')
plt.savefig("loss_acc.jpg")
def compute_accuracy(self, data_loader):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = self.net.forward(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float() / num_examples * 100
def predict(self, image, transform):
image_tensor = transform(image).float()
image_tensor = image_tensor.unsqueeze_(0)
image_tensor = image_tensor.to(device)
_, output = self.net(image_tensor)
_, index = torch.max(output.data, 1)
return index
if __name__ == '__main__':
# 准备数据
def train_test_split(img_src_dir, img_to_dir, rate=0.3):
path_dir = os.listdir(img_src_dir) # 取图片的原始路径
file_number = len(path_dir)
pick_number = int(file_number * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(path_dir, pick_number) # 随机选取picknumber数量的样本图片
for name in sample:
shutil.move(os.path.join(img_src_dir, name), os.path.join(img_to_dir, name))
return
src_dir = './data/train'
to_dir = './data/test'
if os.path.isdir('./data/test') == False:
# 添加test文件夹
os.mkdir('./data/' + 'test')
for dir in os.listdir(src_dir):
os.mkdir('./data/test/' + dir)
num = len(os.listdir(os.path.join(to_dir, 'paper')))
if num == 0:
# 查看图片数量 并分开训练集测试集
for file in os.listdir(src_dir):
file_dir = os.path.join(src_dir, file)
image = os.listdir(file_dir)
print(file, '图片总量', len(image))
train_test_split(os.path.join(src_dir, file), os.path.join(to_dir, file))
train_dataset = torchvision.datasets.ImageFolder(root=src_dir,
transform=transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor()]))
test_dataset = torchvision.datasets.ImageFolder(root=to_dir,
transform=transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor()]))
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=30, shuffle=True)
print(train_dataset.classes)
print(test_dataset.classes)
# print(dataset.class_to_idx)
# print(dataset.imgs)
cls = Classification()
cls.train(train_dataset)
测试文件test.py代码如下:
from torchvision import transforms
from wastesorting.train import Classification
from PIL import Image
clspre = Classification(model_name='./wastesorting/model18.pth')
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
# 测试图片
img = Image.open('./wastesorting/data/test/paper/paper20.jpg')
clspre.predict(img, transform)
# {'cardboard': 0, 'glass': 1, 'metal': 2, 'paper': 3, 'plastic': 4, 'trash': 5}