2023年第四届MathorCup高校数学建模挑战赛——大数据竞赛B题解题思路
比赛时长为期7天的妈杯大数据挑战赛如期开赛,为了帮助对B题有更深的理解,这里为大家带来B题的初步解题思路。
赛道B:电商零售商家需求预测及库存优化问题
由于妈杯竞赛分为初赛复赛,因此,对于B题大家仅仅看到了预测相关的问题,没有优化相关的问题。包括题干中所说的库存优化,对于本次比赛而言完全没有必要看了。这也大大降低了本次的比赛的难度。下面对本次比赛的B题进行详细的解题思路分析。

数据!!!!(数据清洗+数据可视化)
切记,数据问题,第一步绝对不是做题,而是数据预处理。对于这个题目,如此庞大的数据集一定是存在异常值的,甚至于还有缺失值。因此,基于七天的比赛时长,大家完全可以拿出一两天的,专门找异常值。
这里对于数据,我提供来两种思路,也是课程中一直强调的两种方向,一,对于边缘值问题。二,逻辑异常。边缘值,主要就是对于给出的数据中需求量,存在很大的数值以及0的情况,对于这俩种极端值应该如何处理?我的初步想法就是对于这两个极大值,进行讨论,对于结果予以删除。然后利用线性插值进行填充处理。
对于数值0的情况,分析数据可以大致看出存在很多这样的极小值,进行必要的文字说明。说明这种数据是虽然是异常数据,但是符合实际情况,即可。
对于逻辑异常,例如,一个电脑、办公的商家售卖了宠物 。毫无疑问,这也是属于异常数据了,需要进行处理。但是,这种逻辑异常的难点在于无法直接看出具体是,需要大家仔细查找,或者设置find函数的约束,进行查找,较为复杂。
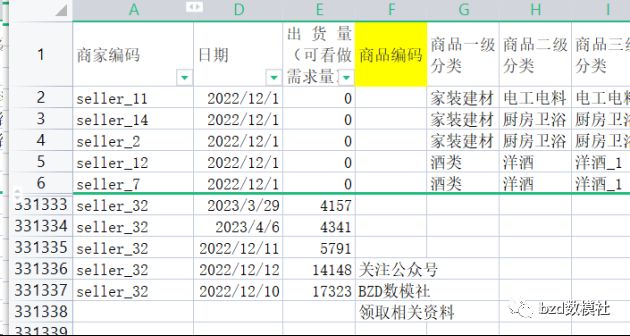
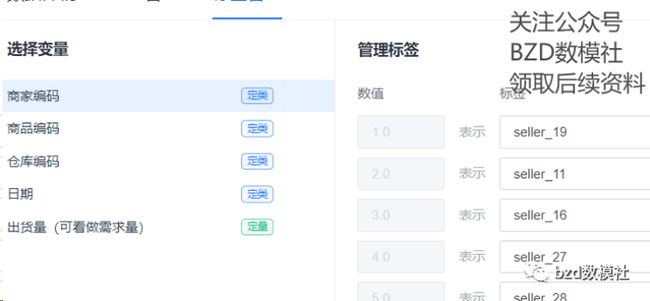
对于数据预处理的数据清洗大致就这些。还有一部分为数据编码处理,即对于商家编码为例,我们需要对这些变为数据进行后续处理,这里就需要大家设置数据标码方式,通常默认的方式,就是依次进行标码,如下所示。大家这里可以使用SPSSPRO快速生成。稍后视频也会有解释说明的
问题初步思路
数据处理差不多后,才是问题的求解。下面带来问题一二三的初步思路
对于问题一,使用附件 1-4 中的数据, 预测出各商家在各仓库的商品2023-05-16 至 2023-05-30 的需求量并对你们模型的预测性能进行评价。
根据数据分析及建模过程,这些由商家、仓库、商品形成的时间序列如何分类,使同一类别在需求上的特征最为相似?
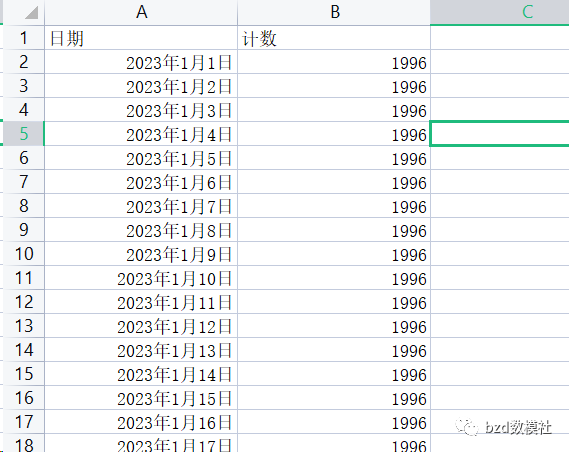
问题一可以理解为两问,也可以按着一种方式进行求解。问题一要求我们进行预测,并对于由商家、仓库、商品形成的时间序列如何进行分类。通过分析数据大家可以看出每天都是1996种商品组合的需求量。对于1996种,不同的组合我们不可能对于每一种都进行预测,即建立的预测模型需要for循环1996,这样的安排即使七天的时间代码也很难跑完。因此,我们必须根据一些相似的特征进行分类,将同一类的组合进行,使同一类别在需求上的特征最为相似。根据不同的类别进行预测。这样可以大大降低预测的工作量。
我认为可以使用关联分析模型,这一模型在课程第五课时有过讲解,大家可以选择直接免费版课程、或者进阶版课程亦或者在网上自行学习都是可以的。这里,我的建议就是可以直接使用person相关性分析,选择和需求量相关系数进行分类,进行分类建模。(注:也可以选择高级的分类模型,再给大家的资料中也有很多的分类判别法的高级方法,大家可以使用那些高级方法进行分类)

选择合适的指标后,即可对商家编码、商品编码、仓库编码、日期、出货量(可看做需求量)进行,这里在预测之前必须记性一定的机理分析。众所周知,对于要得出结果的这四个数据并不是独立的,而知相互之间存在一定联系的。因此,可以对这四个指标进行相关性分析,得出具体的函数表达式后,在进行预测即可。
对于机理的分析,可以通过绘制散点图,相关性分析,线性或者分线性拟合
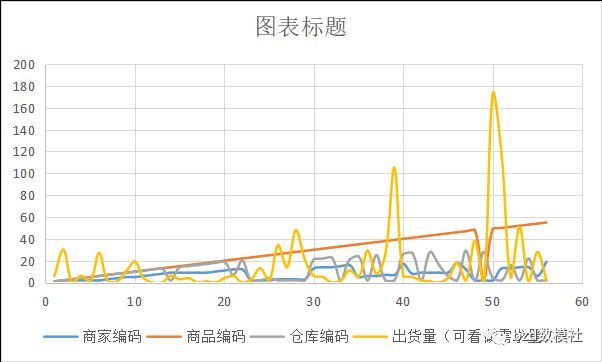
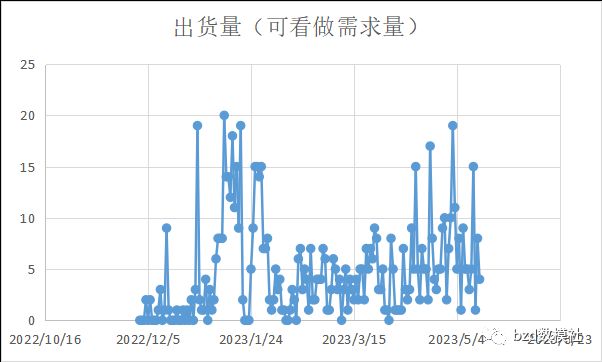
通过绘制这样的图形进行分析机理,构造几个预测值之间的关系等式。
对于预测模型的选取,大家可以根据自己掌握能力选择合适的预测模型即可,可以参考下表,
也可以选择,我一直以来最为推荐的基于优化模型的加权预测模型即可。
根据机理分析得出的关系等式进行预测。

问题二,请讨论这些新出现的预测维度如何通过历史附件 1 中的数据进行参考,找
到相似序列并完成这些维度在 2023-05-16 至 2023-05-30 的预测值。请把预测结果填写在结果表 2,并上传至竞赛平台。
利用问题一建立的分类模型,引入问题二附件五的数据进行重新分类判定,采用尽量采用问题一相同的预测模型,进行预测即可。
问题三:每年 6 月会出现规律性的大型促销,为需求量的精准预测以及履约带来了很大的挑战。附件 6 给出了附件 1 对应的商家+仓库+商品维度在去年双十一期间的需求量数据,请参考这些数据,给出 2023-06-01 至2023-06-20 的预测值。请把预测结果填写在结果表 3,并上传至竞赛平台。
引入,大型促销下的商家+仓库+商品维度相关数据,与问题二思路相似,根据引入的数据利用分类模型,得出新的分类结果。对于这一新的分类结果,采用与问题一相同的预测模型即可。