Prometheus+Grafana+NodeExporter:构建出色的Linux监控解决方案,让你的运维更轻松
《Prometheus+Grafana+NodeExporter:构建出色的Linux监控解决方案,让你的运维更轻松》
一、概述
本文使用Prometheus+Grafana+Node Exporter搭建Linux主机监控系统:
- Prometheus 是一个监控系统,可以收集和存储来自各个目标的指标数据。它支持多种数据源,包括 Node Exporter。

- Grafana 是一个可视化工具,可以用于可视化 Prometheus 收集到的指标数据。它提供了多种仪表盘和图表类型,可以帮助您快速了解监控数据。

- Node Exporter是一个进程,可以收集 Linux 主机的各种指标数据,并将其暴露为 Prometheus 可以抓取的 HTTP 端点。
二、安装
环境准备
以下是本文所需的环境:
- 一台运行 Linux 的服务器(建议使用 CentOS 或 Ubuntu)
- Docker
- Prometheus 和 Grafana
- Node Exporter
1、安装prometheus
这里我们可以在github上获取最新的版本:https://github.com/prometheus/prometheus
vim prometheus.yml# my global config
global:
scrape_interval: 15s # 采集被监控段指标的一个周期
evaluation_interval: 15s # 告警评估的一个周期
# 告警的配置文件
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 告警规则配置
rule_files:
# - "first_rules.yml"
# 被监控端的配置,目前只有一个节点,就是prometheus本身
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']docker run -d -p 9090:9090 \
--name prometheus \
--restart on-failure \
-v /data/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus完全启动后可以,访问Prometheus自带的UI:http://xx.xx.xx.xx:9090/,打开以下页面说明安装成功。

2、安装grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana执行后,下载镜像并启动。完成启动完成,打开http://xx.xx.xx.xx:3000,默认用户名/密码:admin/admin

3、安装node_exporter
cd /usr/local/src/
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar -xvf node_exporter-1.6.1.linux-amd64.tar.gz
mv /usr/local/src/node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin
vim /usr/lib/systemd/system/node_exporter.servicenode_exporter.service文件内容:
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
ExecStart=/usr/local/bin/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
systemctl enable node_exporter
systemctl restart node_exporter启动后打开这个地址:http://xx.xx.xx.xx:9100/


以上页面能打开说明安装成功。
如果安装失败可以使用:
systemctl status node_exporter看看有什么异常。
4、配置prometheus
# 启动后,配置prometheus.yml
vim /data/prometheus/prometheus.yml
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['xx.xx.xx.xx:9090']
# 新增,采集node_exporter监控数据
- job_name: "Linux-Metrics"
static_configs:
- targets: ['xx.xx.xx.xx:9100']
# 重新启动prometheus
systemctl restart prometheus 三、使用
http://xx.xx.xx.xx:3000,默认用户名/密码:admin/admin

选择 "Add your first data source"

进入后选择Prometheus

填写相关信息

添加Prometheus模板

输入id号,9276
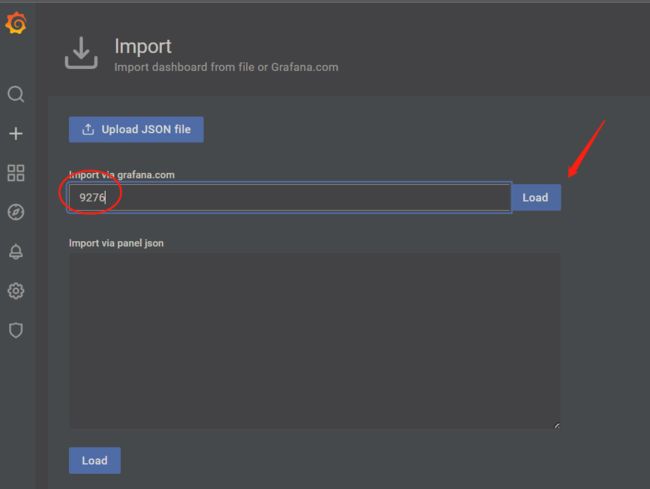
然后下拉,选择Prometheus,然后Import

成功展示来由Prometheus数据

至此整个Linux主机监控就完成了。
四、补充
1、Dashboard模板
如果不知道使用什么模板可以找个教程使用教程里的就好,如果想进一步了解下模板可以去官网这里搜索相应的模板。Dashboards | Grafana Labs ,里面可以输入关键词搜索,还有相应的下载量排名或评分排名。
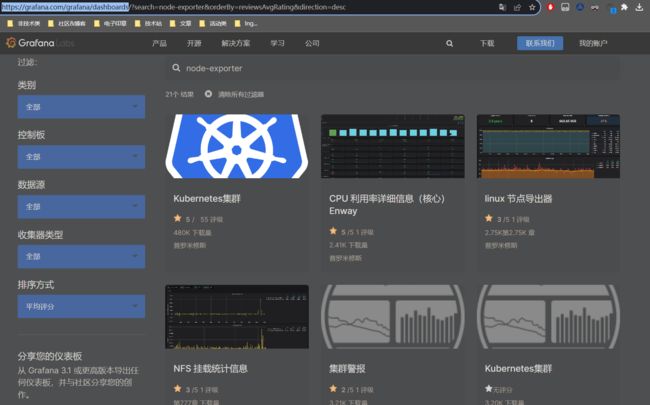
选择一个,点击进入详情页面,可以复制ID

2、数据对照

可以看到有些数据与top是一致的,有的不一致。主要是计算的方式不一致,可以选择一个统计图,点击标题

Edit进入详情。

比如已用内存它是根据这个计算公式算出来的。这样再对照着top的数据就是一致的了。
3、自定义模板
上面说到可以Edit进入dashboard详情,可以看到这么多的表达式。如果我们想调整这里的数据或过滤条件就可以编辑这些参数了。
当然从Edit进入的是单个统计模块,也可以从这里进入整个dashboard模板。修改这里的json


再来说一下这个表达式,这个表达式也就是PromQL 语言。
Grafana Dashboard 中的表达式是 PromQL 语言,它是 Prometheus 的指标查询语言。PromQL 是一种基于 Prometheus 数据模型的查询语言,可以用于查询和过滤 Prometheus 的指标数据。
PromQL 表达式可以用于以下目的:
- 查询指标数据
- 过滤指标数据
- 计算指标数据
- 对指标数据进行聚合
PromQL 表达式使用以下语法:
[指标名] [操作符] [值]例如,以下表达式将查询 CPU 使用率的指标数据:
cpu_usage以下表达式将查询 CPU 使用率的指标数据,并将其限制为 100%:
cpu_usage < 100以下表达式将计算 CPU 使用率的指标数据的平均值:
avg(cpu_usage)以下表达式将将 CPU 使用率的指标数据按主机聚合:
by(host) cpu_usagePromQL 语言具有丰富的功能,可以满足各种监控需求。
以下是一些常用的 PromQL 表达式:
- 查询指标数据
cpu_usage- 过滤指标数据
cpu_usage < 100- 计算指标数据
avg(cpu_usage)- 对指标数据进行聚合
by(host) cpu_usage如何简单调试PromQL,可以打开prometheus自带的web ui进入调试
