C++快餐——C++11(1)

文章目录
- 背景简介
- 统一列表初始化
-
- {}初始化
- initializer_lists初始化
- 关键字
-
- auto
- decltype
- nullptr
- 范围for
- 右值引用和移动语义
-
- 左值和右值
- 左值引用和右值引用
- 完美转发
- 默认成员函数
- 总结
背景简介
C++11,也被称为C++0x(在它被正式标准化之前的名字),C++11是C++标准的一个里程碑,引入了许多重要的语言特性和库,以适应当时的编程需求和技术发展。在C++98标准发布后的几年中,计算机硬件和软件技术取得了巨大的进步。多核处理器、内存管理和编程模型的变化,以及对更高效、更安全编程的需求,推动了C++的演进。
并且在C++标准化委员会外部,许多C++扩展和竞争性编程语言的发展都开始威胁到C++的地位。C++11的推出也是对这些竞争的回应,旨在使C++更具吸引力和竞争力。C++11引入了新的并发编程模型,以处理多核处理器的普及。标准库中引入了线程、原子操作、锁和条件变量等机制,以帮助开发人员编写多线程程序。C++11旨在提高代码的安全性,通过引入智能指针、类型安全枚举、初始化列表等功能,可以帮助减少内存泄漏和其他常见错误。C++11新的语言特性,如自动类型推导、范围基础的for循环、lambda表达式等,都提高了C++的表达力,减少了样板代码的编写。
不仅如此,C++11还引入了许多新的标准库组件,如std::thread、std::regex、std::array,以及对已有库的改进,如std::vector的移动语义。C++11是经过国际标准化组织ISO/IEC的正式认可的,这意味着它是一个全球范围内接受的标准,而不仅仅是一个特定厂商或社群的扩展。
总的来说,C++11的背景在于应对新的编程挑战、提高C++的现代性和竞争力,并为开发人员提供更多的工具来编写高效、安全的代码。它为C++语言带来了重大的改进,使其适应了当时和未来的编程需求。
统一列表初始化
{}初始化
C++11引入了统一的列表初始化语法,它允许你使用花括号 {} 来初始化各种类型的对象,包括数组、标准容器、结构体和类的成员变量等。这个特性有助于统一初始化语法,使代码更加清晰和一致,使用初始化列表时,可添加等号,也可不添加。
//初始化数组:
int arr[] = {1, 2, 3, 4, 5};
//初始化标准容器(例如std::vector)
std::vector<int> vec = {1, 2, 3, 4, 5};
//初始化结构体
struct Point {
int x;
int y;
};
Point p = {10, 20};
//初始化类的成员变量
class MyClass {
public:
int x;
double y;
};
MyClass obj = {42, 3.14};
//初始化嵌套容器
std::vector<std::vector<int>> matrix = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
initializer_lists初始化
std::initializer_list 是 C++11 引入的一个特性,它允许你以列表的形式传递一组值给函数或类的构造函数。这个特性通常用于自定义容器类或其他需要处理初始化的场景。如下一个简单的示例,示例中,printValues 函数接受一个 std::initializer_list 类型的参数,该参数可以接受一个整数列表,并将列表中的值打印出来。
#include 
关键字
auto
auto 是 C++11 引入的关键字,它的主要作用是用于自动类型推断。auto 允许你声明一个变量而无需明确指定其类型,而是让编译器根据初始化表达式来推断类型。这可以减少代码中的重复类型声明,使代码更加简洁。例如:
auto x = 42; // x 的类型将自动推断为 int
auto y = 3.14; // y 的类型将自动推断为 double
auto z = "Hello, World!"; // z 的类型将自动推断为 const char*
auto 也可以与 const 结合使用,以创建只读变量,在这种情况下,auto 推断的类型将是常量类型。例如:
const auto pi = 3.14159; // pi 的类型将自动推断为 const double
auto 还可以与引用结合使用时,可以保留引用性质,从而避免复制对象。在循环中与容器的迭代器一起使用,简化代码。在 Lambda 表达式中用于参数列表,允许你不需要指定参数的类型,而是由编译器自动推断。
int x = 42;
auto& ref_x = x; // ref_x 的类型将自动推断为 int&
std::vector<int> numbers = {1, 2, 3, 4, 5};
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
auto add = [](auto a, auto b) { return a + b; };
int result = add(10, 20); // a 和 b 的类型将根据参数类型自动推断
decltype
decltype 用于获取表达式或变量的类型。它的主要作用是在编译时获取表达式的类型,而不执行实际的表达式,这对于泛型编程和编写模板代码非常有用。decltype 允许你声明一个变量并使用一个表达式,而该变量的类型将根据该表达式的类型来自动推断。这在需要动态确定变量类型的情况下非常有用。例如
int x = 42;
decltype(x) y = x; // y 的类型将自动推断为 int
int getValue() { return 42; }
decltype(getValue()) result; // result 的类型将自动推断为 int,但不会调用 getValue()
decltype 与引用结合使用时,会保留表达式的引用性质。也可以用于嵌套表达式,以获取复杂表达式的类型。
int x = 42;
int& ref_x = x;
decltype(ref_x) y = x; // y 的类型将自动推断为 int&
int x = 42;
decltype(x + 3.14) y; // y 的类型将自动推断为 double
当然它的最大用处还是在泛型编程中,可以用于定义泛型模板函数或类,以处理各种数据类型。
template <typename T, typename U>
auto add(T a, U b) -> decltype(a + b)
{
return a + b;
}
总之,decltype 是一个强大的工具,用于在编译时获得表达式或变量的准确类型信息,特别适用于泛型编程、模板元编程和元编程中,以提高代码的灵活性和可维护性。
nullptr
nullptr 是 C++11 引入的关键字,用于表示空指针。它是为了解决在 C++98 中使用 NULL 或 0 时可能导致的二义性和类型不匹配问题而引入的。在 C++11 之前,通常使用 NULL 或 0 表示空指针,但这会引发一些问题,因为它们实际上是整数值,可能导致类型不匹配或二义性。而nullptr 是一个特定的空指针常量,没有特定的类型,因此可以用于任何指针类型。也因为它没有特定的类型,不能隐式地转换为其他指针类型,从而减少了类型错误的风险。并且nullptr 在函数重载时非常有用,因为它可以明确表示空指针,而不会与整数重载发生二义性。但是在 C++98 中,使用 0 或 NULL 可能会导致二义性,因为它们是整数值。
总之,nullptr 是一项有助于提高类型安全、减少二义性和更好表示空指针的 C++11 特性。在现代 C++ 编程中,推荐使用 nullptr 来表示空指针,而不是使用 NULL 或 0。
范围for
C++中的范围for循环是一种语法糖,用于遍历容器(如数组、向量、列表等)中的元素或者其他支持迭代器的数据结构。它提供了一种简洁的方式来遍历容器,无需手动管理迭代器或索引。范围for的语法形式如下:
for (element_declaration : range_expression) {
// 循环体
}
其中,element_declaration是用于声明循环变量的语句。它定义了一个新的变量,该变量将在每次迭代中代表容器中的当前元素。range_expression是一个表示要遍历的范围的表达式,可以是容器、数组、初始化列表等。并且范围for循环还支持自定义类型的容器,只要该容器提供了迭代器支持。范围for循环的优势在于它简化了遍历容器的过程,并且避免了手动处理迭代器或索引的复杂性。它提供了一种更具可读性和易用性的方式来处理序列中的元素。如下代码:
#include 对于内置数组、标准库容器(如std::vector、std::list、std::set等)以及其他支持迭代器的容器,范围for循环是直接支持的,无需额外的工作。
右值引用和移动语义
左值和右值
在C++中,左值和右值是表达式的两种不同类型。左值是指表达式后得到的持久对象,具有内存地址。左值可以出现在赋值语句的左侧或右侧,并且可以被取址(获取地址)操作符 & 所获取。通常,变量、函数返回的变量、数组元素等都是左值。右值是指表达式后得到的临时对象或将要销毁的对象,它们没有持久的内存地址。右值只能出现在赋值语句的右侧,并且不能被取址操作符 & 所获取。通常,字面量、临时变量、表达式的结果等都是右值。
int x = 10; // x 是左值,具有持久内存地址
int* p = &x; // &x 获取 x 的地址,合法操作
// int* p = &10; // 错误!&10 获取右值 10 的地址,不合法操作
int result = x + y; // x 和 y 都是左值,可以进行加法操作
int result = 5 + 7; // 5 和 7 都是右值,可以进行加法操作
左值引用和右值引用
左值引用和右值引用是C++中的两种引用类型,它们具有不同的绑定规则和语义。左值引用使用单个 & 符号来声明,例如 T&,其中 T 是类型。左值引用只能绑定到左值(具有持久内存地址的对象)。它用于传递参数、进行别名引用和对象修改等场景。左值引用在函数传参中是常见的,允许通过引用修改传递的对象。
右值引用使用双个 && 符号来声明,例如 T&&。右值引用只能绑定到右值(临时对象、将要销毁的对象)。它引入了移动语义和完美转发的概念,允许高效地处理临时对象,并实现资源的转移和移动构造/移动赋值操作。通过右值引用,我们可以区分出临时对象和持久对象,并对它们进行不同的处理。
在C++11之前,大多数操作符和函数接受的参数都是左值。但是C++11引入了右值引用和移动语义,使得右值能够被有效地管理和利用,从而提高代码性能。右值引用的引入使得我们能够区分左值和右值,并对它们进行不同的处理。需要注意的是,有些左值也可以被转换为右值引用,以便进行移动语义的操作。这可以通过使用 std::move 函数来实现。std::move 将左值强制转换为右值引用,用于表示对其的资源转移操作。
无论是左值引用还是右值引用,都是给对象取别名。
void foo(int& x)
{ // 左值引用
std::cout << "foo - lvalue reference: " << x << std::endl;
}
void bar(int&& x)
{ // 右值引用
std::cout << "bar - rvalue reference: " << x << std::endl;
}
int main()
{
int a = 10; // a 是左值
foo(a); // 传递左值给左值引用
int b = 20; // b 是左值
foo(b); // 传递左值给左值引用
//foo(5); // 错误,不能将右值绑定到左值引用
bar(5); // 传递右值给右值引用
//bar(a); // 错误,不能将左值绑定到右值引用
return 0;
}

我们都知道右值是不能取地址的,但是如果将右值用右值引用绑定的话,就可以取地址了,并且还可以对其进行修改,是不是感觉很诧异?如下:
int main() { int&& rvalue = 5; int* ptr = &rvalue; cout << ptr << " : " << *ptr << endl; *ptr = 90; cout << ptr << " : " << *ptr << endl; }
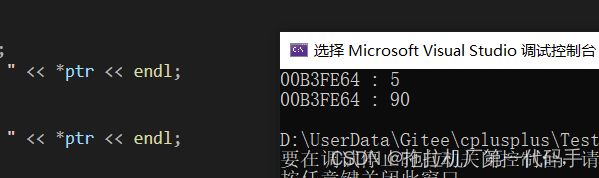
这是因为当我们用右值引用绑定到右值时,它会延长右值的生命周期,使其变得持久。这时,我们可以对右值引用进行取地址操作,并且可以通过该地址修改右值引用所绑定的对象。但是需要注意的是,取地址并修改右值引用所绑定的对象并不是一个常见的用法,因为右值引用通常用于实现移动语义和完美转发。对于临时对象或将要销毁的对象,直接修改其值可能会导致意外的行为。因此,在实际应用中,我们通常会将右值引用用于移动语义和转发操作,而不是对其进行直接的取地址和修改。
左值引用加
const来引用右值也是类似道理。
完美转发
完美转发是一种在函数模板中保持参数类型完整性的技术,它允许将参数按原样转发给另一个函数,包括参数的值类别(左值或右值)和常量性。完美转发通常用于实现泛型函数或类模板中的转发机制,以便将参数传递给其他函数,同时保留原始参数的类型和特性。在 C++ 中,完美转发通常与引用折叠和转发引用相关联。转发引用是一种特殊的引用类型,使用 && 语法声明,可以接受任意值类别的参数。
void func(int&& args)
{
cout << "void func(int&& args)" << endl;
}
void func(int& args)
{
cout << "void func(int& args)" << endl;
}
template <typename T>
void forwardFunction(T&& arg)
{
func(std::forward<T>(arg));
}
int main()
{
int x = 10;
forwardFunction(2); //右值
forwardFunction(x); //左值
return 0;
}
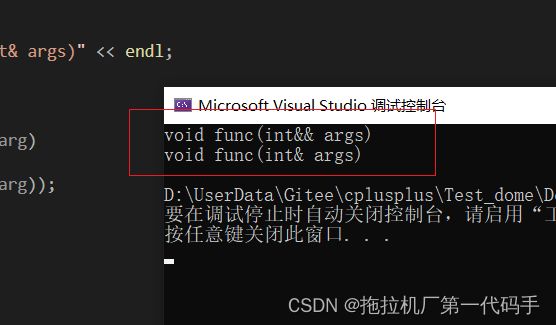
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值,模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是在后续使用中都退化成了左值,使用完美转发就可以在传递过程中保持它的左值或者右值的属性。
默认成员函数
默认成员函数是在 C++ 类中自动生成的成员函数,当用户没有显式定义该成员函数时,编译器会自动生成默认的实现。在C++11之前存在以下几种默认成员函数:
| 函数 | 说明 |
|---|---|
| 默认构造函数 | 如果用户没有提供任何构造函数的定义,编译器会自动生成一个默认构造函数。默认构造函数没有参数,用于创建对象的实例。它执行默认的初始化操作,例如将数据成员初始化为默认值。 |
| 默认析构函数 | 如果用户没有提供析构函数的定义,编译器会自动生成一个默认析构函数。默认析构函数用于销毁对象时进行清理操作,例如释放资源或执行必要的清理动作。 |
| 默认拷贝构造函数 | 如果用户没有提供拷贝构造函数的定义,编译器会自动生成一个默认的拷贝构造函数。默认拷贝构造函数用于创建一个新对象,并将原始对象的值复制到新对象中。 |
| 默认拷贝赋值运算符 | 如果用户没有提供拷贝赋值运算符的定义,编译器会自动生成一个默认的拷贝赋值运算符。默认拷贝赋值运算符用于将一个对象的值赋给另一个对象。 |
取地址重载和
const取地址重载没多大作用就不谈了,有需要请跳转6大默认成员函数。
在C++11 后新增了两个:移动构造函数和移动赋值运算符重载。
| 函数 | 说明 |
|---|---|
| 默认移动构造函数 | 如果用户没有提供移动构造函数的定义,且没有实现析构函数 、拷贝构造和拷贝赋值,编译器会自动生成一个默认移动构造函数。默认移动构造函数用于将右值对象的值转移到新创建的对象中,以实现高效的移动语义。 |
| 默认移动赋值运算符 | 如果用户没有提供移动赋值运算符的定义,且没有实现析构函数 、拷贝构造和拷贝赋值重载,编译器会自动生成一个默认移动赋值运算符。默认移动赋值运算符用于将右值对象的值移动到已存在的对象中,以实现高效的移动语义。 |
默认成员函数的生成规则和行为是由 C++ 标准定义的,编译器会根据需要自动创建这些函数。它们可以在类的声明内部进行声明,或者可以通过使用 = default 或 = delete 进行显式标记和控制。
总结
文章介绍了C++11中新添加的一些常用的特性以及语法,并且重点介绍了右值引用和移动语义。码文不易,如果文章对你有帮助的话就点一个呗,感谢支持!
