大数据基础平台——Spark大数据处理
1.实验目的
了解与掌握数据框的创建、选择、运算和聚合、增加、删除和修改、连接、变形。
2.实验内容及结果截屏
(1)Spark大数据处理
载入本章需要用到的程序包:

(2)数据框的创建
①通过键入创建
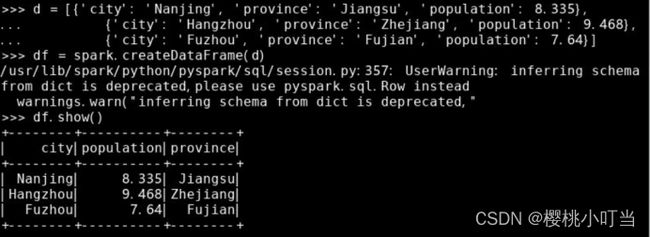
调用spark的函数createDataFrame()创建数据框:
![]()
调用数据框的函数show()查看数据集前几行,默认为前20行:
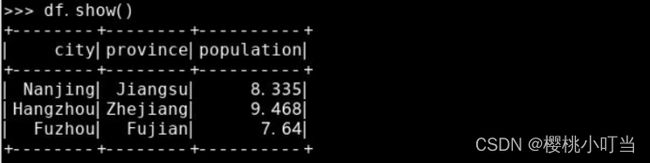
从字典的列表创建数据框,其中字典的键表示数据集的变量名即列名,字典的值表示每行每列的数据值:
从列表的RDD创建数据框:

使用数据框的属性columns和dtypes得到列名和数据类型:

②通过读入数据文件创建
调用spark的函数read()得到从外部存储系统读取数据的接口,进一步级联调用其函数csv()读取CSV文件:
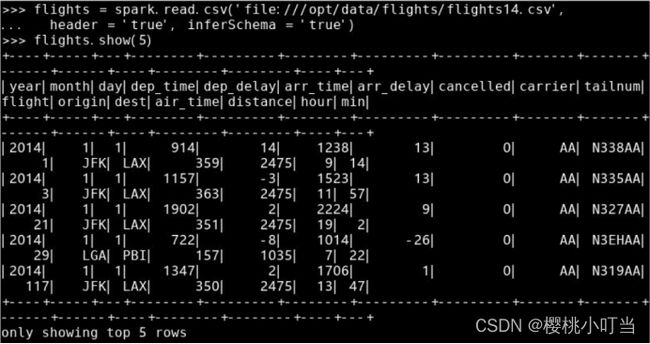
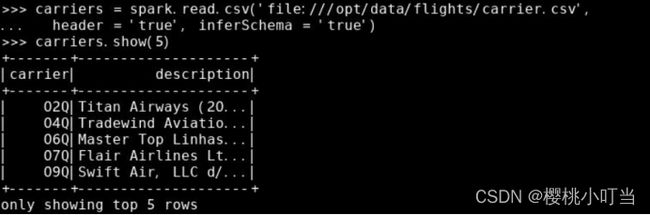
读取航空公司数据集:
(3)数据框的选择
①数据列的选择
调用数据框的函数select()选取指定列:
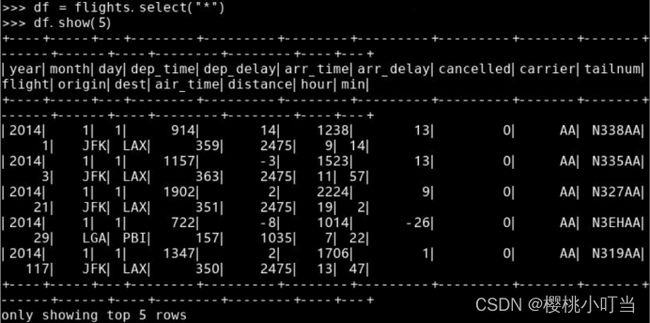
通过列名的字符串选取多列数据:

通过形如<数据框名>.<列名>的Column对象选取多列数据:

②数据列的计算
通过Column对象表达式选取多列数据:
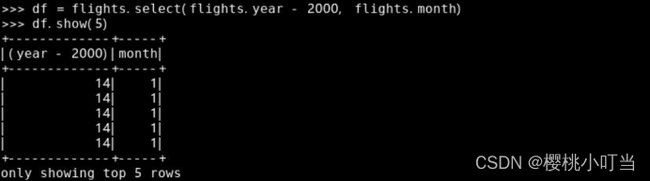
调用Column对象的函数alias()设置列名:

③数据行的选择
通过Column对象的判断表达式选取航班数据集中出发地(变量origin)为'JFK'的数据行:

选取航班数据集中出发地(变量origin)为'JFK'、月份(变量month)为6月的数据行:

筛选条件为SQL表达式字符串:

调用数据框的函数limit()选取数据框的前几行,返回结果还是一个数据框:
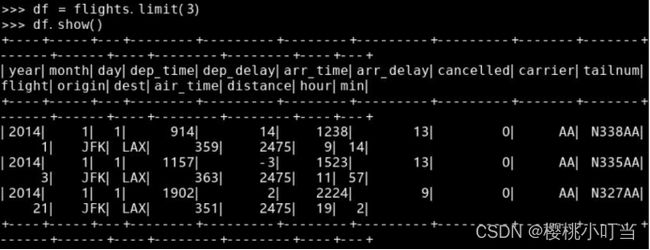
(4)数据框的运算和聚合
①数据框的统计运算
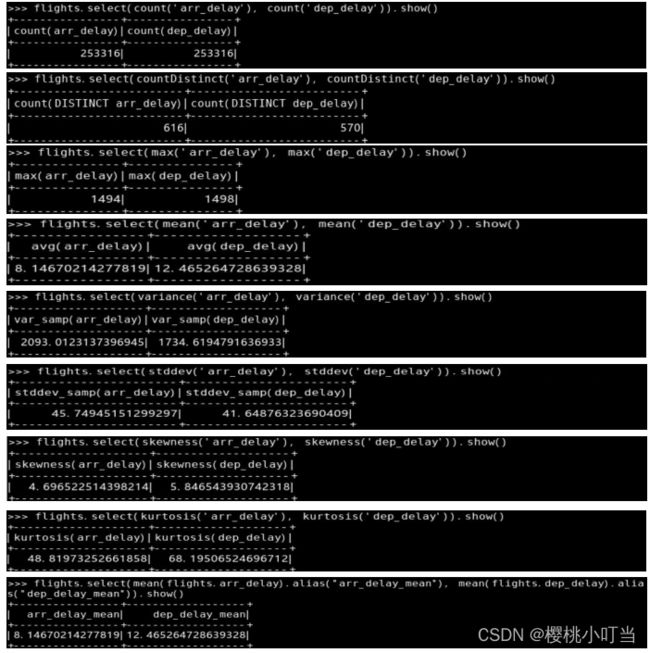
②数据框的聚合
按出发地(变量origin)分组:

调用GroupedData分组对象的函数count()返回包含分组记录数的数据框:

GroupedData分组对象有如下函数实现常用统计功能:

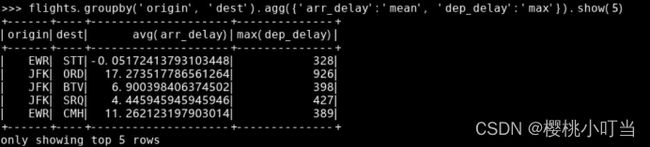
在函数agg()中指定由程序包pyspark.sql.functions中统计函数得到的Column对象列表,计算在各不同出发地和目的地组合中,平均到达和出发延误分钟数(变量arr_delay和dep_delay):

在函数agg()中指定键为变量名、值为聚合函数的字典,即对不同变量执行不同的聚合函数,计算在各不同出发地和目的地组合中,到达延误分钟数(变量arr_delay)的均值和出发延误分钟数(变量dep_delay)的最大值:
(5)数据框的增加、删除和修改
①数据增加
调用数据框的函数withColumn()增加或替换数据列,返回一个新的数据框:
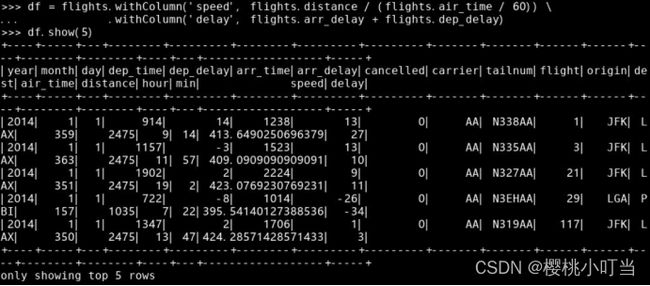
调用数据框的函数unionAll()与另一个数据框按行合并,返回一个新的数据框:

②数据删除
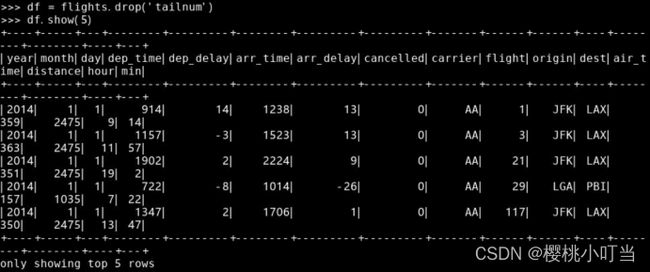
调用数据框的函数drop()删除指定列,返回一个新的数据框。以下例子删除航班数据的变量tailnum:
③数据修改
调用数据框的函数withColumn()增加或替换数据列,返回一个新的数据框:

(6)数据框的连接
①内连接
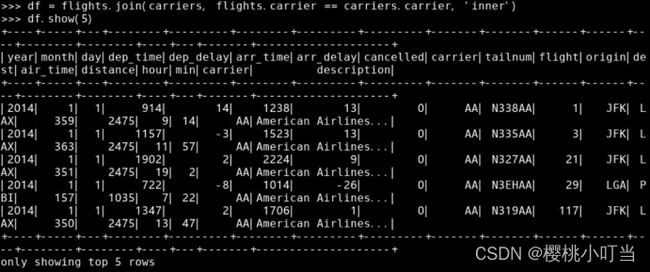
调用数据框的函数join()并指定参数how = 'inner'做内连接、参数on为连接变量名:

计算内连接前航班数据集的记录条数和连接后的记录条数:

指定参数on为连接条件做内连接,与之前得到的结果完全一致,除了连接变量carrier出现了2次:
②左连接
调用数据框的函数join()并指定参数how = 'left_outer'做左连接:
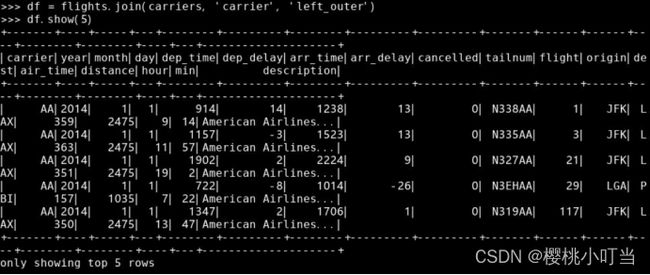
计算左连接前航班数据集的记录条数和连接后的记录条数:

③全链接
调用数据框的函数join()并指定参数how为'outer'做全连接:
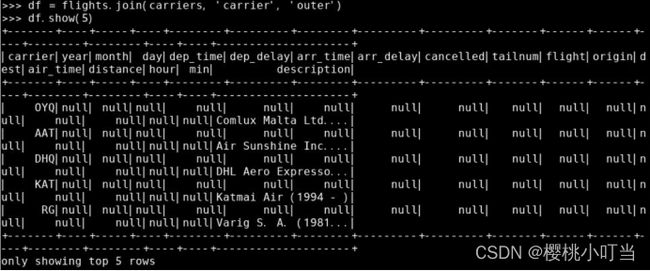
计算全连接前航班数据集的记录条数和连接后的记录条数:

(7)数据框的变形
①从“长”转“宽”
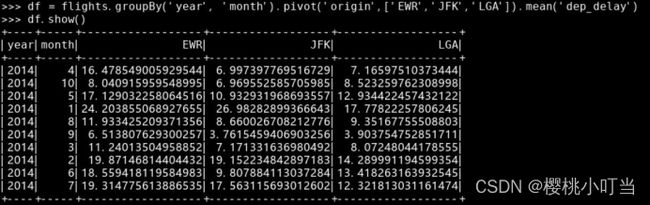
计算在各不同年份、月份和出发地组合中,平均出发延误分钟数(变量dep_delay),其中不同的出发地用不同列表示:
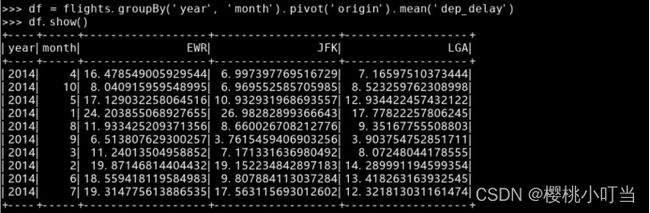
没有指定参数values时,效率较低:
3.实验分析及小结
在此次实验过程中,我了解与掌握数据框的创建、选择、运算和聚合、增加、删除和修改、连接、变形。在实验过程中,我基本没有遇到问题,除了在指定参数values后计算在各不同年份、月份和出发地组合中,平均出发延误分钟数时,遇到了下图中的报错。

我先去除了values参数运行,发现正常运行没有报错,因此确认是values参数中的问题。故怀疑是需要参数类型问题,但仔细检查后,发现是代码从教程中复制到虚拟机后,有三个逗号丢失了,因此将逗号补上,之后便没有报错了。
在之后的实验中,我会更加认真地学习、理解代码,同时尽可能减少粗心导致的错误。