JAVA Future类详解
前言
在高性能编程中,并发编程已经成为了极为重要的一部分。在单核CPU性能已经趋于极限时,我们只能通过多核来进一步提升系统的性能,因此就催生了并发编程。
由于并发编程比串行编程更困难,也更容易出错,因此,我们就更需要借鉴一些前人优秀的,成熟的设计模式,使得我们的设计更加健壮,更加完美。
而Future模式,正是其中使用最为广泛,也是极为重要的一种设计模式。今天就跟阿丙了解一手Future模式!
生活中的Future模式
为了更快的了解Future模式,我们先来看一个生活中的例子。
场景1:
午饭时间到了,同学们要去吃饭了,小王下楼,走了20分钟,来到了肯德基,点餐,排队,吃饭一共花了20分钟,又花了20分钟走回公司继续工作,合计1小时。更多Java进阶学习教程微老师:hua2021ei
场景2
午饭时间到了,同学们要去吃饭了,小王点了个肯德基外卖,很快,它就拿到了一个订单(虽然订单不能当饭吃,但是有了订单,还怕吃不上饭嘛)。接着小王可以继续干活,30分钟后,外卖到了,接着小王花了10分钟吃饭,接着又可以继续工作了,成功的卷到了隔壁的小汪。

很明显,在这2个场景中,小王的工作时间更加紧凑,特别是那些排队的时间都可以让外卖员去干,因此可以更加专注于自己的本职工作。聪明的你应该也已经体会到了,场景1就是典型的函数同步调用,而场景2是典型的异步调用。
而场景2的异步调用,还有一个特点,就是它拥有一个返回值,这个返回值就是我们的订单。这个订单很重要,凭借着这个订单,我们才能够取得当前这个调用所对应的结果。
这里的订单就如同Future模式中的Future,这是一个合约,一份承诺。虽然订单不能吃,但是手握订单,不怕没吃的,虽然Future不是我们想要的结果,但是拿着Future就能在将来得到我们想要的结果。
因此,Future模式很好的解决了那些需要返回值的异步调用。
Future模式中的主要角色
一个典型的Future模式由以下几个部分组成:
- Main:系统启动,调用Client发出请求
- Client:返回Data对象,立即返回FutureData,并开启ClientThread线程装配RealData
- Data:返回数据的接口
- FutureData:Future数据,构造很快,但是是一个虚拟的数据,需要装配RealData,好比一个订单
- RealData:真实数据,其构造是比较慢的,好比上面例子中的肯德基午餐。
它们之间的相互关系如下图:
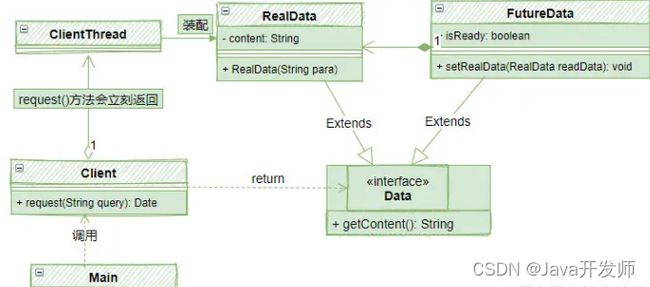
其中,值得注意是Data,RealData和FutureData。这是一组典型的代理模式,Data接口表示对外数据,RealData表示真实的数据,就好比午餐,获得它的成本比较高,需要很多时间;相对的FutureData作为RealData的代理,类似于一个订单/契约,通过FutureData,可以在将来获得RealData。
因此,Future模式本质上是代理模式的一种实际应用。
实现一个简单的Future模式
根据上面的设计,让我们来实现一个简单的代理模式吧!
首先是Data接口,代表数据:
public interface Data {
public String getResult ();
}
复制代码接着是FutureData,也是整个Future模式的核心:
public class FutureData implements Data {
// 内部需要维护RealData
protected RealData realdata = null;
protected boolean isReady = false;
public synchronized void setRealData(RealData realdata) {
if (isReady) {
return;
}
this.realdata = realdata;
isReady = true;
//RealData已经被注入,通知getResult()
notifyAll();
}
//会等待RealData构造完成
public synchronized String getResult() {
while (!isReady) {
try {
//一直等待,直到RealData被注入
wait();
} catch (InterruptedException e) {
}
}
//真正需要的数据从RealData获取
return realdata.result;
}
}
复制代码下面是RealData:
public class RealData implements Data {
protected final String result;
public RealData(String para) {
StringBuffer sb=new StringBuffer();
//假设这里很慢很慢,构造RealData不是一个容易的事
result =sb.toString();
}
public String getResult() {
return result;
}
}
复制代码然后从Client得到Data:
public class Client {
//这是一个异步方法,返回的Data接口是一个Future
public Data request(final String queryStr) {
final FutureData future = new FutureData();
new Thread() {
public void run() {
// RealData的构建很慢,所以在单独的线程中进行
RealData realdata = new RealData(queryStr);
//setRealData()的时候会notify()等待在这个future上的对象
future.setRealData(realdata);
}
}.start();
// FutureData会被立即返回,不会等待RealData被构造完
return future;
}
}
复制代码最后一个Main函数,把所有一切都串起来:
public static void main(String[] args) {
Client client = new Client();
//这里会立即返回,因为得到的是FutureData而不是RealData
Data data = client.request("name");
System.out.println("请求完毕");
try {
//这里可以用一个sleep代替了对其他业务逻辑的处理
//在处理这些业务逻辑的过程中,RealData被创建,从而充分利用了等待时间
Thread.sleep(2000);
} catch (InterruptedException e) {
}
//使用真实的数据,如果到这里数据还没有准备好,getResult()会等待数据准备完,再返回
System.out.println("数据 = " + data.getResult());
}
复制代码这是一个最简单的Future模式的实现,虽然简单,但是已经包含了Future模式中最精髓的部分。对大家理解JDK内部的Future对象,有着非常重要的作用。
Java中的Future模式
Future模式是如此常用,在JDK内部已经有了比较全面的实现和支持。下面,让我们一起看看JDK内部的Future实现:

首先,JDK内部有一个Future接口,这就是类似前面提到的订单,当然了,作为一个完整的商业化产品,这里的Future的功能更加丰富了,除了get()方法来获得真实数据以外,还提供一组辅助方法,比如:
- cancel():如果等太久,你可以直接取消这个任务
- isCancelled():任务是不是已经取消了
- isDone():任务是不是已经完成了
- get():有2个get()方法,不带参数的表示无穷等待,或者你可以只等待给定时间
下面代码演示了这个Future的使用方法:
//异步操作 可以用一个线程池
ExecutorService executor = Executors.newFixedThreadPool(1);
//执行FutureTask,相当于上例中的 client.request("name") 发送请求
//在这里开启线程进行RealData的call()执行
Future future = executor.submit(new RealData("name"));
System.out.println("请求完毕,数据准备中");
try {
//这里依然可以做额外的数据操作,这里使用sleep代替其他业务逻辑的处理
Thread.sleep(2000);
} catch (InterruptedException e) {
}
//如果此时call()方法没有执行完成,则依然会等待
System.out.println("数据 = " + future.get());
复制代码 整个使用过程非常简单,下面我们来分析一下executor.submit()里面究竟发生了什么:
public Future submit(Callable task) {
if (task == null) throw new NullPointerException();
// 根据Callable对象,创建一个RunnableFuture,这里其实就是FutureTask
RunnableFuture ftask = newTaskFor(task);
//将ftask推送到线程池
//在新线程中执行的,就是run()方法,在下面的代码中有给出
execute(ftask);
//返回这个Future,将来通过这个Future就可以得到执行的结果
return ftask;
}
protected RunnableFuture newTaskFor(Callable callable) {
return new FutureTask(callable);
}
复制代码 最关键的部分在下面,FutureTask作为一个线程单独执行时,会将结果保存到outcome中,并设置任务的状态,下面是FutureTask的run()方法:

从FutureTask中获得结果的实现如下:
public V get() throws InterruptedException, ExecutionException {
int s = state;
//如果没有完成,就等待,回到用park()方法阻塞线程
//同时,所有等待线程会在FutureTask的waiters字段中排队等待
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private V report(int s) throws ExecutionException {
//outcome里保存的就是最终的计算结果
Object x = outcome;
if (s == NORMAL)
//正常完成,就返回outcome
return (V)x;
//如果没有正常完成, 比如被用户取消了,或者有异常了,就抛出异常
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
复制代码Future模式的高阶版本—— CompletableFuture
Future模式虽然好用,但也有一个问题,那就是将任务提交给线程后,调用线程并不知道这个任务什么时候执行完,如果执行调用get()方法或者isDone()方法判断,可能会进行不必要的等待,那么系统的吞吐量很难提高。
为了解决这个问题,JDK对Future模式又进行了加强,创建了一个CompletableFuture,它可以理解为Future模式的升级版本,它最大的作用是提供了一个回调机制,可以在任务完成后,自动回调一些后续的处理,这样,整个程序可以把“结果等待”完全给移除了。
下面来看一个简单的例子:

在这个例子中,首先以getPrice()为基础创建一个异步调用,接着,使用thenAccept()方法,设置了一个后续的操作,也就是当getPrice()执行完成后的后续处理。
不难看到,CompletableFuture比一般的Future更具有实用性,因为它可以在Future执行成功后,自动回调进行下一步的操作,因此整个程序不会有任何阻塞的地方(也就是说你不用去到处等待Future的执行,而是让Future执行成功后,自动来告诉你)。
以上面的代码为例,CompletableFuture之所有会有那么神奇的功能,完全得益于AsyncSupply类(由上述代码中的supplyAsync()方法创建)。
AsyncSupply在执行时,如下所示:
public void run() {
CompletableFuture d; Supplier f;
if ((d = dep) != null && (f = fn) != null) {
dep = null; fn = null;
if (d.result == null) {
try {
//这里就是你要执行的异步方法
//结果会被保存下来,放到d.result字段中
d.completeValue(f.get());
} catch (Throwable ex) {
d.completeThrowable(ex);
}
}
//执行成功了,进行后续处理,在这个后续处理中,就会调用thenAccept()中的消费者
//这里就相当于Future完成后的通知
d.postComplete();
}
}
复制代码 继续看d.postComplete(),这里会调用后续一系列操作
final void postComplete() {
//省略部分代码,重点在tryFire()里
//在tryFire()里,真正触发了后续的调用,也就是thenAccept()中的部分
f = (d = h.tryFire(NESTED)) == null ? this : d;
}
}
}
复制代码絮叨
今天,我们主要介绍Future模式,我们从一个最简单的Future模式开始,逐步深入,先后介绍了JDK内部的Future模式实现,以及对Future模式的进化版本CompletableFuture做了简单的介绍。对
于多线程开发而言,Future模式的应用极其广泛,可以说这个模式已经成为了异步开发的基础设施。
好啦如果想了解多线程的更多知识点可以关注我,查看历史文章,我也会持续更新的。