【Airflow】构建爬虫任务系统
爬虫脚本太多了需要进行管理一下,领导决定使用airflow
我了解了一下这个平台是用来做任务调度。
是一个ETL工具
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程
这里是一个github的地址
https://github.com/apache/airflow
这里是官方文档
https://airflow.apache.org/docs/apache-airflow/stable/index.html
这里是我学习的视频资料
https://www.bilibili.com/video/BV19f4y1V7UG/
博主的视频有一些老了,不过也是可以学习的。
先看一下成果吧
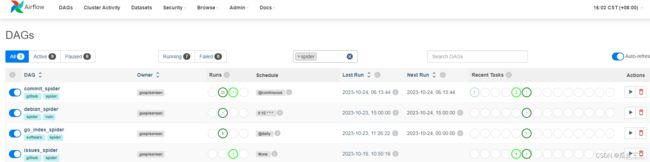
这里是首页记录了,我得dags任务
dags就相当于我得一个爬虫任务,
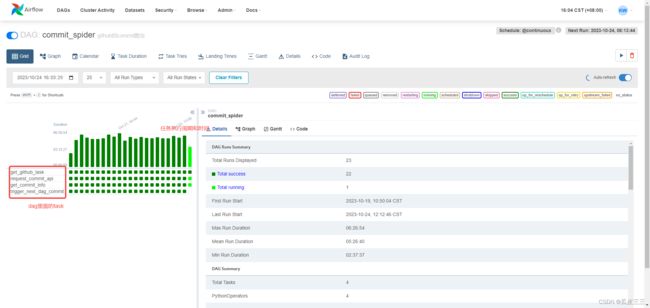
我们进入这个dag里面,可以看到
有4个小任务(task)和一task执行的状态,还有一些基本信息。
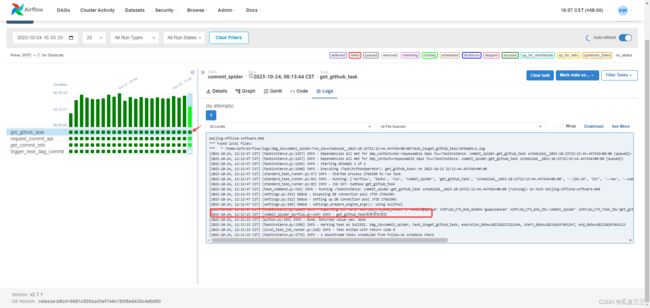
可以看每一个task的日志,如果发生问题也可以更方便的定位问题的。
每个dag都有很多配置,比如定时任务,失败重试,自动拉起,报警邮件等功能。
以后再也不用上服务器去看日志了
嘻嘻嘻嘻嘻
conda环境安装
这里需要一个干净的环境,我使用的miniconda
来到 conda网站
https://docs.conda.io/projects/miniconda/en/latest/miniconda-other-installer-links.html
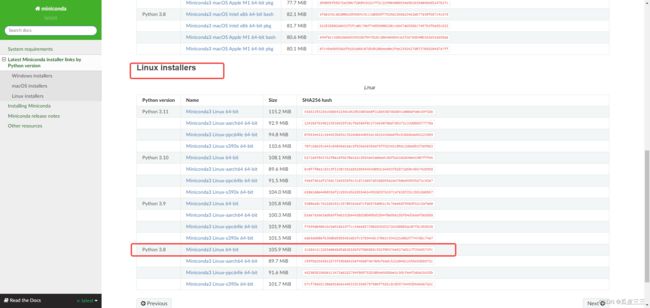
这里选择linux 的 我是用的是python3.8
然后复制这个链接地址。

然后我们到服务器上将这个包下好。
执行命令
wget https://repo.anaconda.com/miniconda/Miniconda3-py38_23.9.0-0-Linux-x86_64.sh

下好之后。
安装好之后,执行
bash Miniconda3-py38_23.9.0-0-Linux-x86_64.sh
然后一直yes 就ok

conda这里就装好了

也带着python。然后我们创建一个环境
conda create -n airflow # 创建环境
conda activate airflow # 激活环境
这样环境就差不多了
安装一下airflow
conda install apache-airflow

这里会依赖很多包
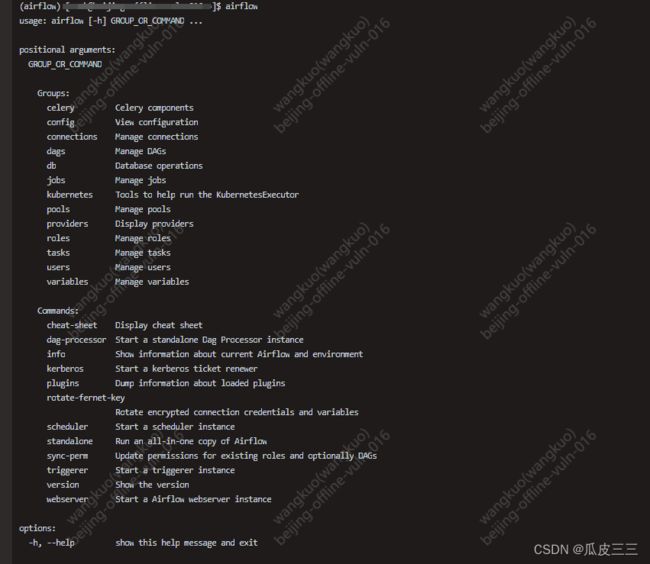
执行airflow命令,出现这些,说明airflow已经装好了。
配置airflow
找到你得airflow路径,
里面会有一个airflow.cfg文件

这里是配置dags的文件路径

这里默认使用的是sqlite数据库,
后续也可以改成mysql
https://blog.csdn.net/qq_43439214/article/details/129898191
这个博主的文章很不错,将airflow的数据库换成了mysql
我这里就先用默认的了,
执行命令
airflow db init
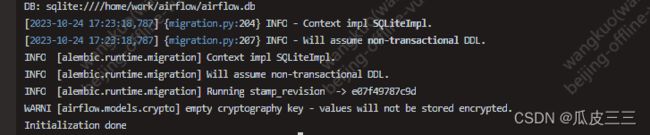
出现下面内容说明数据库已经初始化好了。
执行下面命令进行创建用户
airflow users create --username zhang --firstname zhang --lastname zhang --role Admin --email [email protected]
并为其用户设置密码。
配置好了之后
我们开一个会话

来通过webserver开启 web服务,这里在要访问你得公网地址默认端口是8080
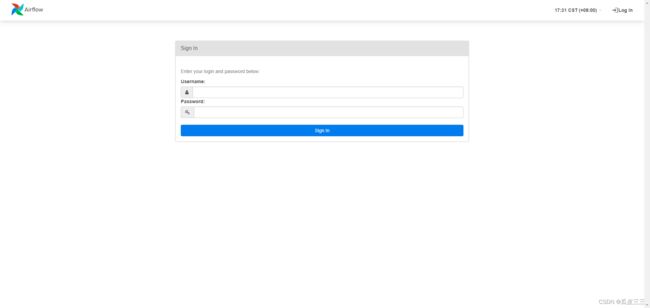
到这里来到了ui界面输入,你刚刚创建的用户名和密码。
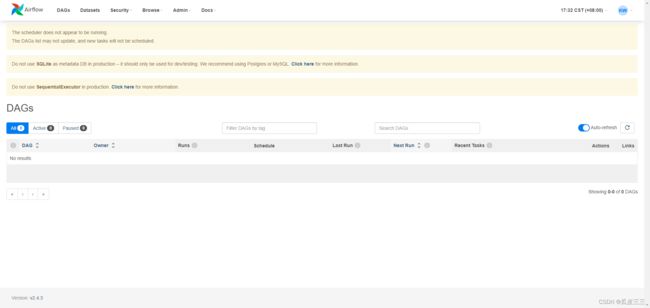
来到这里了。
这样我们的配置基本就没问题了。
举个例子
来举一个例子,
来写一个dags看一下。
from __future__ import annotations
# [START tutorial]
# [START import_module]
import os
import sys
from datetime import datetime, timedelta
from textwrap import dedent
from airflow.operators.python import PythonOperator, BranchPythonOperator
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator
# [END import_module]
# [START instantiate_dag]
def first_task():
print("这里是first_task")
print("这里是first_task")
print("这里是first_task")
print("这里是first_task")
print("这里是first_task")
def second_task():
print("这里是second_task")
print("这里是second_task")
print("这里是second_task")
print("这里是second_task")
print("这里是second_task")
with DAG(
dag_id="test_airflow",
default_args={
'owner': "guapisansan",
"depends_on_past": True,
"email": ["[email protected]"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
},
# [END default_args]
description="测试一把",
schedule_interval='0 15 * * *', # 设置调度间隔为每天下午六点,
catchup=False,
start_date=datetime(2023, 10, 23),
tags=["test"],
) as dag:
first_task_op = PythonOperator(
task_id="first_task",
python_callable=first_task
)
second_task_op = PythonOperator(
task_id="second_task",
python_callable=second_task
)
first_task_op >> second_task_op
我这里给了一段非常简单的代码。
大概意思就是有两个task,分别是first和second 他们对应的也分别是两个python函数
配置了一些参数,如 description dag的简介, 还有一些参数,可以在官方文档查询。
记不记得我们的airflow.cfg文件里面有一个这个参数
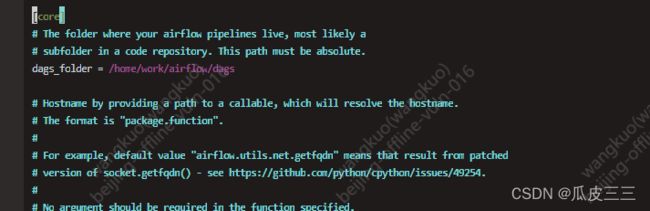
这里就是我们存放所有 dags的路径。一定要是绝对路径
将刚刚写的脚本放到这个路径下,
然后我们在执行命令
airflow dags list

这里存在我刚刚的创建的test_airflow
这时候我们在创建一个会话
执行命令
airflow scheduler
这是一个调度命令
这时候我们刷新刚刚的web页面
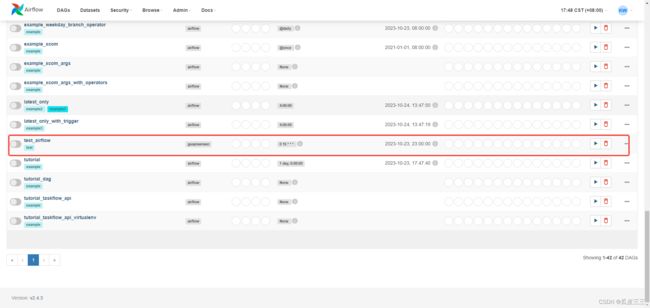
发现我们dags已经挂到ui页面上了
我们点进去看看
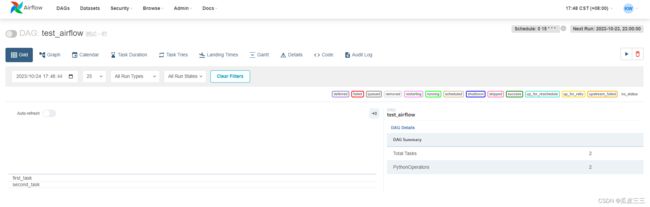
看到了我们的子任务task 出现了,
现在需要手动触发一下看看结果。
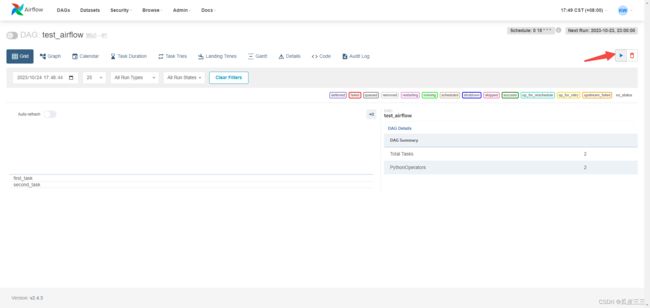
点击这个trigger按钮

可以看到这两个task都执行成功了。
右边的框里面有执行时间,还有一些任务的基础信息,

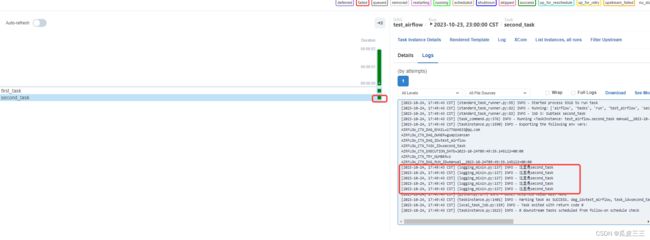
点击小图片查看任务执行的日志,
发现我们print打印出来了,
我这里只是举一个小例子先跑起来,可以根据自己的脚本进行配置等等。
airflow是一个非常好用的任务调度工具,相对于数据处理更好,我们当作爬虫管理系统也可以用。
用它将分散的脚本整理,更加方便观察和调度。