十大经典排序算法(希尔排序、堆排序、计数排序、桶排序和基数排序)
十大排序算法二
- 希尔排序
-
- 希尔排序原理
- 希尔排序代码实现
- 堆排序
-
- 堆排序原理
- 堆排序代码实现
- 计数排序
-
- 计数排序代码实现
- 计数排序的优化
- 桶排序
-
- 桶排序原理
- 桶排序代码实现
- 基数排序
-
- 基数排序原理
- 基数排序代码实现
- 基数排序的应用
十大经典排序算法一(冒泡排序、选择排序、插入排序、快速排序、归并排序)
希尔排序
希尔排序原理
希尔排序是插入排序的一种,他是针对直接插入排序算法的改进,由D.L.Shell于1959年提出而得名。
希尔排序的基本思想是把待排序的数列分为多个组,然后在对每个组进行插入排序,先让数列整体大致有序,然后多次调整分组方式,使的数列更加有序,最后再使用一次插入排序,整个数列将全部有序。
希尔排序代码实现
#include 堆排序
堆排序原理
堆排序是利用堆这种数据结构而设计的一种排序算法,堆具有以下特点:
- 完全二叉树;(
从上到下,从左到右,每一层的结点都是满的,最下一层所有的结点都连续集中在最左边) - 二叉树每个节点的值都大或等于其左右子树结点的值称为大顶堆;或每个结点的值都小于或等于左右子树的值,称为小顶堆;
将完全二叉树按如下方式编号,则该堆可以对应一个数组;且左右结点和父子结点之间有以下对应关系。

堆排序代码实现
#include 计数排序
计数排序算法的时间复杂度降低到O(n+k),但是有两个要满足的前提:
- 需要排序元素必须是整数;
- 排序元素的取值要在一定范围内,并且比较集中,只有满足这两个条件,才可最大程度发挥计数排序优势。
计数排序代码实现
#include 计数排序的优化
可以一次性计算出最大值和最小值,然后计算差值,确定所需辅助数组的大小;
记数排序的缺陷是空间消耗较多,排序的时候可以将数组的大小开为max-min+1;比如高考成绩的排名可以用记数排序
桶排序
桶排序原理
假设输入数据服从均匀分布,将数据分到有限数量的桶里,然后再对每个桶分别排序,最后把全部的桶数据合并。
桶排序的时间复杂度,取决于对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n).很显然,桶划分的越小各个桶之间数据越少,排序所用的时间也会越少,但相应的空间消耗会增大。

重点理解桶排序的思想,在现实世界中,大部分的数据分布是均匀的,或者在设计的时候让他均匀分布,或者转换为均匀分布。既然数据均匀分布了,桶排序的效率就能发挥出来。
理解桶排序的思想可以设计出很高效的算法。(分库分表)
桶排序代码实现
#include 基数排序
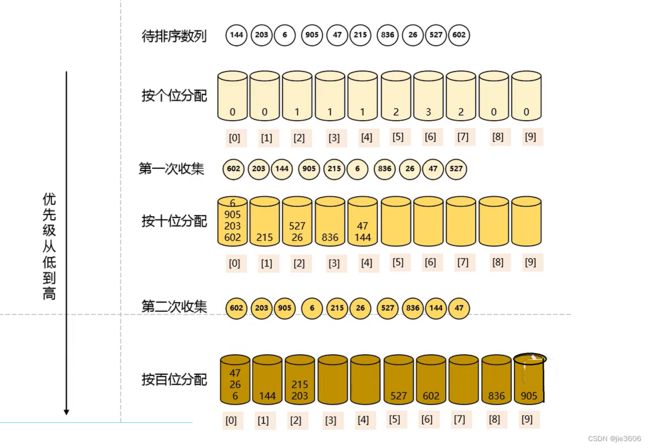
基数排序是桶排序的扩展,他的基本思想是:将整数按位切割成不同的数字,然后按每个位分别比较。
具体做法是:将所有带比较数值统一为同样的数位长度,数位较短的数前面补0.然后,从最底位开始,依次进行排序。这样从最低位排序一直到最高位排序完成后,就变成了一个有序数列。
基数排序原理
基数排序代码实现
#include 基数排序的应用
由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也是用于其它数据类型。
例如:按照出生日期排序,先按照日把数据放到桶中,再按月份,最后按照年放入桶中;