机器学习系列文章(chapter two)——数据特征分析处理
一、数据来源
用机器学习来分析数据、获取客观规律,首先我们要能有海量数据去进行分析,才有可能得出相对准确的结论。如果数据量不够大,则很可能得出误导性的结论。比如去高端住宅区调查人均存款情况,得出的结论就会大大超出真实水平。数据就像是食物,只有保证足够的高质量食物,才让我们的机器学习程序更加强大。常见的数据来源:
- 企业日积月累的大量数据(如淘宝的购买记录)
- 政府掌握的各种数据(如经济产值、货币发行量)
- 科研机构的实验数据(如特斯拉自动驾驶数据)
- …
二、数据类型
- 离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所以这些数据全为整数,且不可再细分,也不能进一步提高精确度。
- 连续型数据:变量可以再某个范围内取任一数,即变量的取值可以是连续的,如长度、时间、质量值等。这类数据是非整数。
可用数据集:
为了方面学习,解决数据不足的问题,python提供了可观且实用的数据集。
| 数据集 | 特点 |
|---|---|
| scikit-learn | 数据量较小,方便学习 |
| UCI | 收录了360个数据集,覆盖各个领域,且有几十万行数据| |
| Kaggle | 大数据竞赛平台、真实数据且数据量巨大,日常使用也最多 |
三、数据的特征工程
(一)常用数据集的结构组成:
结构:特征值+目标值
一行为一个完整数据,一列为一个特征,如:

(二)特征工程是什么
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,提高了对模型预测的准确性。特征工程直接影响模型的预测结果。
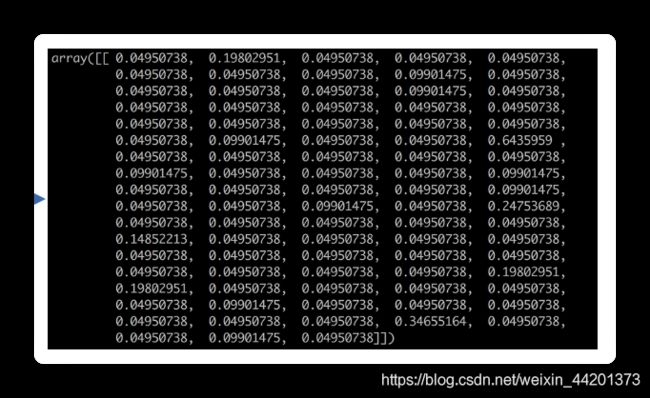
比如,一段文字:

在特征工程中先将文字转化为数组再进行学习,可以降低学习难度和提升学习的精度:
(三)相关库的安装
日常学习用的比较多的是scikit-learn这个库,其他的数据集库在后面的帖子中会进一步解析。
pip install Scikit-learn
#安装好库之后再导入
import sklearn
# 查看sklearn的版本
print(sklearn.__version__)
四、特征抽取
特征抽取需要用到的api如下:
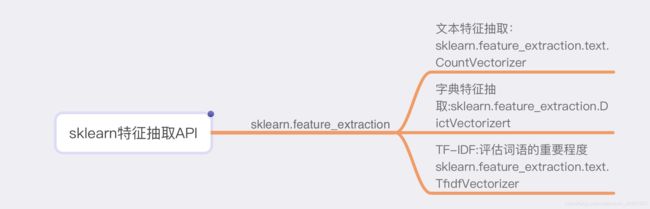
(一)字典特征抽取:
sklearn.feature_extraction.DictVectorizert

# 导入相关库
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Imputer
from sklearn.feature_selection import VarianceThreshold
from sklearn.decomposition import PCA
import jieba
import numpy as np
字典数据信息抽取
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
data = dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}])
print(dict.get_feature_names())
print(dict.inverse_transform(data))
print(data)
return None
运行结果:

- 定义一个信息抽取函数
- 调用 DictVectorizer() 实例化,返回结果赋给dict这个变量
- 调用fit_transform方法,传入字典,将返回值传给data
- 查看特征名 get_feature_names
- 查看转化后的值 inverse_transform
可以看出,程序把字典的值进行分类,再分别进行标记。这种方法叫one-hot编码,即为每个类别生成一个布尔列,这些列中只有一列可以为每个样本取1。

(二)文本信息抽取
sklearn.feature_extraction.text.CountVectorizer

1.英文文本信息处理
将莎士比亚十四行诗中的一句进行处理:
[‘so long as men can breath or eyes can see’,
‘so long lives this’,
'and this ',
‘gives life to thee’]
def countvec1():
"""英文文本处理"""
# 实例化CountVectorizer
vec = CountVectorizer()
# 调用fit_transform输入并转换数据
data = vec.fit_transform(
['so long as men can breath or eyes can see', 'so long lives this', 'and this ', 'gives life to thee'])
print(vec.get_feature_names())
# 注意返回格式,利用toarray()进行sparse矩阵转换array数组
print(data.toarray())
运行结果

- 首先实例化CountVectorizer
- 再调用fit_transform输入并转换数据
- 打印特性名称
- 转化为数组后打印结果
处理英文文本时,先将每个单词识别出来(单个字母不处理),再对每一行中每个单词出现的频率进行标记,从出现的频率可以看出重要程度。
2. 中文文本信息处理
def countvec():
"""
对文本进行特征值化
:return: None
"""
cv = CountVectorizer()
data = cv.fit_transform(["人生 苦短,我 喜欢 python", "人生漫长,不用 python"])
print(cv.get_feature_names())
print(data.toarray())
return None
对中文进行处理时,如果词语和词语之间没有空格,python就会把一句话当成一个词,则识别就没有意义。加上空格后才有意义。若识别万字文章,则需要jieba库来对词语进行切割。
def cutword():
con1 = jieba.cut("明月几时有,把酒问青天")
con2 = jieba.cut("不知天上宫阙,今夕是何年")
con3 = jieba.cut("我欲乘风归去,又恐琼楼玉宇")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 吧列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
运行结果

先打印出了c1 c2 c3,可以看出jieba.cut已经把句子用空格转化为了一个个字符串,再对中文进行处理。
将中文进行特征值化流程
1.准备句子,利用jieba.cut进行分词
2.实例化CountVectorizer
3.将分词结果变成字符串当作fit_transform的输入值
(三)TF-IDF
sklearn.feature_extraction.text.TfidfVectorizer
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。

此处仍然用上个库的数据:
def tfidfvec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2, c3])
print(tf.get_feature_names())
print(data.toarray())
return None
运行结果
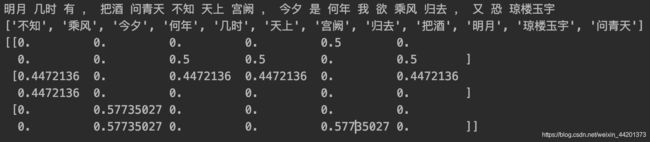
TF-IDF返回的是词组的权重矩阵,可以看出单个汉字也不进行标记。